666條數據教會AI寫萬字長文!模型數據集都開源
魔搭ModelScope團隊 投稿
量子位 | 公眾號 QbitAI
僅需600多條數據,就能訓練自己的長輸出模型了?!
事情是醬嬸兒的——
雖然大模型的上下文(Context)支持越來越長,但包括GPT-4o,Llama-3.1-70B,Claude 3.5 Sonnet在內的這些業界領先模型,在用戶指定所需輸出長度的情況下,其最大輸出長度仍無法滿足要求。
例如,針對「寫一篇關於羅馬帝國歷史的10000字文章」的要求,所有這些通用模型在輸出長度上均無法超過2000字。
對此,基於GLM4-9B,智譜通過構建長輸出的訓練數據得到了LongWriter-GLM4-9B模型,能夠應對超長輸出(10000+ words)場景。
與此同時,智譜開源了訓練該模型所需的長輸出文本數據集LongWriter-6K。
現在,魔搭社區上基於LongWriter-6K過濾精選了666條數據(LongWriter-6K-Filtered),也一併開源了。
有什麼用??
一句話,使用該數據集,你就能在自己的模型中集成長輸出能力了。

LongWriter數據生成與模型訓練
通過分析訓練SFT數據,團隊發現對於「模型無法輸出較長文本」的一個合理解釋為:
模型所能生成的最大長度,會受限於其SFT數據中存在的輸出長度上限。
以GLM4-9B-Chat模型為例,其SFT訓練使用的180K條chat數據中,輸出長度超過500、1,000和2,000字的數據,分別僅佔SFT數據量大的28%、2%和0.1%。
可見,長輸出長度的訓練數據佔比較小,而2000字長度以上的數據樣本佔比更是微乎其微。
有了這個分析,LongWriter-GLM-9B是智譜基於GLM4-9B模型,通過構建長輸出的訓練數據而得到的模型,在輸出長文方面表現突出。
在LongWriter工作的基礎上,團隊利用社區的Swift微調訓練工具和EvalScope評估框架,進一步探索了在擴展模型輸出長度這個任務上,高質量數據對於模型質量的重要性。
同時,將這個模型訓練的receipt,擴展到其他模型(例如Qwen2)上。
在這個過程中,團隊還分享了一些有趣的發現和實踐經驗:
a)少即是多:數據質量比數據數量更關鍵。
通過對數據的分析過濾,團隊發現LongWriter-6K的6000條數據,依然存在優化空間。
他們從中選出了10%左右(666條)的高質量數據並基於這些數據做微調訓練。
在Qwen2-7b-instruct和GLM4-9B-Chat兩個模型上,只需要3.7%訓練計算消耗,就能獲取和原論文中,LongWriter-GLM-9B類似的性能提升。
此外,隨著基礎模型的升級,支持長輸出這個能力,在新迭代中本身也會有所增強。但LongWriter的技術方案,還是有其適用性。例如在新鮮出爐的Qwen2.5模型上,團隊通過第一時間的測試和驗證發現,一方面Qwen2.5模型本身在文本生成長度上,已經有了長足進步,但同樣的訓練微調方案,還是能進一步帶來很好的任務能力提升。
b)對於提升輸出文本長度這個具體任務,從base模型開始SFT似乎不是必須的。
以對齊版本(chat/instruct)模型為起點,在模型輸出質量和輸出長度兩方面,也都能獲取較好的效果。
下面來看團隊對數據的處理。
LongWriter-6K數據
LongWriter-6K數據是通過AgentWriter生成,也就是將長文寫作任務分解為多個子任務,每個子任務負責撰寫一段。
實驗發現,在GPT-4o上使用AgentWriter策略,能夠得到近乎線性的Output Length,且長度遠超2000詞,甚至可以達到30000詞的量級。

LongWriter-6K數據集由6000條」Required Length」超過2000字的用戶指令構成,來自於GLM-4的SFT數據,其中大部分為中文。
另外,從WildChat中選擇了3000條指令,主要為英文。
在這個基礎上,使用GPT-4o過濾掉有毒數據並人工檢查了自動選擇的指令。
最後,利用AgentWrite生成與這些instruction對應的response。
 △LongWriter訓練數據輸出長度分佈
△LongWriter訓練數據輸出長度分佈LongWriter模型訓練與評估
LongWriter-GLM4-9B模型訓練使用GLM4-9B作為基模,將LongWriter-6k與180k的GLM-4通用chat SFT數據結合,形成整個訓練集。
LongWriter-6k有效補充了輸出長度超過2k字的通用chat SFT 數據的稀缺性,且LongWriter-6k的輸出長度在2k-10k之間的分佈相對均勻。
評價指標
針對輸出長文本任務,LongWriter模型採用兩個指標:
-
輸出長度(SL)評分
-
輸出質量(SQ)評分
為了讓模型的輸出長度儘可能接近指令中規定的要求,使用了分段線性函數來計算輸出長度得分(SL):

