20個群都來問我的AI早報,是這麼做的。
我自己的AI群裡,一直有一個傳統,就是每天早上,都會發一個AI早報,讓群友瞭解昨天AI圈發生了一些什麼大事。
就是這個東西。

從去年到今天,總有群友在問我每天的AI早報是咋做的。

其實吧,在國慶之前呢,都是5群的一個朋友@日不落太陽做的,他每天早上會發到5群裡,我每天只是負責轉發= =
那時候吧,其實也想著,不能總是依賴別人,這種東西最好還是自己做一個,不能老是麻煩別人。
但是吧,我自己本身就很忙,一來二去,就一直拖拖拖。
然後問題開始在時間的不確定性。有時早上9點就能收到早報,有時卻要等到11點之後,早報直接變午報了。群友們的催促聲此起彼伏,我只能尷尬地重覆著等等= =

壓倒我的最後一根稻草是國慶假期。那個早晨,我如往常一樣等待日報,卻遲遲未收到。
然後聯繫那位朋友才知道,他去旅遊了,時差都快干鏡像了,實在是無暇顧及早報。
所以,那天之後,我痛定思痛,決定還是自己來造一個吧。
既然自己做,那肯定不能天天自己手動整理,那也太der了,必定是先抓取各種各樣的數據源,然後全自動化的用AI總結。最後人轉到群裡。
之所以用人不用那種微信機器人,是我怕封號+炸群。
說干就干,我順藤摸瓜,反向搜索@日不落太陽最後發的內容,並找到儘可能早的信息來源。
然後就找到了一個AIBase.com,信息還挺全的。
仔細觀察後發現,這個網站的頁面結構很規律,新聞鏈接都是按數字遞增的。

這也太適合抓取了。。。
但是這次我吸取了上次的教訓,之前有一期做快手AI短劇評論分析的時候,買了八爪魚的軟件會員,一個月400,然後就沒什麼用了,後面再用還得開會員,虧死我了。
這次,我就想直接搞個python代碼一勞永逸。
我對代碼可以說一竅不懂,直懂一點Html和css的基礎知識,所以為了搞掂這個項目,我先在網上隨手找了一個爬蟲代碼,交給ChatGPT,希望他能按我給的URL修改。

但是,當我滿懷期待地放到本地運行它時,就是一頓哐哐報錯。。
跟ChatGPT溝通了半天,也搞不定問題,真的愁死我了,還直接給我o1的次數干乾淨了。
還好當天晚上,天降神兵,我跟朋友簡單「抽水」了兩句後,他給我發了個神器。
Crawl4ai。
就是下面這個star增長像火箭一樣的項目。

網址在此:https://github.com/unclecode/crawl4ai
Crawl4ai大大簡化了使用抓取內容所需要配置的步驟。
只需要十幾行代碼就能跑起來一個最簡單的項目。
比如下面這個快速開始的示例。

安裝也很簡單。
只有一行代碼。

然後我把特定的一個信息源的文章詳情地址替換進去。
牛批起飛,直接能爬下來了。

但是數據展示很混亂,我們肯定希望標題是單獨一行,時間是單獨一行,內容是單獨一行,現在直接糊成一坨了。
我這次實在不想指望AI了,直接求助朋友了。
很快,他就幫我搞掂了。
代碼我貼在下面了。
import json
import asyncio
from crawl4ai import AsyncWebCrawler
from crawl4ai.extraction_strategy import JsonCssExtractionStrategy
asyncdefextract_ai_news_article():
print(“\n— 使用 JsonCssExtractionStrategy 提取 AIbase 新聞文章數據 —“)
# 定義提取 schema
schema = {
“name”: “AIbase News Article”,
“baseSelector”: “div.pb-32”, # 主容器的 CSS 選擇器
“fields”: [
{
“name”: “title”,
“selector”: “h1”,
“type”: “text”,
},
{
“name”: “publication_date”,
“selector”: “div.flex.flex-col > div.flex.flex-wrap > span:nth-child(6)”,
“type”: “text”,
},
{
“name”: “content”,
“selector”: “div.post-content”,
“type”: “text”,
},
],
}
# 創建提取策略
extraction_strategy = JsonCssExtractionStrategy(schema, verbose=True)
# 使用 AsyncWebCrawler 進行爬取
asyncwith AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(
url=“https://www.aibase.com/zh/news/12386”, # 替換為實際的目標 URL
extraction_strategy=extraction_strategy,
bypass_cache=True, # 忽略緩存,確保獲取最新內容
)
ifnot result.success:
print(“頁面爬取失敗”)
return
# 解析提取的內容
extracted_data = json.loads(result.extracted_content)
print(f”成功提取 {len(extracted_data)} 條記錄”)
print(json.dumps(extracted_data, indent=2, ensure_ascii=False))
return extracted_data
# 運行異步函數
if __name__ == “__main__”:
asyncio.run(extract_ai_news_article())
直接跑一波,就可以獲得一篇文章的全文內容了。
效果很好,只有一處小bug。
閱讀時間和發佈時間沒有正確顯示。

