Ilya預言錯了,華人Nature一作給RLHF「判死刑」,全球大模型都不可靠

【導讀】Ilya兩年前觀點,竟被Nature論文反駁了!來自劍橋大學等團隊最新研究發現,所有大模型並不可靠,包括最強o1。
2022年,AI大牛Ilya Sutskever曾預測:「隨著時間推移,人類預期和AI實際表現差異可能會縮小」。
然而,一篇最新發表在Nature上的研究表明,事實並非如此!
世界上所有的大模型,甚至指令微調後的LLM,竟是一個「巨大的草台班子」。

論文地址:https://www.nature.com/articles/s41586-024-07930-y
來自VRAIN、劍橋等機構研究人員對o1-preview等領先的LLM開啟了全方位評測,結果發現:
– LLM&人類無法保持一致:人類認為複雜的任務,LLM輕易解決;而對人類小菜一碟的問題,LLM卻失敗了。
– LLM不會「迴避」複雜任務,而是強撐面子費力思考半天,最終仍舊答錯。
– 提示工程,無法挽救LLM的不可靠。
且看CoT「推理王者」o1-preview,既能解決非常複雜的字謎任務,卻在超級簡單的任務中犯錯。

 (上)根據所給字母,成功拚出了electroluminescence(電場發光);(下)回答錯誤,正確答案是yummy
(上)根據所給字母,成功拚出了electroluminescence(電場發光);(下)回答錯誤,正確答案是yummy 而且,在更具挑戰性任務上,o1-mini和o1-preview實際上根本不會做。
但為了給一個答案,它們往往耗時50-140多秒,絞盡腦汁去想半天。