輸出質量SQ則使用GPT-4o,從以下6個維度來評價:
-
Relevance,相關性
-
Accuracy,準確性
-
Coherence,連貫性
-
Clarity,清晰度
-
Breadth and Depth,廣度和深度
-
Reading Experience,閱讀體驗
每個維度分值為1到5中的整數,最低分1,最高分5;最後6個維度整體求平均,並縮放到100分。
訓練4個epoch,大約需要 2,500-3,000 step。
實驗結果

 △LongWriter實驗結果
△LongWriter實驗結果可以看到,LongWriter-9B相較於GLM4-9B-Chat,Overall絕對提升12.2個百分點(68.3->80.5),同時再疊加DPO訓練,可以有進一步3.5個點的提升。
從LongWriter-6k到LongWrier-6k-filtered:數據質量提升
通過觀察LongWriter-6k數據集,團隊發現針對任務的評估標準,這個數據集中仍然有較多的數據並不完全符合目標任務的要求。
例如,大量樣本中,對輸出長度沒有明確要求(「Required Length」):
{"messages": [{"role": "user", "content": "請寫一篇關於山東大學外國語學院創收情況的調研報告,創收主要渠道有組織四六級筆試閱卷及口語考試閱卷"},{"role": "assistant", "content": "### 山東大學外國語學院... "}]}
實際輸出長度(Response Length),與prompt要求的長度(Required Length)差距較大,例如:
{"messages": [{"role": "user", "content": "你是一位優秀的辯手,請針對以下辯題,給出觀點立論:\n辯題:當代大學生是否應該住校\n立論角度:闡述不住校的好處\n立論要點:運用數據、事例等論證住校的必要性;從鍛鍊獨立能力、培養社交技巧等方面論證觀點\n內容要求:表達清晰,論點突出,精闢見解,讓人信服 20000字"}, {"role": "assistant", "content": "### 引言:住校與否的辯論\n\n大學生活是每個青少年成長過程中的關鍵階段,而當代大學生是否應該住校則成為一個備受爭議的話題, ..."}], "length": 20000, "response_length": 7739}
——其Required Length為20000,但輸出為7739
此外還有不少數據,由於輸入內容被模型直接拒答,導致輸出長度極短,對於整體數據質量有較大的汙染。
鑒於這些數據對於目標任務可能造成的反作用,團隊在LongWriter-6k數據基礎上,實施了兩個數據清洗剔除策略。
策略1
-
剔除prompt中對輸出長度沒有明確要求(Required Length)的數據
-
數據總量:6000條 → 1748條
策略2
-
剔除輸出長度和prompt中的Required Length差距較大的數據,即eval_length score—SL得分小於80分的數據
-
數據總量:1748條 → 666條
 △
△策略1過濾後 vs 策略2過濾後的數據特性
可以看到,在經過兩輪策略過濾後的數據,其實際Output Length體現了對於Required Length非常好的遵循能力,整體數據樣本長度關聯接近線性。
這樣經過對LongWriter-6k數據極限「壓榨」,最終得到了包含666條經過清洗後的LongWrier-6k-filtered數據集,並開源在ModelScope。
基於這個新的LongWrier-6k-filtered數據集,下面開始探索:
這些「少而精」的數據,是否能訓練出效果相當甚至更為出色LongWriter模型。
基於不同數據集和模型的LongWriter微調
為了驗證「通過基礎長輸出文本數據,以及精選的輸出長度遵循數據,來調教基礎模型的長文寫作能力」這一方案的通用性,團隊選擇了Qwen2和GLM4模型來驗證上述假設。
同時團隊認為,對於長文本寫作這一任務,人類對齊過的chat或instruct模型已經提供了一個較好的基準,故可能不需要完全base模型並帶上全量的chat SFT數據開始訓練。
所以團隊分別選用了Qwen2-7b-instruct和GLM4-9B-Chat模型作為訓練的基準模型。
當然還有一個原因是,團隊確實也沒有Qwen2或GLM4的完整SFT數據(doge)。
在不同的實驗里,團隊選用的數據集,除了LongWrier-6k和LongWrier-6k-filtered之外,還包括了:
Qwen2-72B-Instruct生成並經過篩選的200k中文以及英文對話數據集Magpie-Qwen2-Pro-200K-Chinese和Magpie-Qwen2-Pro-200K-English。
