Meta版Sora無預警來襲
剛剛,Meta搶在OpenAI之前推出自己的Sora——Meta Movie Gen
Sora有的它都有,可創建不同寬高比的高清長影片,支持1080p、16秒、每秒16幀。
Sora沒有的它還有,能生成配套的背景音樂和音效、根據文本指令編輯影片,以及根據用戶上傳的圖像生成個性化影片。
Meta表示,這是「迄今為止最先進的媒體基礎模型(Media Foundation Models)」。

只需一句「把燈籠變成飛向空中的泡泡」,就能替換影片中的物體,同時透明的泡泡正確反射了背景環境。
上傳一張自己的照片,就能成為AI電影的主角。
生成的影片不再無聲,也不只是能安一個背景音樂。
比如看這裏!影片會配合滑板輪子轉動和落地配上逼真音效。(注意打開聲音)
有人表示,隨著大量創作者學會使用AI影片編輯工具,很難想像幾年後長影片和短影片會變成什麼樣。

這一次,與Sora只有演示和官網博客不同,Meta在92頁的論文中把架構、訓練細節都公開了。

不過模型本身還沒開源,遭到抱抱臉工程師貼臉開大,直接在評論區扔下Meta的開源主頁鏈接:
在這等著您嗷。

Meta在論文中特別強調,數據規模、模型大小、訓練算力的擴展對於訓練大規模媒體生成模型至關重要。通過系統地提升這幾個維度,才使得如此強大的媒體生成系統成為可能。
其中最另業界關注的一點是,這一次他們完全扔掉了擴散模型和擴散損失函數,使用Transformer做骨幹網絡,流匹配(Flow Matching)做訓練目標。
用Llama3架構做影片模型
具體來說Movie Gen由影片生成和音頻生成兩個模型組成。
Movie Gen Video:30B參數Transformer模型,可以從單個文本提示生成16秒、16幀每秒的高清影片,相當於73K個影片tokens。
對於精確影片編輯,它可以執行添加、刪除或替換元素,或背景替換、樣式更改等全局修改。
對於個性化影片,它在保持角色身份一致性和運動自然性方面取得SOTA性能。

Movie Gen Audio:13B參數Transformer模型,可以接受影片輸入以及可選的文本提示,生成與影片同步的高保真音頻。

Movie Gen Video通過預訓練-微調範式完成,在骨幹網絡架構上,它沿用了Transoformer,特別是Llama3的許多設計。

預訓練階段
在海量的影片-文本和圖像-文本數據集上進行聯合訓練,學習對視覺世界的理解。這個階段的訓練數據規模達到了O(100)M影片和O(1)B圖像,用以學習運動、場景、物理、幾何、音頻等概念。
微調階段
研究人員精心挑選了一小部分高質量影片進行有監督微調,以進一步提升生成影片的運動流暢度和美學品質。

為了進一步提高效果,模型還引入了流匹配(Flow Matching)作為訓練目標,這使得影片生成的效果在精度和細節表現上優於擴散模型。
擴散模型通過從數據分佈逐漸加入噪聲,然後在推理時通過逆過程去除噪聲來生成樣本,用大量的迭代步數逐步逼近目標分佈。
流匹配則是通過直接學習樣本從噪聲向目標數據分佈轉化的速度,模型只需通過估計如何在每個時間步中演化樣本,即可生成高質量的結果。
與擴散模型相比,流匹配方法訓練更加高效,計算成本更低,並且生成的結果在時間維度上具有更好的連續性和一致性。

在整體架構上,首先通過時空自編碼器(Temporal AutoEncoder, TAE)將像素空間的RGB圖像和影片壓縮到一個時空潛空間,學習一種更加緊湊的表徵。
接著,輸入的文本提示被一系列預訓練的文本編碼器編碼成向量表示,作為模型的條件信息。這裏用到了多種互補的文本編碼器,包括理解語義的編碼器如UL2、與視覺對齊的編碼器如Long-prompt MetaCLIP,以及理解視覺文本的字符級編碼器如ByT5。
最後,生成模型以Flow Matching的目標函數進行訓練,從高斯分佈采樣的噪聲向量作為輸入,結合文本條件,生成一個輸出潛碼。這個潛碼經過TAE解碼,就得到最終的圖像或影片輸出。

