CoT神話破滅,並非LLM標配!三大學府機構聯手證實,CoT僅在數學符號推理有用

新智元報導
編輯:桃子
【新智元導讀】CoT只對數學、符號推理才起作用,其他的任務幾乎沒什麼卵用!這是來自UT-Austin、霍普金斯、普林斯頓三大機構研究人員聯手,分析了100+篇論文14類任務得出的結論。看來,CoT並非是所有大模型標配。
GoogleCoT開山之作,再次成為OpenAI o1模型的利器。
LLM複雜推理能力的實現,就離不開一步一步思考,但是這種「思考」究竟對於什麼類型的任務有幫助呢?
來自UT-Austin、霍普金斯、普林斯頓的研究人員,使用CoT對100多篇論文,進行了定量元分析。
 論文地址:https://arxiv.org/abs/2409.12183
論文地址:https://arxiv.org/abs/2409.12183同時,他們還對14個模型的20個數據集,進行了評估。
結果顯示,CoT在涉及數學、邏輯任務中,能夠增強LLM性能,但在其他類型任務上,收益較小。

在MMLU中,除非問題或模型回答中包含「=」(表示符號運算和推理),否則直接生成答案,而不使用CoT,能達到與使用CoT相同的準確率。
基於這一發現,作者通過分離「規劃」和「執行」,並工具增強的LLM進行比較,來分析CoT在這些任務中的行為。
結果證實,CoT的大部分收益,來自於符號執行的改進,但相對於使用符號求解器來說,表現較差。

總而言之,作者希望通過研究告訴我們,CoT並非是萬能的。
「CoT可以有選擇性地應用,以平衡性能和推理計算成本」。
另外,未來研究中還需超越基於提示的CoT,轉向利用整個LLM中間計算的新範式。

用CoT,還是不用CoT,這是一個問題
o1成為當紅炸子雞,一大原因便是採用了CoT架構。
但是,千萬不要被OpenAI誤導了。

其實,先前就有研究稱,CoT在數學以外的領域,並沒有那麼有用,甚至有時會損害模型性能。
最新研究中,作者的目標是去評估,基於提示的CoT在哪些領域發揮作用最大,以及具體的原因。
110篇論文,14大類別
對此,研究人員從機器學習頂會ICLR 2024、兩個NLP頂會EACL 2024和NAACL 2024中,篩選了所有4642篇論文(2259篇來自ICLR 2024,2,382篇來自兩個ACL附屬會議)。
在這些論文中,通過自動篩選出現CoT、chain-of-thought或chain of thought兩次的文章,共得到516個樣本。
然後,下一步通過手動篩選,得到對「CoT提示與直接提示進行比較」的論文。
經過一系列排除,最終收集了110篇論文樣本,涵蓋了264個數據集。
最後,研究人員將所獲得樣本中的不同任務,分成14個類別。

 如下圖2所示,在不文獻中,作者發現CoT在任務分類中的性能增益。
如下圖2所示,在不文獻中,作者發現CoT在任務分類中的性能增益。可見,CoT在符號推理、數學、邏輯推理三大類別任務中,性能最優,平均提高分別為14.2%、12.3%和6.9%。
使用CoT的前三項任務,平均性能為56.9%,而沒有CoT的性能為45.5%。
對於其他類別任務,使用CoT的平均性能為56.8%,而沒有使用CoT的平均性能為56.1%。
 圖2右側顯示了,在數學、符號或邏輯推理以外的任務實驗中,平均CoT增量較高10個異常值。
圖2右側顯示了,在數學、符號或邏輯推理以外的任務實驗中,平均CoT增量較高10個異常值。雖然這些論文沒有被歸類為數學邏輯,但其中一些在某種程度上與邏輯、數學或符號推理相關。
從這個列表中可以看出,從CoT中獲益最多的數據集是BIG-bench Hard。還有BIG-bench Temporal、MMLU-Moral Scenarios都涉及到了基本簡單問題的組合。

