一行代碼訓練成本再降30%,AI大模型混合精度訓練再升級|開源
允中 發自 凹非寺
量子位 | 公眾號 QbitAI
FP8通過其獨特的數值表示方式,能夠在保持一定精度的同時,在大模型訓練中提高訓練速度、節省內存佔用,最終降低訓練成本。
AI大模型開發系統Colossal-AI的混合精度訓練再度升級,支持主流的BF16(O2) + FP8(O1)的新一代混合精度訓練方案。
僅需一行代碼,即可對主流LLM模型能夠獲得平均30%的加速效果,降低相應大模型開發成本,並保證訓練收斂性。
無需引入額外的手寫CUDA算子,避免了較長的AOT編譯時間和複雜的編譯環境配置。
開源地址:https://github.com/hpcaitech/ColossalAI
FP8混合精度訓練
低精度計算一直是GPU硬件發展趨勢。
從最早的FP32,到目前通用的FP16/BF16,再到Hopper系列芯片(H100, H200, H800等)支持的FP8,低精度計算速度越來越快,所需的內存也越來越低,非常符合大模型時代對硬件的需求。
目前FP8混合精度訓練影響訓練結果的最大因素就是scaling方案,常見的方案有兩種:
-
延遲scaling
-
實時scaling
延遲scaling採用之前一段時間窗口內的scaling值來估計當前scaling,同時將scaling的更新和矩陣乘法(gemm)融合起來。這種計算方法效率較高,但由於是估算的scaling,所以對收斂性影響較大。
實時scaling直接採用當前的張量值來計算scaling,所以計算效率較低,但是對收斂性影響較小。根據英偉達的報告,這兩種scaling方案的計算效率差距在10%以內。
Colossal-AI採用了對訓練收斂性影響較小的實時scaling方案,同時實現有著不輸其他延遲scaling實現的性能。
在單卡H100上對矩陣乘法進行的測試,可以看到矩陣的維度越大,FP8的加速效果越明顯,而且Colossal-AI的實現與Transformer Engine的性能幾乎一致,如圖1所示。但Transformer Engine需要複雜的AOT編譯環境配置和較長的編譯時間。
 △圖1. 單卡GEMM性能測試
△圖1. 單卡GEMM性能測試為了實驗結果更貼近現實,Colossal-AI直接在主流LLM上進行了實際訓練的測試。
首先在H100單卡上進行了測試,以下測試中Transformer Engine (TE)採用的其預設的延遲scaling方案。

 同時進行了收斂性測試,可以看到FP8混合精度訓練的loss曲線與bf16的基本一致,如圖4所示:
同時進行了收斂性測試,可以看到FP8混合精度訓練的loss曲線與bf16的基本一致,如圖4所示: △
△圖4. H100單卡 LLaMA2-7B 混合精度訓練loss曲線
Colossal-AI還測試了H800多卡並行訓練場景下的性能。在單機8卡H800上訓練LLaMA2-7B,Colossal-AI FP8對比Colossal-AI BF16有35%的吞吐提升,對比Torch FSDP BF16有94%的吞吐提升。

在單機8卡H800上訓練LLaMA2-13B,Colossal-AI FP8對比Colossal-AI BF16有39%的吞吐提升。

在2機16卡H800上訓練Cohere Command-R 35B,Colossal-AI FP8對比Colossal-AI BF16有10%的吞吐提升,如圖7所示:
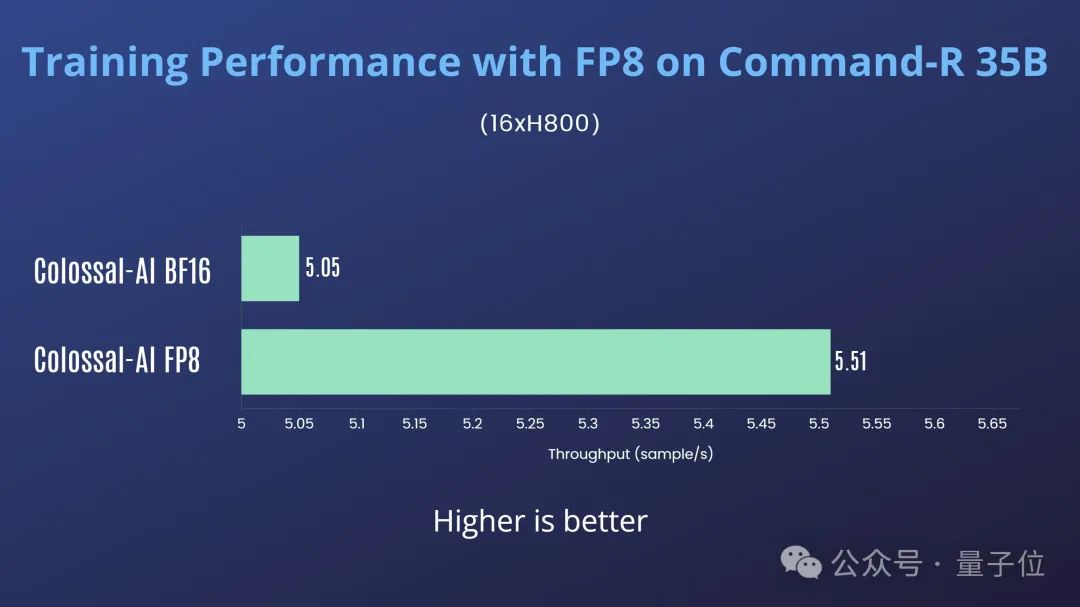
根據英偉達的報告和測試經驗,對FP8混合精度訓練性能調優有一些初步的認識:
-
儘量少使用張量並行,用流水線並行代替張量並行
-
模型hidden size越大,加速效果越明顯
-
矩陣乘法佔比高的模型加速效果大
由於上述實驗中Command-R 35B採用了張量並行,所以加速效果不太明顯。
Colossal-AI對FP8的支持較為廣泛,各種並行方式都能和FP8混合精度訓練兼容。使用時,僅需在初始化plugin時開啟FP8即可:
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin...plugin = LowLevelZeroPlugin(..., use_fp8=True)plugin = GeminiPlugin(..., use_fp8=True)plugin = HybridParallelPlugin(..., use_fp8=True)
除此之外,無需多餘的代碼和AOT編譯。
開源地址:https://github.com/hpcaitech/ColossalAI
*本文系量子位獲授權刊載,觀點僅為作者所有。



















