Google自曝TPU秘密武器,AlphaChip登Nature,深度解讀AI設計芯片的發展歷程
近日,Google DeepMind 在 Nature 上正式公佈了其最新的芯片設計算法 AlphaChip,該方法致力於加速和優化計算機芯片的開發,已經歷經多款 TPU 的產品考驗,可在短短數小時內完成人類專家需要數週甚至數月的芯片佈局設計。
2020 年,Google發表了一篇具有里程碑意義的預印本論文「Chip Placement with Deep Reinforcement Learning」,首次向世界展示了其採用新型強化學習方法設計的芯片佈局。這一創新使得Google能夠在 TPU 的芯片設計中引入 AI,實現了超越人類設計師的芯片佈局。
到了 2022 年,Google進一步開源了該論文中描述的算法代碼,使得全球的研究人員都能夠利用這一資源對芯片塊進行預訓練。
如今,這一由 AI 驅動的學習方法已經經歷了 TPU v5e、TPU v5p 以及 Trillium 等多代產品的考驗,並在Google內部取得了顯著的成就。更令人矚目的是,Google DeepMind 團隊最近在 Nature 上發表了該方法的附錄,更為詳盡地闡述了其對芯片設計領域所產生的深遠影響。同時,Google還開放了一個基於 20 個 TPU 模塊預訓練的檢查點,分享了模型權重,並將其命名為 AlphaChip。
AlphaChip 的問世,不僅預示著 AI 在芯片設計領域的應用將變得更加廣泛,也標誌著我們正邁向一個由「芯片設計芯片」的全新時代。
AlphaChip:Google DeepMind 如何用 AI 革新芯片設計
作為Google DeepMind 的巔峰之作,AlphaChip 正以其在芯片設計領域的革命性進展,捕獲全球科技界的矚目。
芯片設計是一項位於現代科技之巔的領域,其複雜性在於將無數精密元件通過極其細微的導線巧妙連接。作為首批應用於解決現實世界工程問題的強化學習技術之一,AlphaChip 能夠在短短數小時內完成與人類相媲美甚至更優的芯片佈局設計,無需耗費數週或數月的人力勞動。這一劃時代的進展,為我們打開了超越傳統極限的想像之門。
那麼,AlphaChip 究竟是如何實現這一壯舉的呢?
AlphaChip 的秘訣在於其採用的強化學習原理,將芯片佈局設計視為一場遊戲。從一個空白的網格出發,AlphaChip 逐步放置每一個電路元件,直至全部就位。隨後,根據佈局的優劣,系統會給予相應的獎勵。
更重要的是,Google創新性地提出了一種「基於邊」的圖神經網絡,使得 AlphaChip 能夠學習芯片元件之間的相互關係,並將其應用於整個芯片的設計中,從而在每一次設計中實現自我超越。與 AlphaGo 類似,AlphaChip 可以通過「遊戲」學習,掌握設計卓越芯片佈局的藝術。
在設計 TPU 佈局的具體過程中,AlphaChip 首先會在前幾代芯片的各類模塊上進行預訓練,包括芯片上和芯片間的網絡模塊、內存控製器和數據傳輸緩衝區等。這一預訓練階段為 AlphaChip 提供了豐富的經驗。隨後,Google利用 AlphaChip 為當前 TPU 模塊生成高質量的佈局。
與傳統方法不同,AlphaChip 通過解決更多的芯片佈局任務,不斷優化自身,正如人類專家不斷通過實踐提升技能一樣。正如 DeepMind 聯合創始人兼 CEO Demis Hassabis 所言,Google已經圍繞 AlphaChip 建立了一個強大的反饋循環:
* 首先,訓練先進的芯片設計模型 (AlphaChip)
* 其次,使用 AlphaChip 設計更優秀的 AI 芯片
* 然後,利用這些 AI 芯片訓練更出色的模型
* 最後,利用這些模型再去設計更出色的芯片

如此反復,實現了模型與 AI 芯片的同步升級,Demis Hassabis 表示,「這正是Google TPU 堆棧表現如此好的部分原因」。
與人類專家相比,AlphaChip 不僅放置的模塊數量更多,而且布線長度也大大減少。隨著每一代新 TPU 的推出,AlphaChip 設計出了更優秀的芯片佈局,提供了更完善的整體平面圖,從而縮短了設計週期並提升了芯片性能。