在loss函數的選擇方面,使用了「long-ce」loss函數,這與原始LongWriter文章中採用的策略相同:
為避免長輸出數據中每個target token對損失的貢獻低於短輸出的問題,long-ce loss通過計算該批次中所有target token的average loss來獲得。
基於ModelScope Swift項目提供的多數據集混合能力,數據混合的訓練微調都可以通過一個命令行完成。
例如,如下命令完成的是將longwriter-6k-filtered、Qwen2-Pro-200K-Chinese和Qwen2-Pro-200K-English三個數據集抽樣後按自定義混合(包括隨機抽樣)策略,使用long-ce loss來進行SFT:
swift sft \--model_type qwen2-7b-instruct \--dataset longwriter-6k-filtered qwen2-pro-zh#6660 qwen2-pro-en#6660 \--max_length 28672 \--num_train_epochs 2 \--eval_steps 200 \--batch_size 1 \--gradient_accumulation_steps 64 \--gradient_checkpointing true \--warmup_ratio 0.1 \--learning_rate 1e-5 \--sft_type full \--loss_name long-ce \--check_dataset_strategy warning \--save_only_model false \--save_total_limit -1 \--lazy_tokenize true \--dataloader_num_workers 1 \--resume_only_model true \--neftune_noise_alpha 5 \--use_flash_attn true
同時遵照LongWriter paper定義的輸出長度(SL)和 輸出質量(SQ)評分,可以基於EvalScope框架來進行相關評測。
在評測過程中,對於模型推理的配置為repetition_penalty=1.1, temperature=0.5。
LongWriter評測:
# pip install evalscope[framework]# 配置任務# `infer`--推理階段;`eval_l`--length分數評估;`eval_q`:quality分數評估task_cfg = dict(stage=['infer', 'eval_l', 'eval_q'],model='ZhipuAI/LongWriter-glm4-9b',input_data_path=None,output_dir='./outputs',openai_api_key=None,openai_gpt_model='gpt-4o-2024-05-13',infer_generation_kwargs={'max_new_tokens': 32768,'temperature': 0.5},eval_generation_kwargs={'max_new_tokens': 1024,'temperature': 0.5,'stop': None},proc_num=8)# 提交評測from evalscope.third_party.longbench_write import run_taskrun_task(task_cfg=task_cfg)
訓練配置
-
硬件環境:NVIDIA A100 x 4
-
初始學習率:1e-5
-
batch size:1,開啟梯度累加
模型效果評估
基於Qwen2-7b-instruct
團隊首先使用Qwen2-7b-instruct作為基礎模型,來微調生成LongWriter模型。實驗設計如下:

通過上述實驗可以看出,針對遵循指令進行長文本寫作這個任務,使用「少而精」的數據,對於模型最終的性能至關重要。
事實上,在實驗3中,只通過LongWriter-6k-filtered數據集4個epoch訓練,總共2.6K條數據,其訓練出來的模型,無論在寫作長度,還是寫作質量上,都顯著優於LongWriter-6k + 180k的通用數據混合訓練的模型。
同時,在實驗3使用的LongWriter-6k-filtered數據集基礎上,實驗4再添加1:20混合的通用數據集,總共13.6K數據訓練2個epoch,能進一步獲得更好的結果。
Qwen2-7b-instruct的這個結果,也驗證了使用LongWriter-6k-filtered數據集來微調長文本寫作能力,具有一定的通用性,不只局限於GLM4系列模型。
此外,如同LongWriter論文里展示的一樣,在寫作質量方面,增強了長文本能力的模型,在質量上有小幅度的波動(-1.47點)。
