Meta給了OpenAI一記重擊:影片生成Movie Gen登場,甚至可以配音、編輯
在 OpenAI Sora 難產的時候,Meta 首次公開展示了自家的「用於媒體的突破性生成式 AI 研究」:Meta Movie Gen。
Meta 在相應博客中使用了「premiere」一詞,也就是初次展示,因此手癢的用戶可能還得再等上一段時間。

Meta 表示:「無論是希望在荷李活大展身手的電影製作人,還是愛好為觀眾製作影片的創作者,我們相信每個人都應該有機會使用有助於提高創造力的工具。」
根據 Meta 的描述,Movie Gen 的功能包括:文本生成影片和音頻、編輯已有影片、圖片生影片。並且人類評估表明,Movie Gen 在這些任務上的表現均優於行業內類似模型。
具體的效果如何,我們先來看幾個示例。
可以看到,小女孩在奔跑的過程中衣服的褶皺就已經吊打很多影片生成應用了。

prompt:一個女孩正在海灘上奔跑,手裡拿著一隻風箏。她穿著牛仔短褲和黃色 T 恤,陽光灑在她身上。
在轉頭、正視前方、微笑的幾個動作中,人物面部依然可以保持穩定狀態,克服了形變。怪不得 Meta 在博客中還談到,這是能夠用來分享日常生活的可貴技術。

prompt:一名女子正坐在南瓜田的草地上。她圍著圍巾,手裡拿著一個杯子。背景中是一排排南瓜。
生成動物對 Movie Gen 來說也是小菜一碟。動物的毛髮、動作都十分逼真。仔細看這隻猴子的尾巴,在遮擋後依然能夠遵循遮擋前的運動軌跡。背景生成結果也十分貼合 prompt。水面的波動、倒映都栩栩如生。不過水下折射的生成效果看起來還有些進步空間。

prompt:一隻紅臉白毛的猴子正在天然溫泉中沐浴。猴子在玩水面上的一艘微型帆船,這艘帆船由木頭製成,配有白色的帆和小舵。溫泉周圍環繞著鬱鬱蔥蔥的綠植,有岩石和樹木點綴其間。
影片時間長一些,Movie Gen 也能有穩定的表現。人物大幅度動作的展現也比較逼真。但每一幀定格下來,還會有些瑕疵。不過這是影片生成一貫的難題,Meta 或許會在未來進行改進。

prompt:鏡頭位於一名男子的身後。男子赤裸上身,腰間繫著綠色布料,赤腳站立。他的雙手各持一個燃燒的物體,做出大幅度的圓周動作。背景是一片平靜的海面,火舞營造出迷人的氛圍。
Sora 剛剛問世時,往往還需要 Elevenlabs 這樣的音頻生成應用來輔助。而 Movie Gen 顯然更加便捷,除了影片生成,配備相應的音樂、音效也是拿手好戲。
面對一整個影片的場景,合適的背景音樂能夠貫穿全程。不僅如此,音效的適配度也很高。這個瀑布傾瀉的水聲就十分逼真。
prompt:雨水傾瀉在懸崖和人身上,有背景音樂。
更讓人驚訝的是,音效還能夠精準地與影片內容匹配。它能夠通過影片中的動作節點來把握音效出現的時機,讓畫面和聲音相輔相成,給我們呈現出完整的生成效果。
prompt:車輪飛速旋轉,滑板落在水泥地上發出砰的一聲。
無論是影片,還是音頻 Movie Gen 看起來都表現優異。
如果 Meta 所言非虛,那麼 Movie Gen 也真算得上是目前最先進和最沉浸式的「講故事模型套件(storytelling suite of models)」。
Meta 表示訓練使用的數據集都是公開數據集或已獲得授權的數據集。下面將簡要介紹各項能力以及背後的技術,更多詳情請參閱原論文。

- 論文名稱:MovieGen: A Cast of Media Foundation Models
- 論文鏈接:https://ai.meta.com/static-resource/movie-gen-research-paper
- 更多演示:https://ai.meta.com/research/movie-gen/
Meta 在博客中簡單回顧了自己的影片生成之旅。他們的第一波生成式 AI 研究始於 Make-A-Scene 系列模型,這些模型可以生成圖像、音頻、影片和 3D 動畫。
隨著擴散模型的出現,他們又基於 Llama 基礎模型做出了第二波研究,成功實現了更高質量的圖像和影片生成以及圖像編輯。
Movie Gen 則是 Meta 的第三波研究。他們將以上所有模態都組合到了一起,並能以前所未有的方式為用戶提供進一步的細粒度控制。
下面詳細介紹 Movie Gen 的各項能力。
影片生成
給定文本提示詞,Movie Gen 會使用一個針對文生圖和文生影片任務優化過的聯合模型來創建高質量和高清晰度的圖像和影片。這個 30B 參數的 Transformer 模型有能力生成長度最多 16 秒幀率為 16 FPS 的影片。Meta 表示還發現這些模型可以推理物體運動、主客體交互和相機運動,並且它們還能學習各種概念的合理運動 —— 這也使它們成為了同類中的 SOTA 模型。
具體流程如下圖所示,他們先通過一個時間自動編碼器模型(TAE)訓練了一個時空壓縮的隱空間,然後再基於此訓練了一個生成模型。