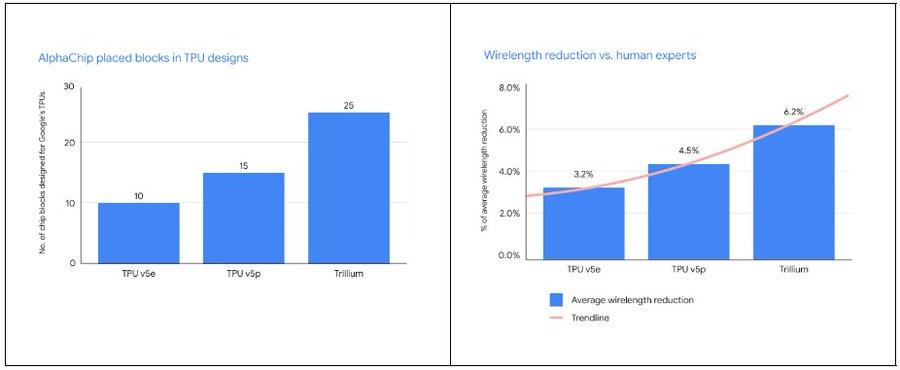 Google在三代 TPU(v5e、TPU v5p) 中 AlphaChip 設計芯片塊的數量與平均線長減少量
Google在三代 TPU(v5e、TPU v5p) 中 AlphaChip 設計芯片塊的數量與平均線長減少量Google TPU 的 10 年征程:從 ASIC 的堅持到 AI 設計的革新
作為 TPU 領域的探索者與先行者,縱觀Google在這一技術線上的發展歷程,不僅僅是憑藉其敏銳的洞察力,更彰顯了其非凡的魄力。
眾所周知,在 20 世紀 80 年代,ASIC (Application Specific Integrated Circuit) 以其成本效益高、處理能力強和速度快的特點,贏得了市場的廣泛青睞。然而,ASIC 的功能是由定製的掩模工具決定的,這就意味著,客戶需要支付昂貴的前期一次性工程 (NRE) 費用。
此時,FPGA (Field Programmable Gate Array) 以其降低預付成本和減少定製數字邏輯風險的優勢,走入大眾視野,儘管在性能上並非全面超越,卻在市場上獨樹一幟。
當時,業界普遍預測摩亞定律將推動 FPGA 的性能超越 ASIC 的需求。但事實證明,FPGA 作為一種可編程的「萬能芯片」,雖然在探索性和小批量產品中表現出色,能夠實現比 GPU 更優秀的速度、功耗或成本指標,但仍然無法擺脫「通用性與最優性不可兼得」的規律。一旦 FPGA 為某個專用架構鋪平了道路,它就會讓位給更為專業的 ASIC。
進入 21 世紀後,AI 技術熱潮一浪高過一浪,機器學習、深度學習算法持續迭代,業界對於高性能、低功耗的專用 AI 計算芯片需求上漲,CPU、GPU 等在很多複雜任務上顯得力不從心。在此背景下,Google在 2013 年做出了一個大膽的決定,選擇 ASIC 來構建 TPU 基礎設施,圍繞 TensorFlow 和 JAX 進行開發。
值得注意的是,自主研發 ASIC 是一個週期長、投入大、門檻高、風險極大的過程。一旦方向選擇錯誤,可能會導致巨大的經濟損失。然而,為了探索更具成本效益和節能的機器學習解決方案,Google在 2012 年通過深度學習在圖像識別上取得突破性進展後,就立即在 2013 年開始研發 TPUv1,並在 2015 年宣佈第一代 TPU 芯片 (TPU v1) 在內部上線,這標誌著全球首款專為 AI 設計的加速器誕生。
幸運的是,TPU 很快就迎來了一個引人注目的展示機會——2016 年 3 月,AlphaGo Lee 成功擊敗了世界圍棋冠軍李世石,作為 AlphaGo 系列的第二代版本,其運行於 Google Cloud,耗用 50 個 TPU 進行計算。
然而,TPU 並沒有因此立即在業界取得大規模的成功應用,直到 AlphaChip 芯片佈局方法的提出,TPU 才真正走進全新的發展階段。
 Google TPU 發展歷程
Google TPU 發展歷程2020 年,Google在預印本論文「Chip Placement with Deep Reinforcement Learning」中展示了 AlphaChip 的能力,它能夠從過去的經驗中學習並不斷改進,通過設計一種能夠準確預測各種網表及其佈局上的獎勵神經體系結構,能夠對輸入網表生成豐富的特徵嵌入。
AlphaChip 將性能優化的條件視為遊戲的勝利條件,採用強化學習的方法,通過訓練一個智能體,以累計獎勵最大化為目標,不斷優化芯片佈局的能力。他們開啟了 1 萬局遊戲,讓 AI 在 1 萬個芯片上練習佈局布線並收集數據,同時不斷學習優化。
最終,他們發現與人類工程師相比,AI 在面積、功率和電線長度方面的表現更優越或媲美手動佈局,同時滿足設計標準所需的時間要少得多。結果表明,AlphaChip 在不到 6 小時的時間內就可以生成媲美或超過人工的現代加速器網表上的佈局,而在同樣條件下,現有人類專家可能需要幾個星期來完成同樣的工作。