同時,還有幾個異常值,也隱約遵循這一趨勢。比如,ScienceQ是由一系列自然和社會科學科學選擇題組成,但如果不按學科/問題類型細分成績,很難解釋其收益。
其次,在一些論文分析中,其他論文評分結果並未顯示出CoT帶來的改進。
實驗結果
更進一步的,團隊在零樣本學習和少樣本學習的設置下,對14個模型的20個數據集進行了一系列實驗,以比較性能。
與CoT相比,零樣本CoT有何改進?
如下圖3所示,具體顯示了圖1中,每個推理類別的平均CoT性能改進。右側呈現的是,對每個數據集使用CoT所帶來的性能增益,這是所有模型和單個模型選擇的平均值。
在非符號推理類別和數據集上,特別是那些包含主要涉及常識(CSOA、PIOA、SiOA)、語言理解(WinoGrande)和閱讀理解((AGILSAT、ARC-Easy、ARC-Challenge)問題的數據集。
零樣本CoT和零樣本直接回答的性能之間,幾乎沒有區別。
儘管這些數據集中涉及推理,但是CoT並沒有帶來顯著的改進。
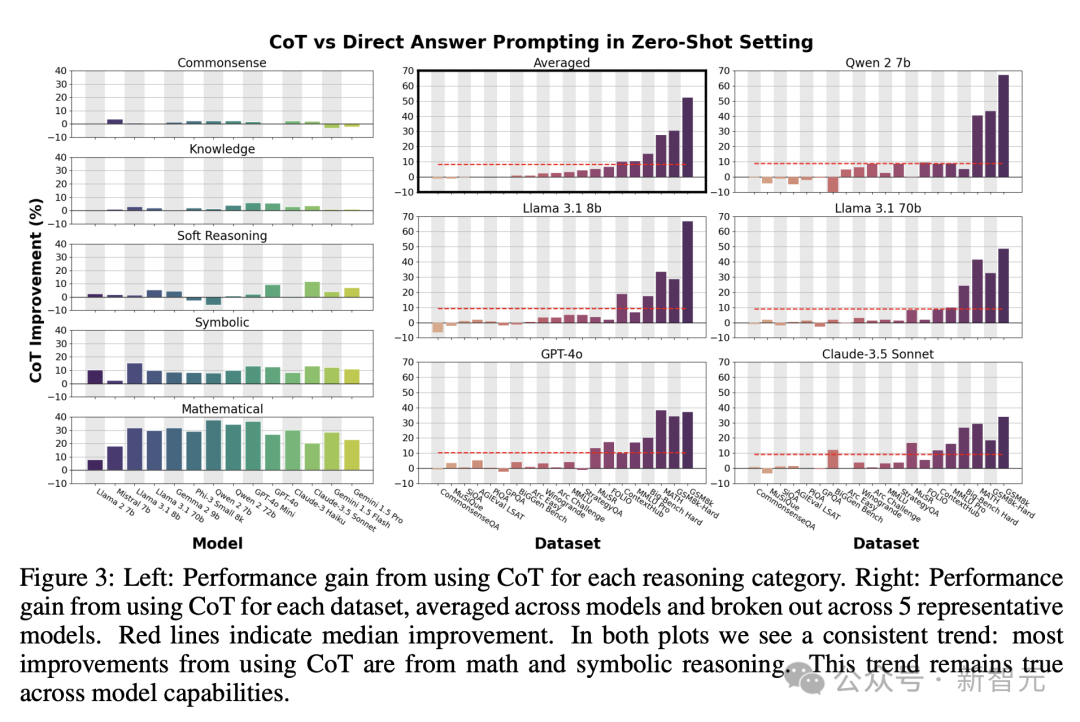
相較之下,數學和符號類別,與符號和許多符號數據集一起得到了大幅改進。
MATH和GSM8k的增幅分別高達41.6%和66.9%。對於半符號數據集如Mvsteries等,結果顯示出適度的增幅。
例如,從簡單的自然語言(ContextHub)或更複雜的常識陳述(MuSR 謀殺之謎)解析出一階邏輯。所有結果均顯示在附錄 C.1中,表7中還顯示了 CoT 和直接答案提示的完整數字結果列表。我們還探索了少數鏡頭設置,發現它對 CoT 何時提供幫助的影響不大;參見附錄 B。
答案形式,是否會影響到CoT幫助的範圍?
答案——不多,預先規劃或推理正確反應,可能會阻礙模型自主反應能力。
除了數學之外,許多常用的問題數據集是多項選擇。
對於兩個非多項選擇,且包含不同級別的非符號推理來回答問題數據集,CoT具有與跨模型直接回答相似的性能。
其次,BiGGen Bench使用自由式回答作為問題答案,並使用LLM作為法官,以1-5級來評估這些回答。
得到的答案,本質上模糊了CoT和直接答案之間的界限。
為此,研究人員設置了一個新的CoT提示,要求語言模型生成自由形式響應的規劃,然後要求其在生成完整的響應。
知識、軟推理和常識方面,性能提升顯著嗎?
除了MMLU、StrategyQA和MuSR外,大多數情況下答案是否定的。
