蘋果多模態模型大升級!文本密集、多圖理解,全能小鋼炮

新智元報導
編輯:alan
【新智元導讀】近日,一向畫風精緻的「蘋果牌AI」,也推出了升級版的多模態大模型,從1B到30B參數,涵蓋密集和專家混合模型,密集文本、多圖理解,多項能力大提升。
多模態大語言模型(MLLM)如今已是大勢所趨。
過去的一年中,閉源陣營的GPT-4o、GPT-4V、Gemini-1.5和Claude-3.5等模型引領了時代。
而開源MLLM也同樣在蓬勃發展,LLaVA系列,InternVL2,Cambrian-1和Qwen2-VL的強勁表現,讓作為老大哥的GPT-4o時常躺槍。

開源與閉源之間差距縮小,兼具單圖、多圖、影片理解能力的MLLM也成為大家研究的重點。
說到潮流,怎麼能沒有蘋果的一席之地?
近日,一向畫風精緻的「蘋果牌AI」,也推出了升級版的多模態大模型——MM1.5。
 論文地址:https://arxiv.org/pdf/2409.20566
論文地址:https://arxiv.org/pdf/2409.20566MM1.5以前代MM1模型為基礎,採用數據為中心的方法進行訓練,顯著增強了文本密集型圖像理解、視覺指代和定位、以及多圖像推理的能力。
MM1.5系列的參數量從1B到30B,涵蓋密集和專家混合(MoE)模型,即使較小的尺寸也有優異的表現。
具體來說,MM1.5提升了OCR(光學字符識別)能力,支持任意圖像長寬比和高達4M像素的解像度,並且擅長理解富含文本的圖像。

在強大而細粒度的圖像理解能力加持下,MM1.5能夠超越文本提示來解釋視覺內容,例如點和邊界框。

研究人員還通過對額外的高質量多圖像數據進行監督微調(SFT),進一步提高了模型的上下文學習和開箱即用的多圖像推理能力。

本文作者重點關注兩種小規模的MLLM,包括1B和3B的密集模型與MoE模型,其中小尺寸的密集模型可以輕鬆部署在移動設備上。
「小模型」也符合蘋果一貫的作風,在自家的各種設備上,能夠更好地與用戶場景(如隱私和安全性)融為一體。
之前微軟和蘋果的很多實踐也證明了,利用高質量數據和先進的訓練策略,小個子的模型在各種下遊任務中同樣表現強勁,足以超越大尺寸的模型。

當然了,光是小還不夠,通用性更為重要。
MM1.5系列模型在30B參數的範圍之內,都能很好地符合縮放定律,模型越大,性能越強。
另一方面,研究人員以MM1.5為基礎,微調出服務於影片理解的MM1.5-Video,以及為移動UI(比如iPhone屏幕)理解定製的MM1.5-UI。
模型構建
MM1.5保留了與MM1相同的模型架構,並將改進的努力集中在以下幾個關鍵方面:
持續的預訓練
作者在SFT階段之前引入了一個額外的高解像度連續預訓練階段,這對於提高富含文本的圖像理解性能至關重要。
作者探索了用於持續預訓練的富含文本的OCR數據,重點關注圖像中文本的詳細轉錄,還嘗試了高質量的合成圖像字幕。
SFT
混合中的每一類SFT數據如何影響最終模型的性能?特別是支持每種功能的數據對其他功能有何影響,作者對此進行了廣泛的消融實驗。
動態高解像度
對於高解像度圖像編碼,作者遵循流行的任意解像度方法,將圖像動態劃分為子圖像,並進行徹底的消融以細化設計中的關鍵細節。
為了保留前代模型的零樣本和少樣本學習能力,並更有效地將它們轉移到SFT階段,在開發MM1.5時,研究人員通過探索純文本數據的影響,並優化不同預訓練數據類型的比例,來進一步擴展MM1的預訓練。
這種方法提高了知識密集型基準測試的性能,並增強了模型整體的多模態理解能力。

如上圖所示,模型訓練包含三個階段:
(i) 使用低解像度圖像 (378×378) 進行大規模預訓練;
(ii) 使用高解像度(高達4M像素)OCR數據和合成字幕進行持續預訓練;
(iii) 監督微調(SFT)。
在每個階段,都需要確定最佳數據組合併評估每種數據類型的影響。
消融實驗設置
在消融研究中遵循以下預設設置:
靜態圖像分割通過4個子圖像分割(加上一個概覽圖像)來實現,並且每個子圖像通過位置嵌入插值調整為672×672解像度。為了加快實驗迭代速度,在消融過程中沒有使用動態圖像分割。
對於多圖像數據的編碼,僅噹噹前訓練樣本包含少於三幅圖像時才啟用圖像分割,以避免序列長度過長。
如下圖所示,模型可以以引用坐標和邊界框的形式,解釋對輸入圖像中的點和區域的引用。

