ECCV2024 Oral | 第一視角下的動作圖像生成,Meta等提出LEGO模型
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文的作者主要來自於 Meta 和佐治亞理工大學。第一作者是佐治亞理工機器學習專業的博士生賴柏霖(目前也是 UIUC 的訪問學生),導師為 James Rehg 教授(已轉入 UIUC),主要研究方向是多模態學習,生成模型和影片理解,並在 CVPR、ECCV、BMVC、ACL 等會議發表相關論文,參與 Meta 主導的 EgoExo4D 項目,本文工作是賴柏霖在 Meta 的 GenAI 部門實習時完成,其餘作者均為 Meta 的研究科學家。
作者主頁:https://bolinlai.github.io/
當人們在日常生活和工作中需要完成一項自己不熟悉的任務,或者習得一項新技能的時候,如何能快速學習,實現技能遷移(skill transfer)成為一個難點。曾經人們最依賴的工具是搜索引擎,用戶需要自己從大量的搜索結果中篩選出答案。最近幾年出現的大語言模型(LLM)可以依據用戶的問題歸納生成答案,極大地提升了回覆的準確率和針對性 (如圖 1 所示),然而大語言模型生成的回覆通常非常繁瑣冗長,而且包含諸多籠統的描述,並沒有針對特定用戶當下的環境進行定製化的回應。

圖 1:對於同一個問題,本文提出的 LEGO 模型直接生成圖片教程,相比於大語言模型的回應更加具有針對性。
隨著大語言模型逐漸獲得理解圖片的能力,一個簡單直接的解決方案是用戶在提出問題的同時也提供一張包含眼前場景的照片,這樣模型便可以根據用戶當下的環境來生成更準確直接的指令,從而讓人們更容易跟隨指令完成任務。那是否有比這更簡單直接的方法呢?之前的神經科學研究表明,人類大腦處理圖片的速度要遠快於處理文字,如果模型可以直接生成一張圖片來給用戶展示如何執行下一步,便可以進一步提升人們的學習效率。
在今年的 ECCV Oral Session,來自 Meta、佐治亞理工(Georgia Tech)和伊利諾伊香檳分校(UIUC)的研究者們提出一個新的研究問題:如何基於用戶的問題和當前場景的照片,生成同一場景下的第一視角的動作圖像,從而更準確地指導用戶執行下一步行動?

-
論文地址:https://arxiv.org/pdf/2312.03849
-
項目主頁:https://bolinlai.github.io/Lego_EgoActGen/
-
開源代碼:https://github.com/BolinLai/LEGO
挑戰和解決方案
目前有眾多大模型在圖片生成任務上取得了極佳的效果,但這些模型在應用到本文提出的動作圖像生成的問題時,有兩個尚未解決的挑戰(如圖 2 所示):(1)當下的數據集中的動作標註非常簡略(通常為動詞 + 名詞),這使得模型難以理解動作的細節;(2)現存模型的預訓練數據基本上都是第三視角的物體或者場景圖片,並且文本中鮮有動作相關的描述,這與本文任務中所使用的數據之間存在很明顯的差距(domain gap)。

圖 2:面臨的挑戰:(1)動作細節的缺失,(2)訓練數據與現存模型存在差別。
針對這兩個問題,研究者們提出使用第一視角的動作數據對大語言模型進行微調(visual instruction tuning)來豐富動作的具體細節,同時將大語言模型的圖像和文本特徵作為擴散模型的額外輸入,從而縮小 domain gap。
基於 GPT 的數據收集
為了對大語言模型進行訓練,本文使用 GPT-3.5 來收集詳細的動作描述作為訓練數據(見圖 3),具體方法為對於少量數據(本文中為 12 個動作)進行人工擴寫動作細節,然後將這些人工撰寫的描述放入 GPT 的輸入(prompt)中進行基於上下文的學習(in-context learning),同時本文作者還將物體和手部的包圍框(bounding box)一起輸入,從而使 GPT 可以理解當前環境下物體與手的空間位置信息,通過這種方案,GPT 可以模仿少量人工標註的數據來生成大量的動作描述,這些採集到的數據會被用於大語言模型的微調。