結果,還是在所有任務中,都失敗了。

 o1-mini在思考103秒之後,仍舊計算錯誤
o1-mini在思考103秒之後,仍舊計算錯誤 要知道,o1系列模型最強大之處在於,使用RL+CoT等策略,實現推理能力暴漲。
就連o1都這麼不可靠,Claude、Llama等大模型更是如此。
LLM並不可靠
更大參數、更大數據、更長訓練時間,外加RLHF、輸出過濾審核等技術加持,LLM肉眼可見地性能提升。
而且,以人類視角來看,它們也變得越來越可靠。
但事實上,這僅是一種表象。
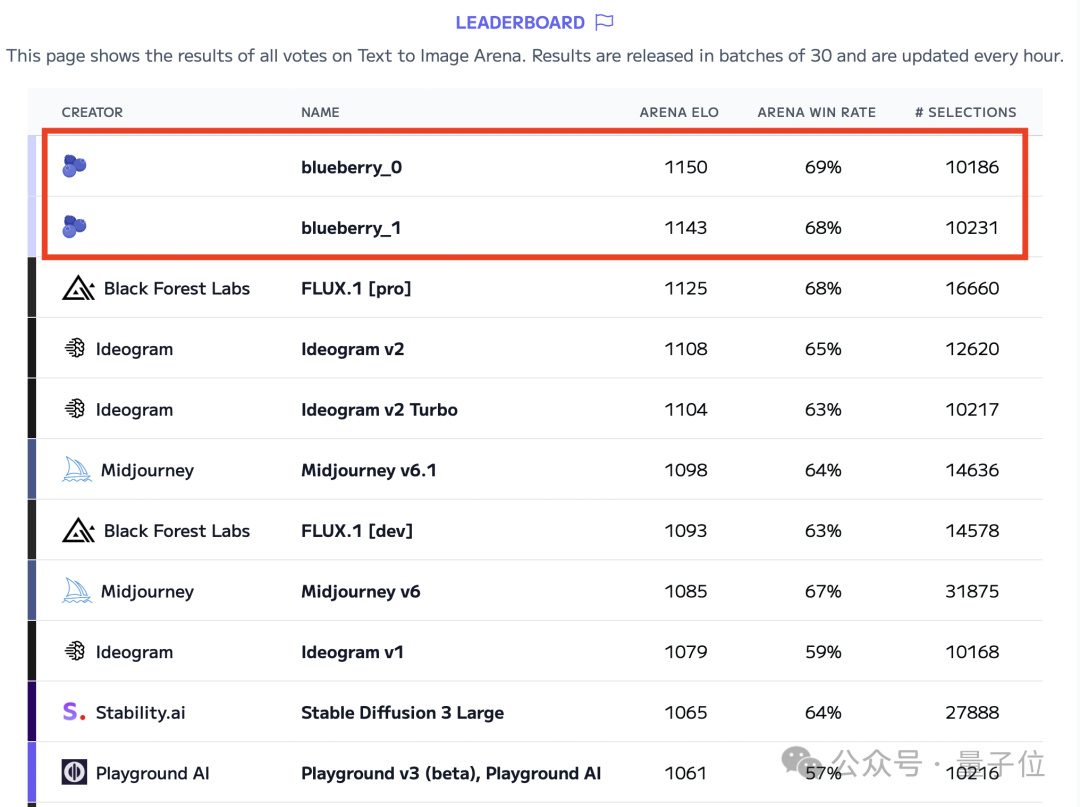
為了評測當前LLM可靠性,劍橋等機構研究人員將GPT系列、Llama系列、以及Bloom系列32個模型,展開評測。
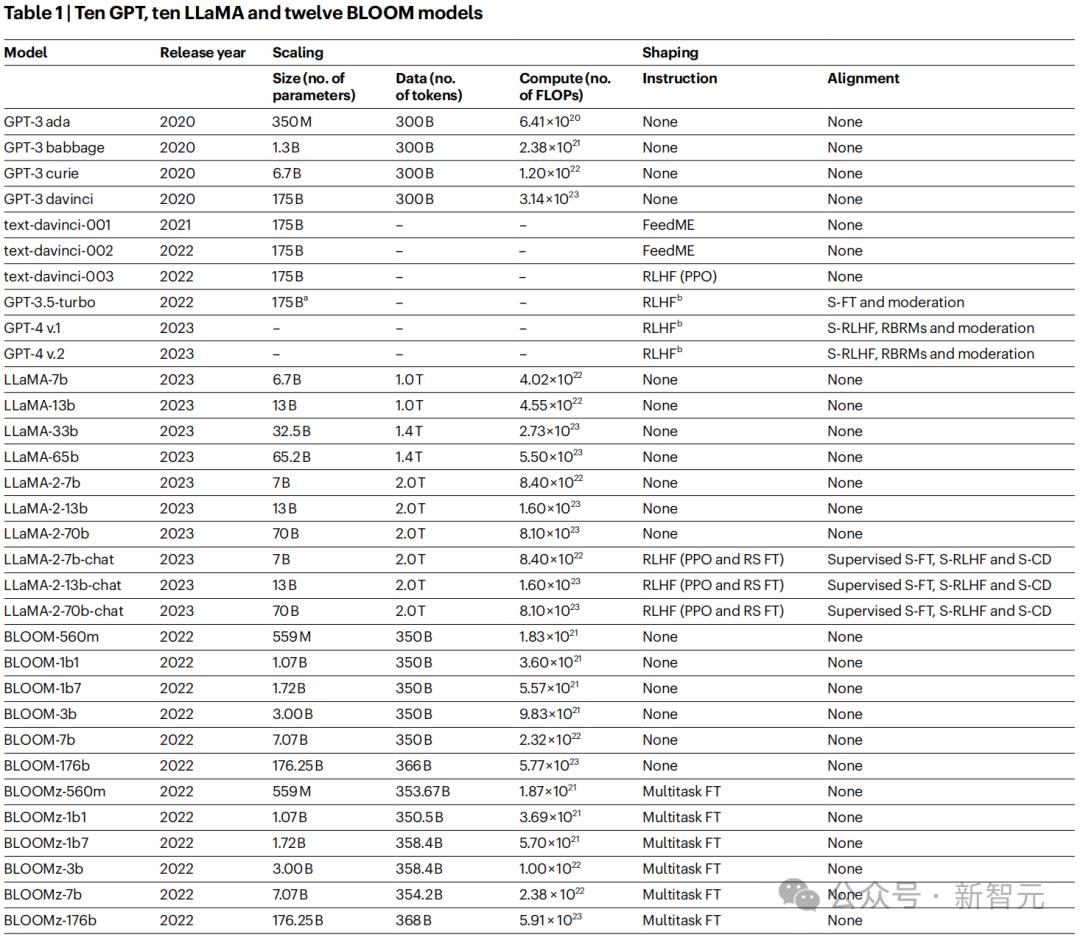 之所以選擇這些模型,是因為它們代表了不同參數規模,並使用RLHF等方法優化的模型
之所以選擇這些模型,是因為它們代表了不同參數規模,並使用RLHF等方法優化的模型 正如開篇所述,他們從三個方面對此,展開了評測。
1. 難度(不)一致性
2. 任務迴避
3. 提示敏感性和穩定性
複雜任務一舉攻破,簡單任務錯誤百出
難度一致性上,不得不得承認,LLM確實在人類認為困難的任務上,回答準確率較低。
而奇怪的發現是,它們在還沒有完全掌握簡單任務之前,就能成功完成更複雜的任務。
實際上,最新LLM比如o1系列,在高難度實例上有所改進,更是加劇人類預期和LLM能力之間不一致性。
這將導致,人類無法確定應該在怎樣安全操作條件下,信任大模型。
下圖中,展示了一些關鍵指標。
那些經過微調的模型(藍色),在提示變化方面,表現更加穩定正確,但在與人類任務難度的判斷的一致性降低。
而且,整體失敗次數增加,謹慎性降低。
對於Llama家族來說,沒有一個模型能在最簡單的難度水平上,達到60%的準確率。唯一例外的是,GPT-4在低難度科學任務上,幾乎在中等難度水平上,取得了完美的結果。