MM1.5採用與前代相同的CLIP圖像編碼器和LLM主幹網絡,並以C-Abstractor作為視覺語言連接器。
對於連續預訓練和SFT,作者將批量大小設置為256。使用AdaFactor優化器,峰值學習率為1e-5,餘弦衰減為0。對於連續預訓練,最多訓練30k步。在SFT期間,所有模型都針對一個epoch進行優化。
模型使用MM1的預訓練檢查點進行初始化。這個階段對45M高解像度OCR數據(包括PDFA、IDL、Renderedtext和DocStruct-4M)進行持續的預訓練,每個訓練批次從這四個數據集中均勻采樣數據。

與SFT階段類似,作者使用靜態圖像分割,將每個圖像分為五個子圖像,每個子圖像的大小調整為672×672解像度。作者發現這種高解像度設置對於持續預訓練至關重要。
最後,將數據集分組有助於數據平衡和簡化分析。在較高層面上,作者根據每個示例中呈現的圖像數量將數據集分為單圖像、多圖像和純文本類別,詳細的分類情況如下圖所示:
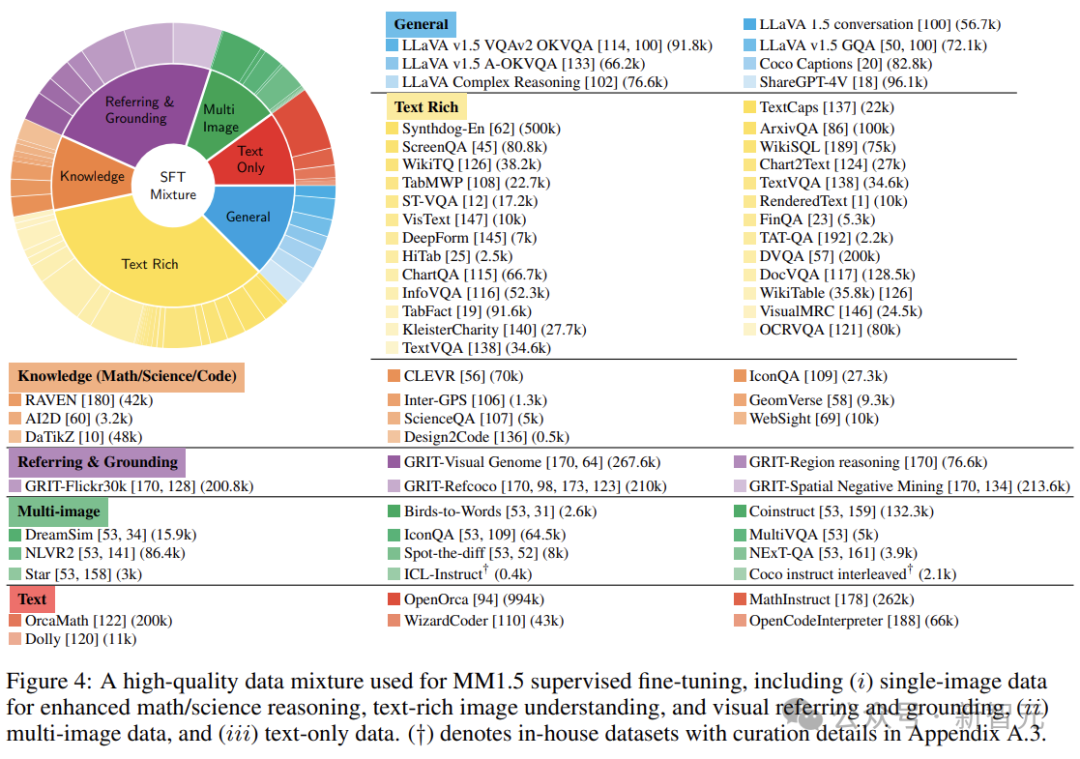
研究人員根據主要衡量的功能將基準分為幾類,並提出類別平均分數(每個子類別的所有基準數字的平均分數),以代表該功能的平均性能。
SFT消融
然後是對於SFT數據混合的全面消融。作者首先評估一般數據類別,然後逐步評估單獨添加其他子類別的影響。
在訓練過程中,作者混合來自不同子類別的數據,通過從混合物中隨機采樣數據來構建每個訓練批次,並使用類別平均得分來比較使用每種功能的模型,結果如下圖所示。

作者觀察到,添加富含文本的數據可以顯著提高文本密集型和知識基準的性能,數學數據也遵循類似的趨勢。
以一般數據類別為參考,對目標類別數據進行上采樣/下采樣,使得在每個訓練批次中,一般數據類別和目標類別的數據比例為1:α。
為了衡量α的平均影響,作者提出MMBase分數用於模型比較。如下圖所示,作者針對不同的數據類別改變α。對於科學、數學和代碼類別,作者發現α的最佳比率分別為0.1、0.5和0.2。