作者使用配對引導法在知識、軟推理和常識推理類別的13個數據集上,測試了CoT改進的顯著性。
結果得出,大約 38%的數據集顯示出,這三個推理類別的效益是顯著的。
MMLU和MMLU PRO
MMLU和MMLU Pro顯示了,使用CoT帶來收益,但由於這些數據集非常廣泛,因此無法進行簡單的表徵。
研究人員探索了MMLU每個類別上的CoT性能,以瞭解這些領域之間CoT性能的差異。
對此,他們列出了3個類別,其中CoT在MMLU和MMLU Pro上,Llama 3.1 8B和70B最大的誤差減少。
 其中,一些任務類別明顯是數學性質,正如圖8中所呈現的那樣。
其中,一些任務類別明顯是數學性質,正如圖8中所呈現的那樣。此外,我們還可以看到,CoT在商業任務上,能夠提供一定的幫助。經過仔細核查,這些任務也會常常涉及數學等一些內容。
 實驗結果如下圖4所示,當問題或生成結果彙總包含「=」,以及不包含「=」時,使用CoT時的增益效果。
實驗結果如下圖4所示,當問題或生成結果彙總包含「=」,以及不包含「=」時,使用CoT時的增益效果。
CoT在公式推理中的優缺點
前面主要說明了CoT主要在符號推理任務發揮作用,但沒有說明具體原因。
在符號任務上,研究人員CoT的性能提升歸因於兩個階段:規劃階段和執行階段。
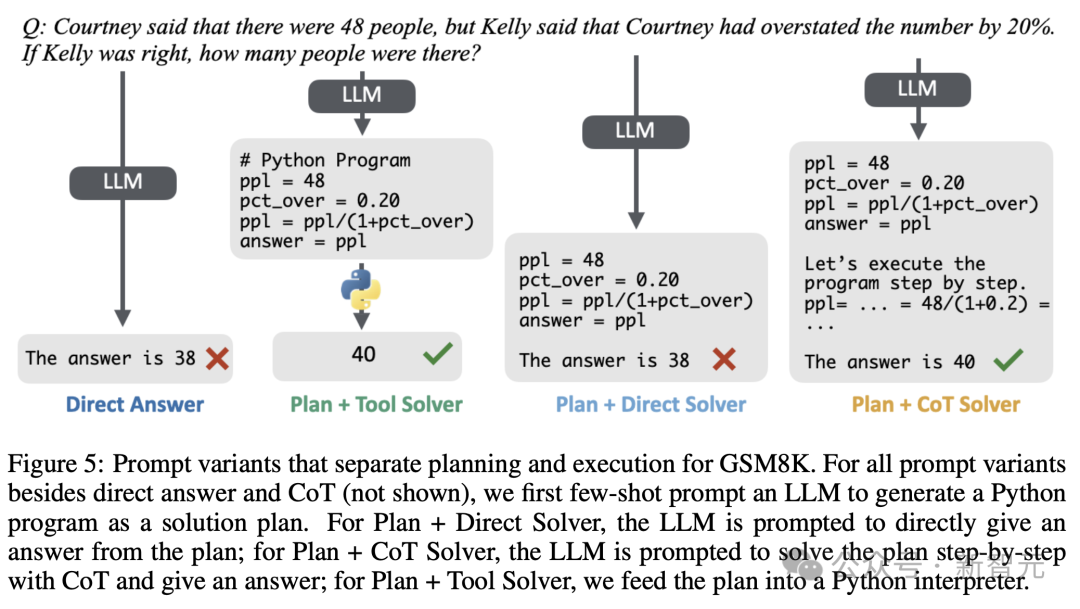 下圖6顯示了,代表性模型選擇的結果。
下圖6顯示了,代表性模型選擇的結果。將直接答案與Plan+ Direct求解器和Plan+CoT求解器進行比較時,可以注意到,對於許多數據集和模型,僅有規劃並不能解決大部分性能增益。
與直接答案相比,需要CoT或Plan+CoT求解器,來獲得強大的性能。
儘管CoT和Plan+CoT求解器,比直接答案和Plan+Direct求解器有優勢,但在大多數設置中,仍以Plan+Tool求解器為主。
與符號求解器相比,LLM執行和追蹤步驟的能力受到限制。

鑒於以上的發現,研究團隊認為CoT應該有選擇性地應用,尤其是在需要處理數學、邏輯推理的任務。
而不分青紅皂白地使用CoT,可能會導致推理成本增加。
他們還建議,若想進一步提升模型推理能力,還需要超越基於提示的CoT。
總而言之,CoT is not all you need。
 參考資料:
參考資料:https://arxiv.org/abs/2409.12183



