如上指標總結了LLM在5個精心選擇基準測試上表現,包括簡單數字運算、詞彙充足、地理知識、多樣化科學技能、以信息為中心轉換
太過自信,不會硬答
其次,「迴避」是指LLM偏離問題的回應,或給出類似「我不知道」這樣的回答。
以往,因為一些安全限制,人們經常「抽水」「大模型拒絕回答問題」。
而現在,通過scaling算力、規模、數據,和算法優化(指令微調、RLHF)方法,LLM倒是從謹慎迴避轉變為了給出錯誤答案。
因此,較新的LLM的錯誤率,已經大幅增加。
比如,GPT-4比GPT-3錯的更離譜,就是因為太過自信,很少迴避回答超出自己能力範圍的問題。
最壞的結果是,那些過度依賴LLM解決不擅長任務的用戶,會逐漸對它喪失信任。
那麼,大模型這種迴避傾向,會隨著任務難度提高而增加嗎,就像人類那樣「知難而退」?
研究人員發現,它們並不會!
即便是給出錯誤的回答,也要迎難而上。
這樣一來,對於人類來說,驗證大模型輸出結果,又多了一大負擔。
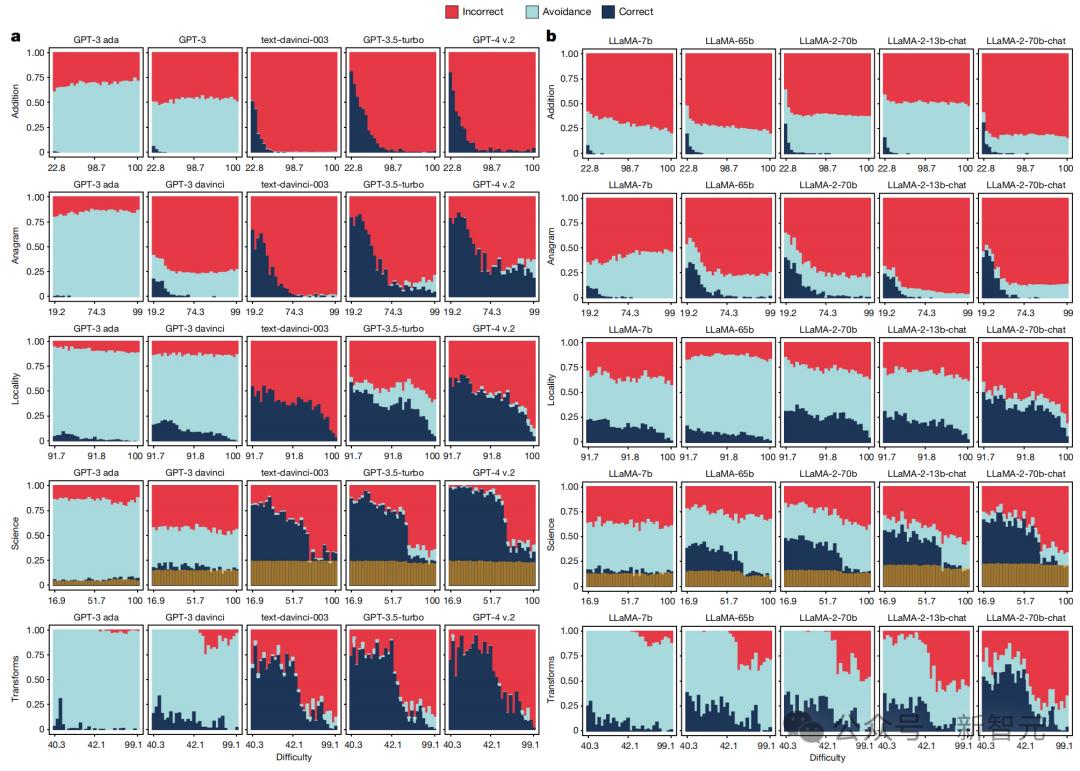
如下圖所示,GPT-3.5 Turbo不會迴避複雜問題現象,更為明顯,越有難度越激進。Llama系列更是如此……
提示詞,不通用
最後是模型對提示詞的「敏感性」和「穩定性」。
前者的問題在於,那些在複雜任務中表現優異的提示詞,被複用到簡單任務中時,模型竟無法輸出正確的結果。
後者的問題在於,對於相同的任務,但採用不同的提示詞時,模型就會輸出錯誤的結果。
也就是說,「提示工程」這項技術活,不具普適性。
而且,同樣一道題,用不同提示來詢問,也會影響模型輸出的結果。

