一句廢話就把OpenAI o1干崩了?大模型的推理能力還真挺脆弱的
就在一個月前,OpenAI悄悄發佈了o1,o1的推理能力是有目共睹的。
我當時用了幾個很難很難的測試樣例去試驗了一下,很多模型見了都會犯怵,開始胡說八道。
最難的其中一個是薑萍奧賽的那個數學題,幾乎暴揍所有大模型的那個題,交給o1,o1竟然完完全全答對了。
如果你還記得,我在那篇文章最後給大家放了OpenAI給出的提示詞的最佳寫法。
其中第一條就是:
保持提示詞簡單直接:模型擅長理解和相應簡單、清晰的指令,而不需要大量的指導。
當時我對這一條的理解,覺得是為了讓o1模型更好地理解我的要求,同時可以加快模型的處理速度,因為模型不需要花費額外的時間去解析複雜的語句。
直到我刷到前兩天蘋果放出來的一篇LLM的研究論文,我才意識到,多加一兩句無關緊要的和目標無關的話,別說奧賽題了,可能模型連小學數學題都做不對了。真的。
這篇論文就是:

GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models (翻譯過來即:理解大語言模型在數學推理的局限性)
看著好像天書,別慌,其實非常簡單,我都能看懂,你肯定也行。
這篇論文想研究的一個核心問題是:
這些模型是否真正具備邏輯推理能力?尤其是在數學推理任務中。
這其實也是我一直很想知道的。
對於我們人類來說,我們會根據複雜的環境和已知的一些條件每時每刻做出當下的行動選擇,就是因為我們可以通過演繹、歸納、溯因等方式時時刻刻做推理。
比如鮮蝦包時不時在我評論區謬讚我的文章——推理出他對我的文章是真愛。
而對於現在的大語言模型來說,主流的評估方式是通過設計一系列邏輯推理任務,包括但不限於數學問題、邏輯謎題、推理判斷等,然後讓模型嘗試解決這些任務。
其中一個非常重要的數據集是GSM8K,你可以在很多的模型的性能榜單介紹里看到這個數據集,是一個聚焦小學數學題的一個數據集。
你沒看錯,就是小學數學。雖小但是博大精深。
這篇論文就圍繞這個數據集展開諸多的實驗,做了自己的擴展。其中我覺得最有趣的,當屬下面這個實驗:
就是通過魔改GSM8K,來向小學數學問題添加一些無關緊要的一個信息,來測試模型的推理成功率。然後就會發現,大模型推理的成功率,直接大幅下降。

比如原本的問題是:
-
鮮蝦包去農貿市場買蔬菜,他買了4公斤西紅柿和6公斤土豆。西紅柿每公斤6元,土豆每公斤3元。請問鮮蝦包在西紅柿上比土豆多花了多少錢?
很簡單,對不對,你交給大語言模型,大語言模型會說:「就這?輕輕鬆鬆」,幾乎誰都能答得上來。
但是如果你加一句無關的話,變成:
-
鮮蝦包去農貿市場買蔬菜,他買了4公斤西紅柿和6公斤土豆。西紅柿每公斤6元,土豆每公斤3元。然後他把1公斤西紅柿和2公斤土豆送給了卡茲克。請問鮮蝦包買西紅柿上比土豆多花了多少錢?
我們一眼就可以看出來:送不送卡茲克和鮮蝦包花的錢沒有任何關係,答案肯定是不變的。
但如果這樣的話,AI就懵逼了。就可能會給你開始算錯了,算對的成功率就會開始給你降低了。
這個結論非常有意思,但是論文歸論文,我們肯定還是要自己測試一下的。
所以第一時間,我打開各大平台開始著手測試。當然為了讓他更像小學題,我們的主角換成了小明,相信大家童年的數學都離不開小明。
題目設定為:
-
小明想購買一些學習用品。他購買了24個現在每個賣6元的橡皮擦,10本現在每本賣11元的筆記本,以及現在賣19元的複印紙,假設由於通貨膨脹,去年的價格便宜10%,現在小明應該支付多少?
明眼人都能看出來,通貨膨脹這個信息,跟題目其實沒任何關係,所以最終答案是:24×6+10×11+19=273元。
首先出戰選手GPT4o。

直接GG了,得出來了245.7的結論。
第二位出戰選手Gemini 1.5 pro-002,繼續陣亡。

第三位選手曆戰先鋒Claude3.5,開局也是一個死。

就連推理之王OpenAI o1,上來也居然翻了個跟頭了,第二把才開始對。

真的,這就是一個純純的小學數學題啊,再難一點都沒有。
只是加了一個無關條件,就全部翻車……全軍附魔(不,覆沒)。
這次我們換個背景,愛學習的小明去春遊玩。
題目設定是:
-
四年級一班準備去郊遊,每位學生要繳納 35 元 活動費。班里有 42 名學生參加。老師還向學校申請了 300 元 額外補助。
用於租車的費用是 1200 元。午餐費用為每人 25 元。班主任自己還個人給大家買了250元錢的零食。
問題:班級的活動經費夠嗎?還剩多少錢?
答案很簡單,班主任那個250塊錢的零食是自己出的,跟活動經費沒關係,所以是35*42+300-1200-25*42=-480
首先出戰老哥還是GPT4o,果然,炮灰一個,一邊玩去吧。