圖 3:基於 GPT-3.5 的詳細動作描述採集。
模型結構和方法

圖 4:模型結構。
本文提出的 LEGO 模型分為兩個步驟:(1)大語言模型基於視覺指令的微調(visual instruction tuning),(2)動作圖像生成(action frame generation)。
-
基於視覺指令的微調(如圖 4a 所示):本文將用戶提供的包含當前環境信息的圖片輸入預訓練好的圖片編碼器,然後使用一層線性層將特徵映射到 LLM 的特徵空間,與用戶的問題一起輸入 LLM 中,LLM 可以基於圖片信息來生成可以直接應用於當前環境的詳細動作指令,從而為動作圖像生成提供更多的細節,解決了現有數據集中動作標註過於簡略的問題。
-
動作圖像生成(如圖 4b 所示):本文使用隱空間擴散模型(latent diffusion model)來進行圖像生成,考慮到本文數據和現有模型預訓練數據之間的差異,作者將大語言模型中的圖像特徵以及文本特徵一起作為額外的條件(condition),和動作描述一起輸入到擴散模型中。為了連接大語言模型和擴散模型的特徵空間,作者使用了線性層來映射圖片特徵;對於文本特徵,本文在線性層之外使用了兩層自注意力(self-attention)層來獲得文本整體的語義;對於動作描述,則直接使用預訓練的文本編碼器進行特徵提取。
對比及消融實驗
本方法在兩個大型第一視角動作數據集 — Ego4D 和 Epic-Kitchens 上進行驗證,研究者們定義了每個動作開始和正在進行時的關鍵幀,並且過濾掉部分低質量的數據。

表 1:圖像對圖像(image-to-image)評測結果。
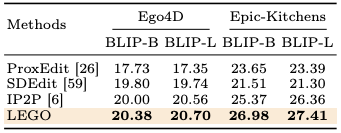
表 2:圖像對文字(image-to-text)評測結果。

圖 5:用戶評測(user study)結果。
實驗中,作者將提出的方法與多個圖生成模型在多個指標下進行對比,除此之外還用人工評測的方式進一步鞏固實驗結果。可以看到,在圖像對圖像(image-to-image)的六個指標中,LEGO 在兩個數據集上基本都超過了對比的模型,即使在 Epic-Kitchens 的 FID 指標中略低於 IP2P,但依然是第二好的效果。除此之外,本文還使用圖像對文本(image-to-text)的指標來評測生成的圖片是否正確體現了動作描述,從結果可以看到,LEGO 依然在兩個數據集上獲得最好效果。在人工評測(user study)中,研究者們將四個模型生成的圖片打亂順序讓用戶選擇生成質量最高的圖片,結果表明,超過 60% 的用戶認為 LEGO 生成的圖片最符合他們的需求。

表 3:消融實驗。
本文還對提出的模型進行了消融實驗,結果表明詳細的動作描述、LLM 的圖片和文字特徵均可以提升生成圖片的質量,其中圖片特徵對於性能的提升最為明顯。
可視化成果展示

圖 6:LEGO 模型在多種場景下的動作生成。
從生成圖片的效果(圖 6)可以看出,LEGO 模型能夠很好地理解用戶提問的動作細節,並生成準確的動作圖像,除此之外,生成圖片很好地保留了原圖的背景信息,從而用戶可以更簡單直接地遵循圖片指導來完成每一步動作。

圖 7:LEGO 模型生成同一場景下的不同動作圖像。
研究者們還成功驗證了 LEGO 可以在同一場景下生成多種動作圖像(包括未訓練過的動作),從而說明 LEGO 可以泛化到更廣泛的場景。
總結
1. 本文提出了一個全新的問題:第一視角下的動作圖像生成,從而可以提升人們學習新技能的效率。
2. 本文創新性地提出了對大語言模型進行微調來豐富動作細節,同時使用大語言模型的特徵來提升擴散模型生成圖像的性能。
3. 本文提出的 LEGO 模型在兩個大型數據集和多個指標上均取得目前最好的效果。




