下表中呈現了,經過微調的模型通過對「提示變化」並不敏感。
而再從上圖中scaling數據中,觀察這一維度的演變,就能發現原始模型(GPT-3 davinci)和GPT家族其他模型,存在很大差異。
Llama家族的模型變化,相對較小。
原始GPT和所有Llama模型,對提示詞高度敏感,即使在「加法」這樣高度明確任務中,也是如此。
而且,難度似乎對敏感性影響不大。對於簡單的任務,原始模型(特別是GPT-3 davinci和Llama模型)只有通過精心挑選的提示才能解答。
對於那些經過微調後的模型,即最後6個GPT模型和最後3個Llama Chat模型,卻發生了實質性變化。
這些模型表現更加穩定,但在不同難度水平上,結果仍存在變數。

RLHF被判「死刑」?
再來看常見的RLHF。
通過人類反饋強化學習後的LLM,可靠性有所改進嗎?
研究發現,RLHF根本無法彌補大模型不可靠性。
在人類意識到很難的應用領域中,對於LLM輸出結果,往往會表現出一種「不懂裝懂」的樣子。
「心裡OS:我也不懂怎麼解,或許LLM回答就是對的」。
他們通常會將不正確的結果,也視為正確答案。這種判斷誤差,導致大模型的RLHF,也是越來越離譜。
甚至,對於簡單任務而言,也不存在一個既能保證AI低錯誤率,又能保證人類監督低錯誤率的「安全操作空間」。
如下圖所示,人類監督錯誤率隨著任務難度的演變。

作者介紹

Lexin Zhou在劍橋大學獲得計算機科學碩士學位,由Andreas Vlachos教授指導。此前,在華倫西亞理工大學完成了數據科學學士學位,導師是Jose Hernandez-Orallo教授。

就讀期間,他曾在Meta AI、OpenAI、Krueger AI安全實驗室實習,並在VRAIN和歐盟委員會JRC等機構,擔任AI評估的研究/諮詢角色。
他稱自己大部分時間都在思考:
(1)設計具有解釋和預測能力的穩健評估方法,以評估AI的能力、局限性和風險;
(2)尋找積極塑造AI系統的可靠性和可預測性的途徑。
此外,他還對AI的社會影響、心理測量學、認知科學和AI安全性廣泛感興趣,尤其對LLM這樣的通用系統特別感興趣。

