圖靈獎得主Yoshua Bengio新作:Were RNNs All We Needed?
機器之心報導
編輯:佳琪、蛋醬
自從 Transformer 模型問世以來,試圖挑戰其在自然語言處理地位的挑戰者層出不窮。
這次登場的選手,不僅要挑戰 Transformer 的地位,還致敬了經典論文的名字。
再看這篇論文的作者列表,圖靈獎得主、深度學習三巨頭之一的 Yoshua Bengio 赫然在列。

-
論文標題:Were RNNs All We Needed?
-
論文地址:https://arxiv.org/pdf/2410.01201v1
最近,大家重新對用循環序列模型來解決 Transformer 長上下文的問題產生了興趣,出現了一大批有關成果,其中 Mamba 的成功引爆了 AI 圈,更是點燃了大家的研究熱情。
Bengio 和他的研究團隊發現,這些新的序列模型有很多共同點,於是他們重新審視了 LSTM 和 GRU 這兩種經典 RNN 模型。
結果發現,精簡掉其中的隱藏狀態依賴之後,不再需要基於時間反向傳播的 LSTM 和 GRU 的表現就能和 Transformer 打個平手。
LSTM 和 GRU 僅能順序處理信息,並且在訓練時依賴反向傳播,這使得它們在處理大量數據時速度緩慢,最終被淘汰。
基於以上發現,他們進一步簡化了 LSTM 和 GRU,去掉了它們對輸出範圍的限制,並確保它們的輸出在時間上是獨立的,進而得到了 minLSTM 和 minGRU。
相比傳統 RNN,它們不僅訓練時所需的參數顯著減少,還可以並行訓練,比如上下文長度為 512 時,速度能提升 175 倍。
這其實也是 Bengio 長期關注 RNN 的系列研究成果。在今年五月,Bengio 及其研究團隊和加拿大皇家銀行 AI 研究所 Borealis AI 合作發佈了一篇名為《Attention as an RNN》的論文。
正如論文名字所示,他們將注意力機制重新詮釋為一種 RNN,引入了一種基於並行前綴掃瞄(prefix scan)算法的新的注意力公式,該公式能夠高效地計算注意力的多對多(many-to-many)RNN 輸出。基於新公式的模塊 Aaren,不僅可以像 Transformer 一樣並行訓練,還可以像 RNN 一樣高效更新。
簡化 LSTM 和 GRU
在這一部分,研究者通過簡化和移除各種門中的若干隱藏狀態依賴關係,證明 GRU 和 LSTM 可通過並行掃瞄進行訓練。
在此基礎上,研究者進一步簡化了這些 RNN,消除了它們對輸出範圍的限制(即 tanh),並確保輸出在規模上與時間無關。
綜合上述步驟,研究者提出了 GRUs 和 LSTMs 的最小版本(minGRUs 和 minLSTMs),它們可通過並行掃瞄進行訓練,且性能可與 Transformers 和最近提出的序列方法相媲美。
minGRU
研究者結合了兩個簡化步驟,得到了一個極簡版的 GRU(minGRU)。

由此產生的模型比原始 GRU 效率大大提高,只需要

個參數,而不是 GRU 的

個參數(其中 d_x 和 d_h 分別對應於 x_t 和 h_t 的大小)。在訓練方面,minGRU 可以使用並行掃瞄算法進行並行訓練,從而大大加快訓練速度。
在實驗部分,研究者展示了在 T4 GPU 上,當序列長度為 512 時,訓練步驟的速度提高了 175 倍。參數效率的提高也非常顯著。通常,在 RNN 中會進行狀態擴展(即
,其中 α ≥ 1),使模型更容易從輸入中學習特徵。
minLSTM
研究者結合了三個簡化步驟,得到 LSTM 的最小版本(minLSTM):