不好意思再麻煩朋友了,我直接把整個網站的Html代碼和這段抓取的代碼,同時扔給了OpenAI o1,在思考了5秒後,他成功解決了這個錯誤。

刪去一些用不到的內容,下圖就是最後的輸出效果啦。
有標題,有時間,有內容。非常全面。
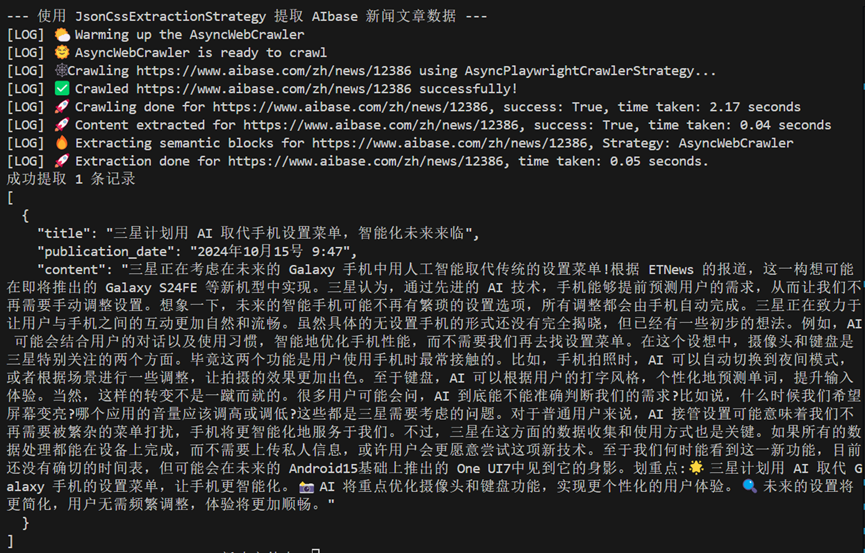
爬下來的內容會保存成一個JSON文件。
因為這個還是單個文章的方法,再做一個循環,不斷地抓就行。大概做了一個流程圖,如果有錯勿噴,我是一個純代碼小白。。。

接下來,終於到了我自己能解決的範圍里了,就是用AI,來總結這些抓取的內容。
因為每天都要輸出,大模型API還是挺重要的,需要便宜,不燒錢,而且畢竟就做個總結而已,我就選了智譜的GLM-4-Air的API,然後寫了一個prompt,讓模型自動把每條新聞概括成一句話。

這一步非常輕鬆,一個命令行版的AI日報工具就誕生了。
一般是每天早上8點左右會自動跑一遍程序,來找昨天早上8點到今天早上8點的所有新聞。
每次運行,它就會自動爬取最新新聞,用AI生成概要,然後在命令行里輸出結果。

我只需要複製到記事本里稍作排版,一份日報就大功告成了。
看著源源不斷湧現的新聞數據,我有種熱淚盈眶的感覺。
終於自己把這個小玩意幹出來了,可以自己每天跑早報,然後發給群友了。。。
但我很快意識到,這隻是開始。
因為每天這新聞也太特麼多了。。。
我自己篩選一遍,都特麼腦殼大。
然後壞消息總是一起到來,我的「得力助手」AIBase突然沒來由的,直接停更了。
行吧。。。
只能又重新找源了。
又找了一段時間,總算是讓我找到了一個更新速度飛快的科技新聞網站TechCrunch。
https://techcrunch.com/
然後防止他倆都不可靠,我又找了幾個其他的網站,來擴充我的數據源,甚至還花了2000多大洋買了個The Information和華爾街日報。

現在已經有了5個穩定的英文科技網站和3個中文AI資訊站作為背後的信息源,誰抽風一下,我也不慌了。
每天早上,我只需要打開電腦,運行一下腳本,新鮮出爐的AI新聞就會呈現在我面前。
然而,面對著黑乎乎的命令行界面,我總覺得少了點什麼。而且,每次都要人工手動複製到記事本編輯整理,那也太蠢了。
所以,重拾UI老本行,給它加個簡單的UI頁面吧,命令行界面,我實在扛不住。
我又開始了新一輪的折騰。
首先,我實現了每隔幾小時自動爬取一次新聞,並在網頁上顯示獲取到的內容。這下不用我盯著電腦看了,它會自動更新。
但是呢,雖然新聞自動更新了,我還是得手動複製到記事本里編輯。
於是為了把懶逼精神貫徹到底,我又加了個文本框,可以直接在網頁上編輯內容複製黏貼了。

可用著用著,我又覺得這個交互邏輯不夠順暢。
因為這還是得我自己複製再黏貼到這個網頁的文本框里,還是麻煩。
於是,想了一會,我又把概要做成了一個列表,每條新聞都有個複選框,我可以勾選最新最有趣的內容。它就會自動出現在右邊的預覽框里,可以實時預覽選中的內容。
然後再把編輯的文本框放在下面,根據勾選的內容自動加上日期和序號,再搞個一鍵複製按鈕,完成全傻瓜式AI早報製作。
還順便做了些小更新。
比如,為了便捷快速的調順序,又加了個拖動排序功能。

這下可好,鼠標點點選選就能搞掂一期日報,再也不用擔心被群友們催更了。
而我的電腦呢,就像個盡職盡責的小助手,每小時都會準時去各大網站巡邏一圈,看看有什麼新鮮有趣的AI新聞。
醜是稍微醜了點,但是反正自己用,就這樣也沒事,懶得改了哈哈哈。
再比如,隨著時間推移,我的JSON文件越來越大,加載速度也越來越慢。
為了提升用戶體驗,現學現賣,學著把數據遷移到了數據庫,並且每次只加載最新的50條新聞。這下加載速度嗖嗖的,用起來更順暢了。
經過這段時間的折騰,總算是「人工智能」了。
也能穩定每天早上給群友產出一份AI早報了,目前穩定運行15天,基本上沒有出任何岔子。
所以也敢寫下這篇文章,算是一個小小的複盤和總結。
人嘛,總是要不斷折騰不斷嚐鮮的。
就像馬斯克說的那一句:
成功了,就是進步的一大步。
失敗了也無所謂。
那也會是,夜空中最璀璨的星光。



