模型架構上,他們採用了 Transformer,整體位於 Llama 3 的設計空間中。下表展示了其 30B 參數基礎模型的各個超參數。值得注意的是,這裏的 30B 參數指的是 Transformer 本身的參數量,並不包含文本嵌入模型、TAE 等。

為了訓練這個模型,Meta 使用了多達 6144 台 H100 GPU,每一台的熱設計功耗為 700W,並且都配備了 80GB 的 HBM3。
下圖展示了 Movie Gen Transformer 骨幹網絡的整體結構以及所使用的模型並行化機制。具體來說包括張量並行化(TP))、序列並行化(SP)、上下文並行化(CP)和全共享式數據並行(FSDP)。

訓練流程上,他們採用了一種多階段訓練方法,該方法分為三個階段:
- 在文生圖(T2I)任務上進行初始訓練,之後再在文生圖和文生影片(T2V)任務上進行聯合訓練;
- 逐步從低解像度 256 像素的數據擴展成 768 像素的高解像度數據;
- 在計算和時間限制上,使用改進過的數據集和已優化的訓練方法進行持續訓練。
之後自然也會執行微調。
而在推理階段,Meta 的一個創新思路是首先使用 Llama 3 對用戶輸入的提示詞進行重寫,將其擴展成更加詳細的版本。實踐表明該方法確實有助於提升生成結果的質量。此外,Meta 還在提升推理效率方面引入了一些新思路。
效果上,下表展示了 Movie Gen Video 模型與之前相關研究的勝率情況。注意這裏的數值是 Movie Gen 的獲勝百分比減去落敗百分比,因此可知 Movie Gen 的整體表現勝過之前的模型。

個性化影片
基於上述基礎模型,Meta 還開發出了個性化影片功能。用戶只需提供人物圖像輸入和對應的文本提示詞,就能生成包含該人物以及文本描述的細節的影片。Meta 表示 Movie Gen 生成的個性化影片在保留人類身份和運動方面做到了 SOTA。
下圖展示了個性化 Movie Gen Video 模型(PT2V)的架構和推理流程。

具體來說,首先使用 Movie Gen Video 模型的權重對該模型進行初始化,然後添加額外的可學習參數來基於參考圖像實現條件化編輯。
訓練過程先是進行預訓練(分為身份注入、長影片生成、提升自然度三個階段),然後執行監督式微調。
結果上看,在經過微調之後,PT2V 模型在身份和人臉一致性上的表現都相當卓越。
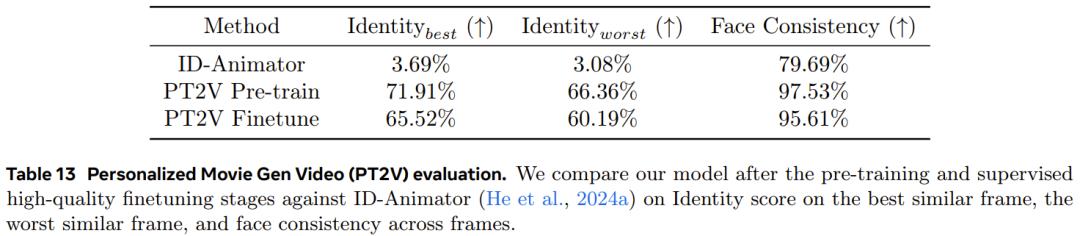
下圖展示了兩個與 ID-Animator 的對比示例:

精確的影片編輯
還是基於同樣的基礎模型,Meta 也做出了影片編輯功能,並且可以做到非常精確的編輯 —— 可僅操作相關像素!具體來說,給定一段影片和文本提示詞,模型可以生成符合要求的經過修改的輸出,其中包括一些非常高階的編輯功能,比如添加、移除和替換元素,修改背景和風格等全局要素。
如果後面實際效果真如 Meta 描述那麼好,那麼這項功能可能會成為一大利器。
為了做到這一點,Meta 團隊同樣採用了一種多階段方法:首先執行單幀編輯,然後進行多幀編輯,之後再整體編輯影片。