與 LSTM 的

相比,最小版本(minLSTM)的效率明顯更高,只需要

個參數。此外,minLSTM 可以使用並行掃瞄算法進行並行訓練,大大加快了訓練速度。例如,在 T4 GPU 上,對於長度為 512 的序列,minLSTM 比 LSTM 加快了 235 倍。在參數效率方面,當 α = 1、2、3 或 4(其中
)時,與 LSTM 相比,minLSTM 僅使用了 38%、25%、19% 或 15% 的參數。
Were RNNs All We Needed?
在本節中,研究者將對最小版本(minLSTMs 和 minGRUs)與傳統版本(LSTMs 和 GRUs)以及現代序列模型進行了比較。
Minimal LSTMs 和 GRU 非常高效
在測試時,循環序列模型會按順序推出,從而使其推理更為高效。相反,傳統 RNN 的瓶頸在於其訓練,需要線性訓練時間(通過時間反向傳播),這導致其最終被淘汰。人們對循環序列模型重新產生興趣,是因為許多新的架構可以高效地進行並行訓練。
研究者對比了訓練傳統 RNN(LSTM 和 GRU)、它們的最小版本(minLSTM 和 minGRU)以及一種最新的序列模型所需的資源,還特別將重點放在與最近大受歡迎的 Mamba 的比較上。實驗考慮了 64 的批大小,並改變了序列長度。研究者測量了通過模型執行前向傳遞、計算損失和通過後向傳遞計算梯度的總運行時間和內存複雜度。
運行時間。在運行時間方面(見圖 1(左)),簡化版 LSTM 和 GRU(minLSTM 和 minGRU)Mamba 的運行時間相近。對 100 次運行進行平均,序列長度為 512 的 minLSTM、minGRU 和 Mamba 的運行時間分別為 2.97、2.72 和 2.71 毫秒。
對於長度為 4096 的序列,運行時間分別為 3.41、3.25 和 3.15 毫秒。相比之下,傳統的 RNN 對應程序(LSTM 和 GRU)所需的運行時間與序列長度成線性關係。對於 512 的序列長度,在 T4 GPU 上,minGRUs 和 minLSTMs 每個訓練步驟的速度分別比 GRUs 和 LSTMs 快 175 倍和 235 倍(見圖 1(中))。隨著序列長度的增加,minGRUs 和 minLSTMs 的改進更為顯著,在序列長度為 4096 時,minGRUs 和 minLSTMs 的速度分別提高了 1324 倍和 1361 倍。因此,在 minGRU 需要一天才能完成固定數量的 epoch 訓練的情況下,其傳統對應的 GRU 可能需要 3 年多的時間。

內存。通過利用並行掃瞄算法卡奧效地並行計算輸出,minGRU、minLSTM 和 Mamba 創建了一個更大的計算圖,因此與傳統的 RNN 相比需要更多內存(見圖 1(右))。與傳統的 RNN 相比,最小變體(minGRU 和 minLSTM)多用了 88% 的內存。與 minGRU 相比,Mamba 多用了 56% 的內存。但實際上,運行時間是訓練 RNN 的瓶頸。
刪除

的效果。最初的 LSTM 和 GRU 使用輸入 x_t 和之前的隱藏狀態
計算各種門電路。這些模型利用其與時間依賴的門來學習複雜函數。然而,minLSTM 和 minGRU 的訓練效率是通過放棄門對之前隱藏狀態
的依賴性來實現的。因此,minLSTM 和 minGRU 的門僅與輸入 x_t 依賴,從而產生了更簡單的循環模塊。因此,由單層 minLSTM 或 minGRU 組成的模型的柵極是與時間無關的,因為其條件是與時間無關的輸入

與時間無關,但其輸出

與時間有關,並被用作第二層的輸入,即
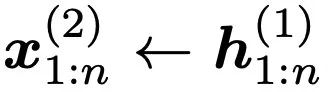
。因此,從第二層開始,minLSTM 和 minGRU 的門也將隨時間變化,從而建立更複雜的函數模型。表 1 比較了不同層數的模型在 Mamba 論文中的選擇性複製任務上的表現。可以立即看出時間依賴性的影響:將層數增加到 2 層或更多,模型的性能就會大幅提高。