下一項需要探究的是單圖像、多圖像和純文本數據的混合比例。
枚舉三個比率之間的所有組合將產生大量的計算成本。因此,作者分別對純文本數據和多圖像數據進行消融,以評估模型對比例的敏感程度。
對於純文本數據,作者測試了0到0.2的範圍,下圖結果表明,不同的w值對模型的基礎影響較小。
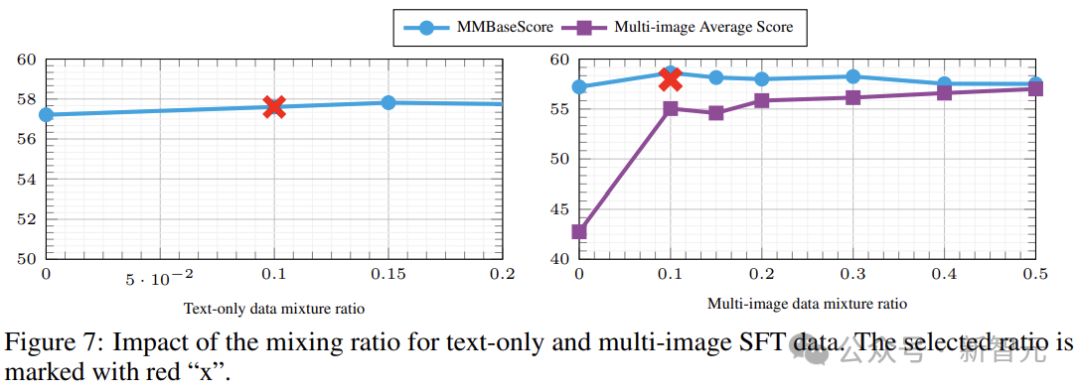
通過圖7(右)還可以觀察到,增加多圖像數據的采樣率會導致基本功能的性能下降(MMBase分數減少),而多圖像平均分數會增加。所以作者選擇w= 0.1為單圖像數據分配更高的權重,以提高潛在的性能。
基於上述研究,作者提出了三種混合:基礎混合、單圖像混合、全混合。
下圖前三列表明,包含參考數據和多圖像數據會稍微降低密集文本、知識和一般基準的平均性能。

最後一欄表明,作者優化的組合實現了最佳的整體性能,平衡了基準測試中的所有功能。

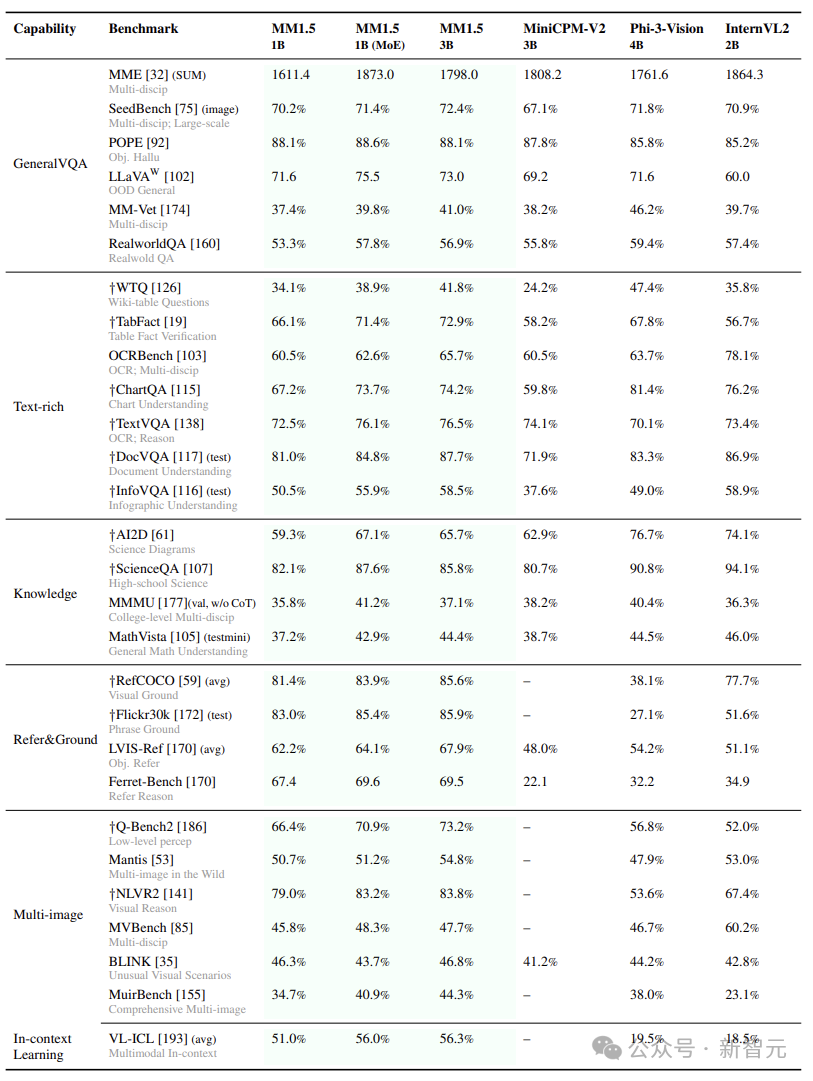
最後,放幾張跑分對比,包括Text-rich、In Context Learning和Multi-image:


 參考資料:
參考資料:https://arxiv.org/pdf/2409.20566



