二等兵Gemini 1.5 Pro-002直接躺屍。
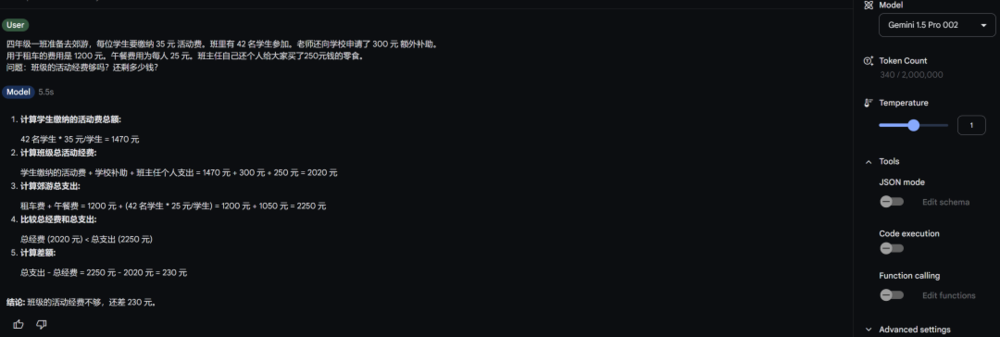
三弟Claude3.5也陪二位大哥一程,一家人就要掛得整整齊齊。

o1老大哥在小弟集體陣亡之下,還是扳回了一城,沒有給AI過於丟臉,我尊稱一句黑神話o1。

真的,這場面實在太慘烈了。大模型的推理能力,比我們想像的,還要脆弱不堪。
我還隨手測了幾個題,也是論文的case,會發現模型們也跌跌撞撞,時不時就出錯。
比如這道經典的鮮蝦包送醬油題。
-
超市里,每袋大米售價 50 元,每瓶醬油售價 10 元。如果鮮蝦包購買了 4 袋大米和 4 瓶醬油,並且送給鄰居1袋大米和2瓶醬油,那麼鮮蝦包購買大米比醬油多花了多少錢?
答案很簡單,50×4-4×10=160元。鮮蝦包送鄰居大米和醬油只能說明他是個好人,跟他多花多少錢半毛錢關係都沒有。
而大哥o1,直接連續陣亡4次……

而且擺爛中文都不打了,還非要送人,直接把自己都送進去了。
反而是你三弟Claude3.5沒掉進陷阱里,還對了幾次。可能它不喜歡鮮蝦包送人大米和醬油?

諸如此類,不計其數。
這個發現實在是太有意思了。
而且跟我過去用AI寫文章、作圖、做影片而感受到的體感相似。那就是:
我對AI的理解就像對一位熟練工匠的看法。它能嫻熟地應對曾經接觸過的工作,就如同老匠人精通自己的傳統手藝。但是,面對全新的挑戰,無論看似多麼簡單,它也經常可能束手無策。這並非源於任務本身的難易,而是由它對該領域的熟練程度決定。
就像那句老話:熟能生巧,AI的能力很多時候都體現在經驗的積累,而非臨場的智慧。
蘋果的這篇論文中,也有類似的描述:
我們還研究了這些模型在數學推理方面的脆弱性,並證明隨著問題中子句數量的增加,它們的表現顯著惡化。我們假設這種下降是因為當前的LLMs無法進行真正的邏輯推理;相反,它們試圖複製在訓練數據中觀察到的推理步驟。當我們添加一個看似與問題相關的單一子句時,我們觀察到所有最先進模型的表現顯著下降(最高可達 65%),儘管所添加的子句並未對達到最終答案所需的推理鏈作出貢獻。
現在的AI,並不是在真正的推理,而是試圖複製在訓練數據中所觀察到的推理步驟。
一句無關緊要的話,就能把大模型徹底干廢。
就像AI屆的老OG總是不斷地在懟如今的大模型,他總是喜歡用貓做隱喻。
他說,貓對物理世界有心理模型,具備持久的記憶、一定的推理能力和規劃的能力。
「但是,今天的「前沿」人工智能,包括 Meta 自己製造的,都不具備這些特質。」
AI真的沒有進行推理嗎?也許是。
它們不能推理嗎?沒有人知道。
但至少,回到最開始那個OpenAI提示詞建議,你會發現提示詞簡潔乾淨,避免無關的提示多麼重要。
除此之外,論文中還有一些其他比較重要的結論:
-
隨著問題難度的提升,如增加更多句子,模型的表現迅速下降;
-
有時候改變數值也會導致推理結論變化,比如把每袋大米改為60元;
-
改變名詞也會導致結論變化,比如把小明改為小紅。
以上種種都表明,這些大語言模型在推理複雜問題時非常脆弱。
現實生活中,種種複雜的情況,隨時存在的干擾還依然是大語言模型自己感覺頭疼的地方,他們不會理解為什麼要給鄰居送大米,不會理解鮮蝦包為什麼熱衷給我評論。如果讓他們看鮮蝦包的評論,他們肯定完全推理不出他對我文章的喜愛,相反他們一定以為是批評我的文章。
所以感歎造物主還是非常牛叉的。確實,現在o1可以做出非常驚豔的推理,甚至解決那些我不會的奧賽題,幫助人類發現科學規律,但是他們依然不能理解人類的種種複雜的行為和充滿變數的環境,和基於這些的可能出現的推理。
但是那些模型相比曾經的自己,已經成長了太多太多。
我們甚至都不知道。
未來的他們,到底會不會推理。
也許,他們會。
但卻是以我們尚未識別或無法控制的方式。
那時,新的神。
就誕生了。
本文來自微信公眾號:數字生命卡茲克,作者:卡茲克、Qodicat



















