大模型「強崩潰」!Meta新作:合成數據有「劇毒」,1%即成LLM殺手

新智元報導
編輯:祖楊 桃子
【新智元導讀】1%合成數據,就能讓模型瞬間崩潰!來自Meta、NYU等機構團隊證實,「微量」合成數據便讓LLM弱不可堪。甚至,參數規模越大,模型崩潰越嚴重。
1%的合成數據,就讓LLM完全崩潰了?
7月,登上Nature封面一篇論文證實,用合成數據訓練模型就相當於「近親繁殖」,9次迭代後就會讓模型原地崩潰。
 論文地址:https://www.nature.com/articles/s41586-024-07566-y
論文地址:https://www.nature.com/articles/s41586-024-07566-y然而,許多大佬都不同意這篇文章的方法和結論。
比如,Scale AI的CEO Alexandr Wang就很看好合成數據的前景,英偉達發佈的開源模型Nemotron-4 340B甚至使用了98%的合成數據。
最近,Meta、紐約大學、UCLA機構發表的最新論文,再一次動搖了這些大佬們的結論。
 論文地址:https://arxiv.org/abs/2410.04840
論文地址:https://arxiv.org/abs/2410.04840他們發現,即使合成數據僅僅佔到總數據集的最小部分,甚至是1%的比例,仍然可能導致模型崩潰。
甚至,ChatGPT和Llama這種較大的模型,還可能放大這種「崩潰」現象。
強模型崩潰,如何發生的?
隨著越來越多的合成數據出現在訓練集中,一種新的現象應運而生:「模型崩潰」。
所謂「模型崩潰」,是指隨著時間的推移,LLM或大型圖像生成器在其前幾代生成的數據上進行遞歸訓練,導致性能下降,直至模型完全喪失能力的情況。
圍繞著這個問題,AI學界和業界的大佬依舊莫衷一是,尚未達成一致的結論。
而合成數據究竟會在多大比例、多大程度上導致「模型崩潰」,直接影響著我們在未來如何應用這項技術。
從直覺上理解,合成數據導致「模型崩潰」的底層邏輯,是由於模型開始對合成數據中的模式進行過擬合,而這些模式可能無法代表現實世界數據的豐富性或可變性。
如果進行連續的迭代訓練,這種反饋循環會導致模型強化合成數據中存在的錯誤、偏差或過度簡化,因而損害了對現實世界的準確表示能力和泛化能力。
總體而言,這篇文章旨在回答以下兩個重要問題:
Q1:模型崩潰是不可避免的,還是可以通過策略性地混合真實數據和合成數據來解決?
Q2:較大的模型比較小的模型更容易崩潰嗎?
針對這兩個問題,論文以經典線性設置中的回歸問題為例進行了理論分析,之後在「玩具設置」(MINIST數據集+迷你模型)和更接近真實場景的GPT-2模型上運行了實驗。
理論設置
數據分佈
考慮從真實數據分佈P_1采樣得到的n_1個獨立同分佈樣本𝒟_1={(x_i, y_i)∣1≤i≤n_1},以及從合成數據分佈采樣得到了n_2個獨立同分佈樣本𝒟_2={(x_i, y_i)∣1≤i≤n_2},令n:=n_1+n_2為訓練數據總量。
這裏,數據分佈的特徵可以在ℝ^d×ℝ上給出,即P_k=P_{Σ_k,w_k^∗,σ_k^2}:

其中,每個Σ_k都是一個d×d的正定協方差矩陣,捕獲輸入特徵向量x的內在變化;σ_k控制每種分佈中標籤噪聲的水平。
為了簡潔起見,我們將對w_k^∗做出以下先驗假設(對於某些d×d正半定矩陣Γ和Δ):
– 真實標籤:w_1^∗∼N(0,Γ)
– 真實標籤與合成標籤之間的不匹配:δ:=w_2^∗−w_1^∗∼N(0,Δ) ,獨立於w_1^∗
其中,矩陣Γ捕獲真實/測試分佈中的真實標籤函數的結構P_1;矩陣Δ=cov(w_2^∗−w_1^∗)捕獲數據分佈P_1和P_2之間關於條件分佈p(y|x)差異的協方差結構,連同標籤的噪聲水平σ_1^2和σ_2^2。
平均而言,兩種分佈的L2範數差異可以表示為,

因此,合成數據的質量就可以被定義為,

模型和性能度量
給定訓練數據,模型的學習目標是構建一個估計器w\hat,這可以看作是一個線性模型 x↦x^⊤w\hat。與真實數據分佈P_1對比,模型的測試誤差f\hat:ℝ^d→ℝ就可被定義為:

針對不同的模型,f\hat就是本篇論文的主要研究對象。此處考慮兩類易於分析處理的模型:1)經典線性模型,對輸入空間中的回歸施加懲罰,以及2)通過隨機投影得到特徵空間,之後施加回歸懲罰獲得的模型。
第一類線性模型的優化目標如公式3所定義:
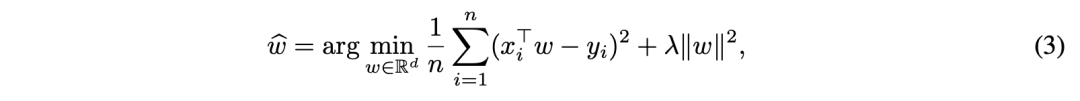
該模型存在如下的比例縮放限制(proportionate scaling limit):

由此,我們可以得到表示經典線性模型 f_{CL}\hat的定理1:

由定理1和相關推論可知,在Scaling Law範式中(ϕ→0+),如果要保持穩定,則必須要求p2→0+,即僅對真實數據進行訓練,否則就會導致模型崩潰。
對第二類的隨機投影模型(random projections model),可以通過其中的隨機投影來簡單近似神經網絡。
相當於,模型
中,v\hat ∈ ℝ^k通過擬合數據集進行學習,優化目標如公式5所定義:

同樣規定在如下的漸近(asymptotic)機制中工作:

這類模型可以被視為實際神經網絡高維動態的簡化。將定理1擴展到隨機投影情況,可以得到定理2:

其中,ζ表達式的第一項給出了下界

這就意味著,除非p2→0+,即訓練集中合成數據部分消失,否則模型的性能將始終穩定在基線E\bar之上(意味著強烈的模型崩潰)。
此外,其中的

部分僅取決於模型的設計選擇(之前通過標量θ定義),因此可以預計,不同的設計選擇(例如模型大小),將導致不同的模型崩潰輪廓。
實驗結果
如上所示,定理2作為定理1的拓展,給了我們相同的結論:要想模型不崩潰,合成數據比例就需要無限接近0。
接下來,作者通過一系列實驗驗證了這一理論推導,並探究模型尺寸在其中扮演的作用。
圖1對應的實驗中,訓練樣本總數固定為 n=500,不同的c^2值對應不同質量的合成數據。
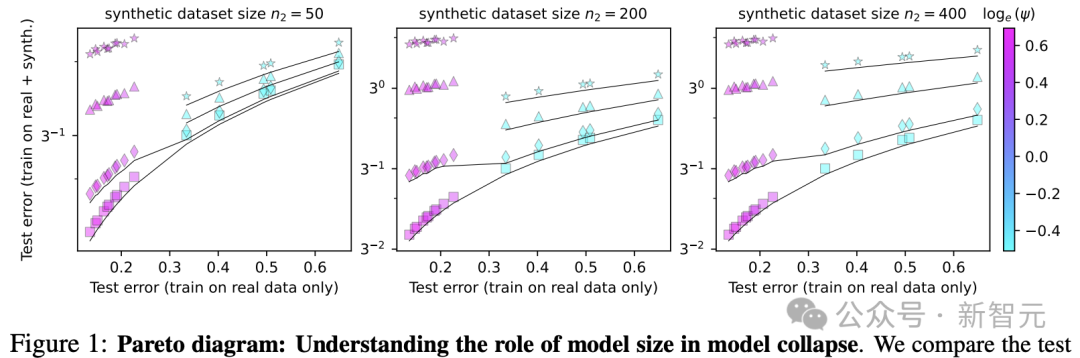
c^2=0 (非常高質量的綜合數據),用方形標記表示;c^2=0.1 (高質量合成數據),用菱形表示;c^2=0.5 (低質量),用三角形表示,以及c^2=1 (非常低質量的合成數據),用星形表示
由圖可知,對於較高質量的合成數據(方形和菱形),使用較大的模型(即更大的ψ)的確是最佳實踐;但如果數據質量較低,模型並不是越大越好,最佳權衡反而處於中等大小。
此外,如圖5所示,網絡的寬度m也會造成影響,而且實驗得到的曲線與理論預測值的擬合效果比較理想。
 實線對應實驗結果(5次運行),而虛線對應理論預測
實線對應實驗結果(5次運行),而虛線對應理論預測改變合成數據的質量後,圖5所示的整體趨勢依舊成立。
 圖6所示的實驗採用了經過全面訓練的兩層網絡,但僅根據合成數據進行訓練,依舊支持了上述的總體趨勢:
圖6所示的實驗採用了經過全面訓練的兩層網絡,但僅根據合成數據進行訓練,依舊支持了上述的總體趨勢:– 合成數據造成了顯著的模型崩潰
– 模型越大,崩潰程度越嚴重
 圖7分別顯示了隨機特徵模型(左)和完全訓練的神經網絡(右)的結果,探究合成數據比例的影響。
圖7分別顯示了隨機特徵模型(左)和完全訓練的神經網絡(右)的結果,探究合成數據比例的影響。兩種情況基本一致,除非P_2接近0,否則模型就逐漸脫離Scaling Law的軌跡,逐漸拉平成為一條水平線,即MSE損失不再隨樣本增加而降低,意味著出現了模型崩潰。
 相比圖7的小模型和小數據集,圖8使用的BabiStories數據集和GPT-2模型更接近現實中的複雜情況。
相比圖7的小模型和小數據集,圖8使用的BabiStories數據集和GPT-2模型更接近現實中的複雜情況。可以看到,即便是少量的合成數據也會延遲Scaling Law的進展,作者預計,這最終會導致最終Scaling Law提前達到飽和狀態或至少出現非常糟糕的指數(即小指數)。
圖8(右)所示的關於模型尺寸的影響。在數據集的某個閾值前,較大/較深的模型保持較低的測試損失;但超過一定閾值後,較小的模型反而由於減少過擬合而佔了上風。
這表明,較大的模型往往會將模型崩潰放大到某個插值的閾值之外。
 BabiStories包含Mixtral-8x7B生成的高質量合成數據
BabiStories包含Mixtral-8x7B生成的高質量合成數據數據混合,能否防止LLM崩潰?
如上,作者分別從理論、實證上,證實了強模型崩潰所在。
接下來,他們將通過合成數據策略,探索如何緩解模型崩潰這一現象。
這裏首先假設有關於數據源的明確信息,並使用兩種數據混合方法:
1 加權數據混合
2 戰略性迭代混合
加權單步數據混合
為了研究學習真實數據和替代數據(例如合成數據)混合的scaling law,考慮的設置需包括以下優化問題:

結果如下所示,真實數據+模擬數據混合法,無法解決模型崩潰問題。
在實驗中,作者使用了多個不同的真實數據n1和合成數據n2的大小值。

動態/多步數據混合
迭代混合恢復了scaling law,但在實踐中可能不可行。
研究人員觀察到,在t次迭代(t的數量級為log(n/d))的迭代混合後,會得到與E成比例的縮放規律,這在圖10中得到了經驗證實。
然而,這需要付出顯著的自舉(bootstrapping)成本,大量的真實數據,以及在多次迭代中清晰區分真實和合成數據的能力——這些條件在實踐中都過於計算密集且難以實現。

而且,迭代混合主要依賴真實數據。
在圖10中,研究人員比較了迭代混合的scaling效果,與僅使用同一訓練集中

部分真實數據(Clean)所獲得的scaling效果。
雖然scaling率保持一致,但迭代混合的表現始終不如單獨使用真實數據。
這表明迭代混合可能主要是中和了合成數據,並嚴重依賴真實數據來恢復scaling效果。
即使原始合成數據質量很高(即當
很小時,如圖10最右側所示),迭代方法也未能有效利用合成數據,導致性能比單次混合更差。
因此,儘管迭代混合恢復了相同的scaling率,模型仍在某種程度上發生了崩潰,並且沒有觀察到顯著的性能改善。
最後,研究人員還證明了,與少量實際數據進行迭代混合,也是會導致模型崩潰。
總而言之,這項研究系統地描述了真實、合成數據混合,訓練模型的效果,表明了模型崩潰是一種穩健的現象,即使在合成數據比例很小的情況下。
作者介紹
Elvis Dohmatob

2021年,Elvis Dohmatob加入了FacebookAI Research(FAIL)成為一名研究員。在此之前,他曾在INRIA、Criteo擔任過研究員。
他的研究興趣包括:深度學習(主要是理論方面)、穩健優化等等。
Yunzhen Feng(馮韞禛)

Yunzhen Feng目前是紐約大學數據科學中心數學和數據組的博士生,導師是Julia Kempe教授。在Meta的FIRE實習期間,與Yann Olivier博士共事。
目前,他的研究興趣在於:1)改進的科學推理方法,2)強化學習和測試時間優化,3)人工智能合成數據對當代學習範式的影響。
他曾在2021年獲得北大數院應用數學學士學位,導師是Bin Dong教授。
Arjun Subramonian

Arjun Subramonian目前是UCLA計算機科學理論博士生,並在Meta實習。
他的博士研究重點是圖神經網絡中社會不公平的理論基礎,對利用譜圖理論和統計學來表徵圖的結構屬性如何導致算法不公平感興趣。
Julia Kempe

Julia Kempe是紐約大學數據科學中心和Courant數學科學研究所計算機科學、數學和數據科學的銀牌教授,也是Meta Fair的客座高級研究員。
參考資料:
https://x.com/dohmatobelvis/status/1844300320811241477



