為此,他們對前述的影片生成模型進行了一番修改。首先,通過向圖塊嵌入工具添加額外的輸入通道而實現了對輸入影片的調節,從而可沿通道維度將隱含的影片輸入與有噪聲的輸出隱影片連接起來,並將連接後的隱影片提供給模型。
此外,按照 Emu Edit 的做法,他們還加入了對特定編輯任務(例如添加對象、更改背景等)的支持。具體來說,該模型會對每個任務學習一個任務嵌入向量。對於給定的任務,模型對相應的任務嵌入應用線性變換,產生四個嵌入,這些嵌入與文本編碼器的隱藏表示連接在一起。我們還對任務嵌入應用了第二個線性變換,並將得到的向量添加到時間步嵌入中。另外,為了完全保留模型的影片生成功能,他們將所有新添加的權重設置為零,並基於預訓練的文生影片模型初始化賸餘的權重。
該方法的效果非常顯著,在兩個數據集上的人類和自動評估結果基本都優於其它對比方法。順帶一提,Movie Gen Edit Bench 是 Meta 提出的一個新基準,用於評估「下一代影片編輯模型的影片編輯能力」。

音頻生成
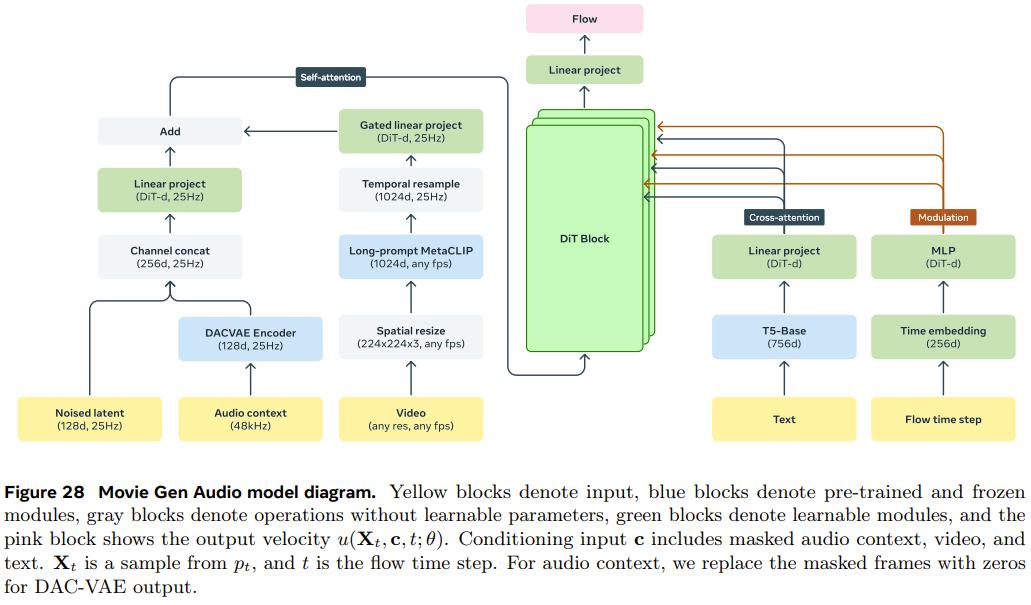
此外,他們還訓練了一個 13B 參數的音頻生成模型 Movie Gen Audio。該模型可以基於影片和可選的文本提示詞生成長達 45 秒的高質量高保真音頻,包括環境聲音、音效(Foley)和背景音樂 —— 所有這些都與影片內容同步。
下面是 Movie Gen Audio 的模型示意圖,可以看到其採用了基於流匹配(flow-matching 生成模型和擴散 Transformer(DiT)的模型架構。此外,還添加了一些條件化模塊來實現對模型的控制。
此外,他們還提出了一種音頻擴展技術,可以為任意長度的影片生成連貫的音頻。下面是該技術的示意圖。其目標是一次生成 30 秒長度的音頻,然後利用該擴展延展至任意長度。

總體而言,他們在音頻質量、影片到音頻對齊和文本到音頻對齊方面實現了 SOTA。

結語
Meta 在架構、訓練目標、數據處理方法、評估協議和推理優化等多個技術方面做出了創新突破。下圖展示了 Movie Gen 四項能力的人類 A/B 評估對比結果。正淨勝率表示人類相較於其他行業模型,更加偏愛 Movie Gen。

Meta 這一次展示自己在影片生成方面的研究成果確實出人意料,這也使其成為了這片越來越擁擠的戰場的又一強力競爭者,並且我們也還不清楚 Meta 是否會像發佈 Llama 系列模型那樣完全免費發佈 Movie Gen,讓自己在真・OpenAI 之路上繼續前進。總之,網民們已經在期待了。

最後,例行慣例,還是得向 OpenAI 問一句:Sora?
本文來自微信公眾號「機器之心」(ID:almosthuman2014),36氪經授權發佈。