補充評測
為了更好地展示LLM存在不可靠性問題——難題能答對但在簡單題目上翻車(難度不一致性),無法迴避超出模型能力的任務(任務迴避),以及對提示詞的穩定性,論文還附上了補充測評的結果。
研究人員針對o1-mini、o1-preview、Claude 3.5 Sonnet和Llama 3.1 405B Instruct Turbo做了數十個真實的評測,部分結果如下。
難度不一致性
在這裏,每個LLM分別展示了1~2對示例,其中每對首先包含一個成功解決的困難任務,另一個是同一領域的、但LLM犯錯的簡單任務。
比如,o1-preview在字謎任務中,可以識別出「tnelcccerneiumleoes」是單詞「electroluminescence」的順序顛倒,但對字謎「myyum」,卻給出了錯誤的響應「mummy」。
o1-preview

複雜的科學任務,回答正確
 簡單任務,回答錯誤(正確答案是A)
簡單任務,回答錯誤(正確答案是A) o1-mini

複雜的轉換任務,回答正確
 簡單任務,回答錯誤(正確答案是17-07-2004)
簡單任務,回答錯誤(正確答案是17-07-2004) Claude 3.5 Sonnet

複雜的科學任務,回答正確
 簡單任務,回答錯誤(正確答案是A)
簡單任務,回答錯誤(正確答案是A) Llama 3.1 405B Instruct Turbo

複雜的加法任務,回答正確

簡單的任務,回答錯誤(正確答案是以214結尾)

複雜的字謎任務,回答正確
 簡單任務,回答錯誤(正確答案是yummy)
簡單任務,回答錯誤(正確答案是yummy) 任務迴避
研究者從LLM無法解決的多個領域中隨機提取了一些非常有挑戰性的問題,結果發現,模型的響應始終過於自信。
o1-mini和o1-preview通常會花費50~140秒,甚至更長的時間來思考這些任務(最終也沒有做對),而不是簡單地說「我無法解決這個問題」。
o1-preview
在這道加法題上,o1-preview思考了55秒,然後給出了一個錯誤答案。


類似的題型,o1-preview這次思考了長達102秒,但還是做錯了。


對於下面這道具有挑戰性的轉換任務,o1-preview花了80秒的時間來計算這個「錯誤答案」。

o1-mini
相比之下,o1-mini的思考時間會更快一些。
o1-mini只用了22秒,就給出了這道單詞重組遊戲的「錯誤答案」。
 (正確答案是entrepreneurialism)
(正確答案是entrepreneurialism) 在地理任務上,更是只用了幾秒的時間,但答案依然不對。
 (正確答案是Shiprock)
(正確答案是Shiprock) Claude 3.5 Sonnet
同樣的問題,Claude 3.5 Sonnet也沒做出來。
加法:

地理:
 (正確答案是Shiprock)
(正確答案是Shiprock) 科學:

 (正確答案是A)
(正確答案是A) Llama 3.1 405B Instruct Turbo
Llama 3.1 405B Instruct Turbo也不出意外地敗下陣來。
加法:


字謎:
 (正確答案是compartmentalisation)
(正確答案是compartmentalisation) 提示穩定性
在這裏,研究人員證明,對於相同的問題,如果採用不同的提示詞,模型給出的回答也會不一樣。
以下所有例子都遵循相同的模式:首先是一個得到正確答案的提示詞示例,緊接著是一個詢問相同問題但使用不同提示詞的示例,而後者得到的卻是錯誤的答案。
o1-preview
地理:


o1-mini
字謎:


科學:


Claude 3.5 Sonnet
轉換:


Llama 3.1 405B Instruct Turbo
加法:


這些例子表明,目前LLM對於提示詞的穩定性依舊不理想,將相同的問題換個說法,就可能導致模型答案發生顯著變化。
作者希望,未來在通用AI設計和開發方面,尤其是那些需要精確控制錯誤分佈的高風險領域,需要進行根本的變革。
而且,在實現這一目標之前,研究人員必須警惕,過度依賴人類監督所帶來潛在風險。
參考資料:
https://docs.google.com/document/u/0/d/1SwdgJBLo-WMQs-Z55HHndTf4ZsqGop3FccnUk6f8E-w/mobilebasic?_immersive_translate_auto_translate=1
https://x.com/lexin_zhou/status/1838961179936293098
https://www.nature.com/articles/s41586-024-07930-y
https://lexzhou.github.io/
本文來自微信公眾號「新智元」,編輯:編輯部 HXY ,36氪經授權發佈。