在 AlphaChip 的助力下,Google對 TPU 的依賴日益增加。2023 年 12 月,Google推出了多模態通用大模型 Gemini 的 3 個不同版本,該模型的訓練大量使用了 Cloud TPU v5p 芯片。2024 年 5 月,Google又發佈了第六代 TPU 芯片 Trillium,它能夠在單個高帶寬、低延遲 Pod 中擴展為多達 256 個 TPU 的集群,相較於前代產品,Trillium 在適配模型訓練方面的功能更強。
同時,TPU 芯片也逐漸走出Google公司,獲得了更廣泛的市場認可。2024 年 7 月 30 日,蘋果公司在其發佈的一篇研究論文中聲稱,在訓練 Apple Intelligence 生態中的人工智能模型 AFM 時,選擇了Google的兩種張量處理單元 (TPU) 雲集群。另有數據顯示,超過 60% 的生成式 AI 初創公司和近 90% 的生成式 AI 獨角獸都在使用 Google Cloud 的 AI 基礎設施和 Cloud TPU 服務。
種種跡象表明,Google十年磨一劍,TPU 已經走出培育期,開始以卓越的硬件性能為Google在 AI 時代進行反哺。而 AlphaChip 所蘊含的「AI 設計 AI 芯片」路徑,也為芯片設計領域開闢了新的視野。
AI 革新芯片設計:從Google AlphaChip 到全流程自動化的探索
儘管 AlphaChip 在 AI 設計芯片領域獨樹一幟,但它並非孤軍奮戰。AI 技術的觸角已經廣泛延伸至芯片驗證、測試等多個關鍵環節。
芯片設計的核心任務是優化芯片的功耗 (Power)、性能 (Performance) 和麵積 (Area) ,這三個關鍵指標統稱為 PPA,這一挑戰也被稱作設計空間探索。傳統上,這一任務由 EDA 工具完成,但為了達到最佳性能,芯片工程師必須不斷手工調整,然後再次交給 EDA 工具進行優化,如此循環往複。這個過程就像在家中擺放傢俱,不斷嘗試以實現空間利用最大化和動線最優化,但每次調整都相當於將傢俱搬出再重新佈置,極其耗時耗力。
為了破解這一難題,Synopsys 新思科技在 2020 年推出了 DSO.ai,這是業界首個融合 AI 與 EDA 的芯片設計解決方案。DSO.ai 採用強化學習技術,通過 AI 自動搜索設計空間,尋找最佳平衡點,無需人工干預。這一工具已在多家芯片巨頭中得到應用。
例如,微軟在使用 DSO.ai 後將芯片模塊的功耗降低了 10%-15%,同時保持性能不變;意法半導體將 PPA 探索效率提高了 3 倍以上;存儲芯片巨頭 SK 海力士則將芯片面積減少了 5%。Synopsys 的數據顯示,DSO.ai 已成功助力超過 300 次商業流片,標誌著 AI 在真正的芯片設計與生產中發揮了重要作用。
在 AI 輔助芯片驗證方面,Synopsys 新思科技發佈的技術報告也指出,驗證過程佔據了整個芯片開發週期的高達 70% 的時間。一次芯片流片的成本高達數億美元,而現代芯片的複雜性不斷增加,驗證難度可想而知。為此,Synopsys 新思科技推出了 VSO.ai 工具,利用 AI 優化驗證空間,加速覆蓋率的收斂速度。
VSO.ai 能夠推斷出不同的覆蓋率類型,與傳統的代碼覆蓋率形成互補,AI 還能從驗證經驗中學習,不斷優化覆蓋率目標。此外,Synopsys 新思科技還推出了 TSO.ai 工具,能夠幫助芯片開發者篩選出代工廠製造的有缺陷的芯片。
AI 在芯片設計領域的深度介入,引發了一個大膽的設想:我們能否用 AI 設計一顆完整的芯片?事實上,英偉達已經在這一領域進行了嘗試。通過深度強化學習代理設計電路,英偉達的 H100 中就有近 13,000 條電路由 AI 設計。中國科學院計算所也利用 AI 在 5 小時內生成了一個名為「啟蒙一號」的 RISC-V 處理器芯片,擁有 400 萬個邏輯門,性能與 Intel 80486 相當。
總體來看,AI 設計完整芯片的能力依然有限,但這無疑是未來芯片發展的一個重要機遇。隨著技術的不斷進步,AI 在芯片設計領域的潛力必將得到進一步挖掘和利用,並最終改變整個芯片的設計過程。
本文來自微信公眾號「HyperAI超神經」,作者:田小幺,36氪經授權發佈。