在這些實驗里,最終選擇了實驗4產出的模型作為MS-LongWriter-Qwen2-7b-instruct,並開源到ModelScope。
圖6展示了訓練定製前後的模型,在輸出文本遵循指定長度方面的對比。可以看到,訓練後的模型的文本輸出長度,能更好的貼合prompt的要求,特別是在要求輸出的文本長度較長的時候。
基於GLM4-9b-Chat
接下來,團隊把LongWriter-6k-filtered數據集,以及對應微調定製模型的方法(也就是上述實驗4的配置),也以GLM4-9b-Chat模型作為基座進行了定製訓練,並且與LongWriter-GLM4-9B結果做了對比。
如下表所示:

可以看到基於實驗4的配置,使用GLM4-9b-Chat作為基礎,總共使用了13.6K數據,訓練2 epoch;而原始LongWriter-GLM4-9B使用186K數據,訓練4 epoch。
實驗4訓練用的總數據量在僅為原始LongWriter-GLM4-9B訓練使用數據量7.5%(實際消耗計算資源為3.7%)的情況下,獲取了類似的效果。
當然這裏一個顯著的區分點,是團隊是以GLM4-9b-Chat作為訓練的基礎。
考慮到原始論文中使用的是GLM4-9b base模型作為基座,客觀上確實需要更多通用對齊數據集。
但如同之前討論的,對於遵循指令進行長文本寫作這個具體任務,從base模型開始訓練可能並不必要。
在這些實驗里,最終選擇了實驗4產出的模型作為MS-LongWriter-GLM4-9B-Chat,並開源到ModelScope。
基於Qwen2.5-7b-instruct
在團隊的這個探索接近尾聲之時,Qwen模型家族正式推出Qwen2.5系列。
相比Qwen2系列,Qwen2.5支持的輸出長度有了較大的提升。團隊也在第一時間基於Qwen2.5-7B-Instruct模型做了初步的實驗,結果如下:
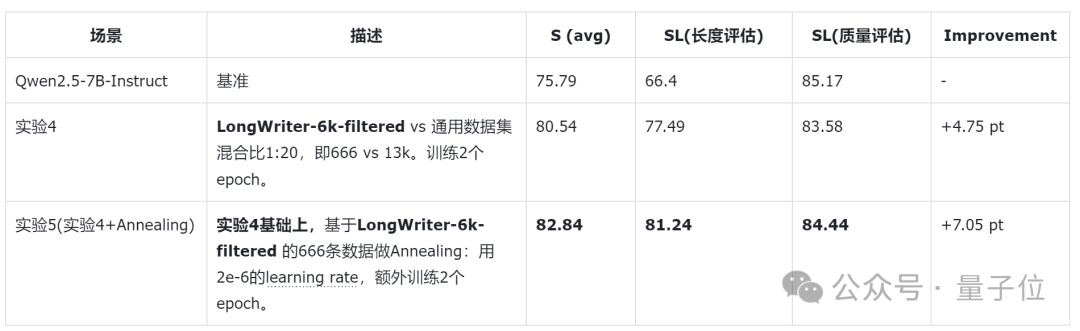
對比上述表格,可以清晰看到,未經定製的Qwen2.5-7B-Instruct模型在遵循指令進行長文本寫作的輸出長度(SL)方面的評分,無論是對比Qwen2-7B-Instruct,還是GLM4-9b-Chat,都已經有了較大的提升。
而通過實驗4的13.6K條數據2個epoch的定製訓練,模型綜合指標(S-avg)就已經達到達到最佳。在這個基礎上,額外進行了基於LongWriter-6k-filtered 666 條數據的2個epoch退火訓練,則在SL, SQ和S-avg幾個指標上都全面超越了其他測試模型。
其中具體實驗5的退火(annealing)訓練的命令行如下:
CUDA_VISIBLE_DEVICES=0,1,2,3 nohup swift sft \--model_type qwen2_5-7b-instruct \--dataset longwriter-6k-filtered#666 \--max_length 28672 \--num_train_epochs 2 \--eval_steps 200 \--batch_size 1 \--gradient_accumulation_steps 64 \--gradient_checkpointing true \--warmup_ratio 0.1 \--learning_rate 2e-6 \--sft_type full \--loss_name long-ce \--check_dataset_strategy warning \--save_only_model false \--save_total_limit -1 \--lazy_tokenize true \--dataloader_num_workers 1 \--resume_only_model true \--neftune_noise_alpha 5 \--use_flash_attn true \--resume_from_checkpoint {previous-checkpoint-path} > {output-checkpoint-path}
最終採取實驗5的產出模型,作為MS-LongWriter-Qwen2.5-7B-Instruct開源到了ModelScope。
微調對於基礎能力的影響
最後,為評估針對遵循指令進行長文本寫作任務定製的模型,在基礎能力上是否存在退化,在mmlu、ceval、ARC_c、gsm8k上,使用EvalScope對於MS-LongWriter-Qwen2-7b-instruct進行了評估。
通過swift接口與EvalScope的對接,可以一鍵完成模型部署,推理和評估流程。
例如可以通過如下命令,完成對於Qwen2-7b-instruct的基礎能力評估:
CUDA_VISIBLE_DEVCIES=0 swift eval --model_type qwen2-7b-instruct --eval_dataset mmlu ceval ARC_c gsm8k比較幾個模型在基礎benchamrk上的得分,結果如下:
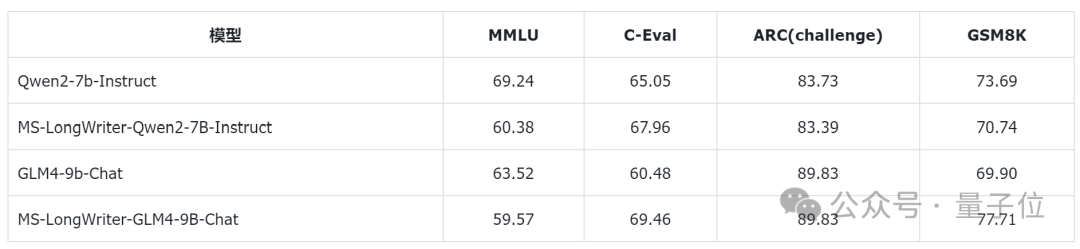
可以看到,針對遵循指令進行長文本寫作任務定製微調的模型,除了在ceval上有一些提升,在其他通用任務,尤其是偏邏輯推理的benchmark上,能力還是會有一定的regression,例如在MMLU上的掉點是較為明顯的。
結論
總體來看,多種證據表明,針對遵循指令進行長文本寫作這個任務,要來訓練定製模型,訓練數據的質量,會比數量更加重要。
且在這個任務上,可能從對齊的chat或instruct模型開始訓練,會比從未對齊的base模型開始訓練更加經濟。
在這個最佳實踐中,得益於ModelScope Swift訓練工具和EvalScope評估工具,團隊很方便的進行了各種不同的對比實驗。
本文中使用到的開源工具包括:
-
模型訓練微調框架:MS-Swift
-
模型評估工具:EvalScope
並且通過基於chat和instruct模型作為起點,只使用相比原始LongWrite訓練所需的3.7%的數據和計算消耗,就在Qwen2-7b-instruct和GLM4-9b-Chat上,在長文本撰寫任務上都獲得了和原paper里幾乎一致的效果提升(12pt左右)。
而在Qwen2.5-7b-instruct本身提供了較好長文本輸出能力的基礎上,通過同樣少量高質量數據的訓練定製,在這個任務上,能全方位獲得最佳的效果。
團隊訓練使用的數據,以及最後輸出的模型,目前都開源到了ModelScope。
參考資料:
1、LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs, Bai et al. 2024
2、Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing, Xu et al. 2024
3、LIMA: Less Is More for Alignment, Zhou et al. 2023
4、InstructionGPT-4: A 200-Instruction Paradigm for Fine-Tuning MiniGPT-4, Wei et al. 2023
5、Qwen2 Technical Report, Yang et al. 2024
6、ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools, ZhipuAI 2024
文中使用到的開源工具框架:
模型訓練微調框架MS-Swift:https://github.com/modelscope/ms-swift
模型評估工具EvalScope:https://github.com/modelscope/evalscope/
精篩後的666條數據集構成的LongWriter-6K-Filtered數據集:
https://www.modelscope.cn/datasets/swift/longwriter-6k-filtered
訓練微調後開源的長文本模型:
MS-LongWriter-Qwen2.5-7b-instruct:
https://www.modelscope.cn/models/swift/MS-LongWriter-Qwen2.5-7B-Instruct
MS-LongWriter-Qwen2-7b-instruct:
https://www.modelscope.cn/models/swift/MS-LongWriter-Qwen2-7B-Instruct
MS-LongWriter-GLM4-9B-Chat:
https://www.modelscope.cn/models/swift/MS-LongWriter-GLM4-9B-Chat
原始開源的LongWriter-GLM4-9B模型:
https://www.modelscope.cn/models/ZhipuAI/LongWriter-glm4-9b
其他相關數據集
WildChat:
https://www.modelscope.cn/datasets/thomas/WildChat
Magpie-Qwen2-Pro-200K-Chinese:
https://modelscope.cn/datasets/AI-ModelScope/Magpie-Qwen2-Pro-200K-Chinese
Magpie-Qwen2-Pro-200K-English:
https://modelscope.cn/datasets/AI-ModelScope/Magpie-Qwen2-Pro-200K-English