此外Movie Gen Video在技術上還引入了多項創新:
為了讓模型同時適配圖像和影片,設計了一套因子化的可學習位置編碼(factorized learnable positional embedding)機制。對高度、寬度、時間三個維度分別編碼,再相加。這樣即適配了不同寬高比,又能支持任意長度的影片。
針對推理效率問題,它採用了線性-二次時間步長調度(linear-quadratic t-schedule)策略。僅用50步就能逼近1000步采樣的效果,大幅提升了推理速度。
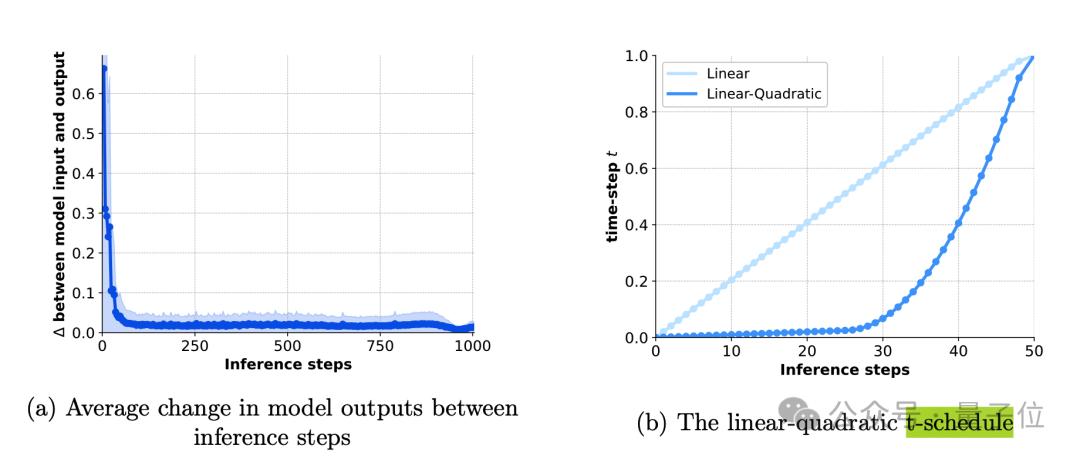
為了進一步提高生成效率,Movie Gen Video模型還採用了基於時間平鋪(temporal tiling)的推理方法。應對生成高解像度長影片時,直接對整個影片進行編碼和解碼可能會遇到的內存限制問題。
在時間平鋪推理中,輸入影片在時間維度上被分割成多個片段,每個片段獨立進行編碼和解碼,然後在輸出時將所有片段重新拚接在一起。這種方法不僅降低了對內存的需求,還提高了推理的效率。
此外,在解碼階段使用了重疊和混合的方式來消除片段邊界處的偽影問題,即通過在片段之間引入重疊區域,並對重疊區域進行加權平均,確保生成的影片在時間維度上保持平滑和一致。

另外Meta還開源了多個基準測試數據集,包括Movie Gen Video Bench、Movie Gen Edit Bench和Movie Gen Audio Bench,為後續研究者提供了權威的評測工具,有利於加速整個領域的進步。
這篇長達92頁的論文還介紹了更多在架構、訓練方法、數據管理、評估、並行訓練和推理優化、以及音頻模型的更多信息。
感興趣的可到文末鏈接查看。

One More Thing
AI影片生成這塊,這兩天熱鬧不斷。
就在Meta發佈Movie Gen之前不久,OpenAI Sora主創之一Tim Brooks跳槽GoogleDeepMind,繼續影片生成和世界模擬器方面的工作。

這讓很多人想到,就像當年Google遲遲不推出大模型應用,Transformer 8個作者紛紛出走。
現在OpenAI遲遲發佈不了Sora,主要作者也跑了。
不過另外也有人認為,Tim Brooks選擇現在離開,或許說明他在OpenAI的主要工作完成了,也讓人開始猜測:
Meta的發佈會迫使OpenAI放出Sora來回應嗎?
(截至目前為止,Sora的另一位主創Bill Peebles還未發聲。)

現在Meta放出了帶有影片編輯功能的模型,再加上10月1日Pika 1.5更新,主打給影片中物體加上融化、膨脹、擠壓等物理特效。
不難看出,AI影片生成下半場,要開始捲向AI影片編輯了。

論文地址:
https://ai.meta.com/static-resource/movie-gen-research-paper
參考鏈接:[1]https://ai.meta.com/research/movie-gen/[2]https://x.com/AIatMeta/status/1842188252541043075
夢晨 衡宇 發自 凹非寺量子位 | 公眾號 QbitAI
本文來自微信公眾號「量子位」(ID:QbitAI),作者:關注前沿科技,36氪經授權發佈。