訓練穩定性。層數的另一個影響是穩定性增強,隨著層數的增加,準確率的差異減小(見表 1)。此外,雖然 minLSTM 和 minGRU 都能解決選擇性複製任務,但可以看到 minGRU 是一種經驗上比 minLSTM 更穩定的方法,它能以更高的一致性和更低的方差解決該任務。在訓練過程中,這兩組參數的調整方向不同,使得比率更難控制和優化。相比之下,minGRU 的信息丟棄和添加由單組參數(更新門)控制,因此更容易優化。
Minimal LSTMs 和 GRUs 表現良好
上述內容展示了簡化傳統 RNN 所帶來的顯著效率提升。這部分將探討最小版本的 LSTM 和 GRU 與幾種流行的序列模型相比的經驗性能。
選擇性複製。此處考慮 Mamba 論文中的長序列選擇性複製任務。與最初的複製任務不同,選擇性複製任務的輸入元素相對於輸出元素是隨機間隔的,這增加了任務的難度。為瞭解決這個任務,模型需要進行內容感知推理,記憶依賴的 token 並過濾掉不依賴的 token。
表 2 將簡化版的 LSTM 和 GRU(minLSTM 和 minGRU)與可以並行訓練的著名循環序列模型進行了比較:S4、H3、Hyena 和 Mamba (S6)。這些基線的結果引自 Mamba 論文。在所有這些基線中,只有 Mamba 論文中的 S6 能夠解決這一任務。minGRU 和 minLSTM 也能解決選擇性複製任務,其性能與 S6 相當,並優於所有其他基線。LSTM 和 GRU 利用內容感知門控機制,使得這些最小版本足以解決許多熱門序列模型無法解決的這一任務。

強化學習。接下來,研究者討論了 D4RL 基準中的 MuJoCo 運動任務。具體來說考慮了三種環境:HalfCheetah、Hopper 和 Walker。對於每種環境,模型都在三種不同數據質量的數據集上進行訓練:中等數據集(M)、中等遊戲數據集(M-R)和中等專家數據集(M-E)。
表 3 將 minLSTM 和 minGRU 與各種 Decision Transformer 變體進行了比較,包括原始 Decision Transformer (DT)、Decision S4 (DS4)、Decision Mamba 和(Decision)Aaren。minLSTM 和 minGRU 的性能優於 Decision S4,與 Decision Transformer、Aaren 和 Mamba 相比也不遑多讓。與其他循環方法不同,Decision S4 是一種循環轉換不感知輸入的模型,這影響了其性能。從 3 × 3 = 9 個數據集的平均得分來看,minLSTM 和 minGRU 優於所有基線方法,只有 Decision Mamba 的差距很小。

語言建模。研究者使用 nanoGPT 框架對莎士比亞作品進行字符級 GPT 訓練。圖 2 用交叉熵損失繪製了學習曲線,將所提出的最小 LSTM 和 GRU(minLSTM 和 minGRU)與 Mamba 和 Transformers 進行了比較。結果發現,minGRU、minLSTM、Mamba 和 Transformers 的測試損失相當,分別為 1.548、1.555、1.575 和 1.547。Mamba 的表現略遜於其他模型,但訓練速度更快,尤其是在早期階段,在 400 步時達到最佳表現,而 minGRU 和 minLSTM 則分別持續訓練到 575 步和 625 步。相比之下,Transformers 的訓練速度明顯較慢,需要比 minGRU 多 2000 步(∼ 2.5 倍)的訓練步驟才能達到與 minGRU 相當的性能,這使得它的訓練速度明顯更慢,資源消耗也更大(與 minGRU、minLSTM 和 Mamba 的線性複雜度相比,Transformers 的複雜度為二次方)。

更多研究細節,可參考原論文。




















