大模型步入「推理Scaling」時代,SambaNova如何挑戰英偉達的霸主地位?
機器之心報導
作者:蛋醬
OpenAI o1 的發佈,再次給 AI 領域帶來了一場地震。
o1 能像人類一樣「思考」複雜問題,擁有優秀的通用推理能力。在未經專門訓練的情況下,o1 能夠直接拿下數學奧賽金牌,甚至能在博士級別的科學問答環節上超越人類專家。
在性能躍升之外,更重要的是,它揭示了大模型進化範式的轉變:通過更多的強化學習(訓練時計算)和更多的推理(Test-Time 計算),模型可以獲得更強大的性能。
這又一次讓我們想起 Richard Sutton 在《The Bitter Lesson》中所說的,利用計算能力的一般方法最終是最有效的方法。這類方法會隨著算力的增加而繼續擴展,搜索和學習似乎正是兩種以此方式隨意擴展的方法。連山姆・奧特曼也坦言,在未來的一段時間里,新範式進化的曲線會非常陡峭。
從「訓練 Scaling」到「推理 Scaling」的範式轉變,也引發了關於計算資源分配和硬件選擇的重新思考。

領域內的研究者和從業者認識到,一方面,更多的計算資源應該投入到推理階段,另一方面,優化硬件配置以提升大模型推理的效率將是下一階段的攻關重點。而大模型要進行推理 Scaling,實際上比訓練 Scaling 對芯片並行處理能力的要求更高。
GPU 最初設計用於圖形渲染,由於其並行處理能力,過去數年一直是以海量數據集訓練大模型的熱門選擇。雖然 GPU 非常適合實現神經網絡的訓練工作,但在全新的範式下,由於其在延遲、功耗等方面表現不佳, 並不是進行大規模推理的最好選擇。
在 GPU 之外,什麼是大模型推理的更好選擇?現在的 AI 芯片有各種流派:ASIC、FPGA、DSP、Neuromorphic Chip,以及大量 DSA (Domain-specific architectures)芯片。其中,以 SambaNova RDU(Reconfigurable Dataflow Unit)為代表的動態可重構數據流(Dataflow)架構的芯片,能夠通過並行處理和高效數據移動來優化性能和效率,近年越來越被認為是一個重要的發展方向。
數倍於 GPU 推理性能
來自 SambaNova 最新一代 RDU SN40L
近日的芯片盛會 Hot Chips 上,圍繞大模型的議題比以往任何一屆都更加活躍。SambaNova 的最新一代 RDU 產品 SN40L 也在這場大會上引發持續討論。大家也充分瞭解到,Sambanova 如何實現大模型的快速推理以及提供 GPU 之外的更優方案。
我們知道,大模型在推理時會逐步生成輸出序列的 Token,每生成每一個 token 都會需要把模型的參數從 HBM(High Bandwidth Memory)搬運到片上進行計算。對於利用 HBM 來推理的芯片來說,HBM 的利用率是推理速度的關鍵,越快從內存中訪問數據,就越能縮短處理時間。
SambaNova 的 RDU 既有 GPU 10 倍以上的片上分佈 SRAM,也有適用於需要快速數據傳輸的大規模計算任務的 HBM。其架構可以自動做到極致的算子融合,達到 90% 以上的 HBM 利用率,使得 RDU 對 GPU 有了 2-4 倍的性能優勢。
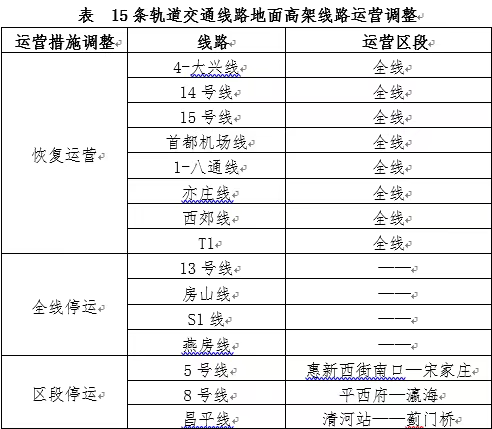
當前的 AI 推理平台中,SambaNova 是唯一能在 Llama 3.1 405B 上提供每秒超過 100 個 Token 推理速度的平台。
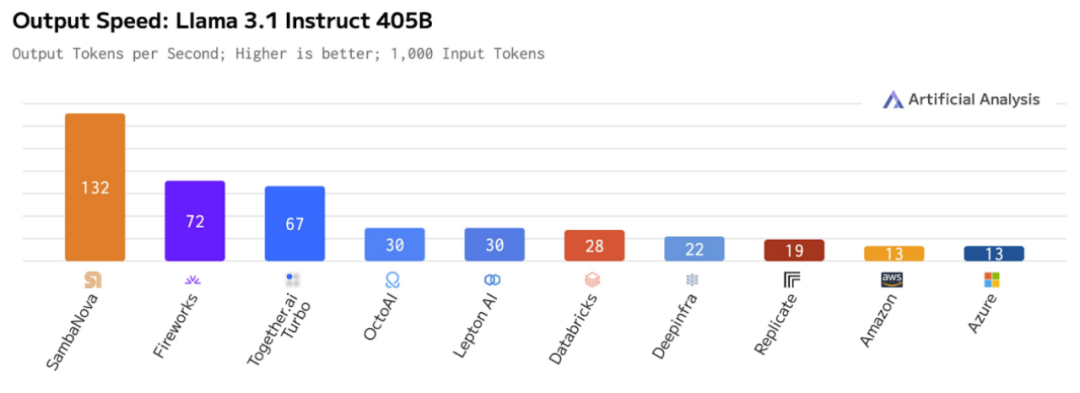
如下圖所示,每個框都是一個算子。一般來說,多個算子會同時運行,並將數據保存在芯片上以重覆使用。但在 RDU 中,整個解碼器是一個 Kernel 調用。
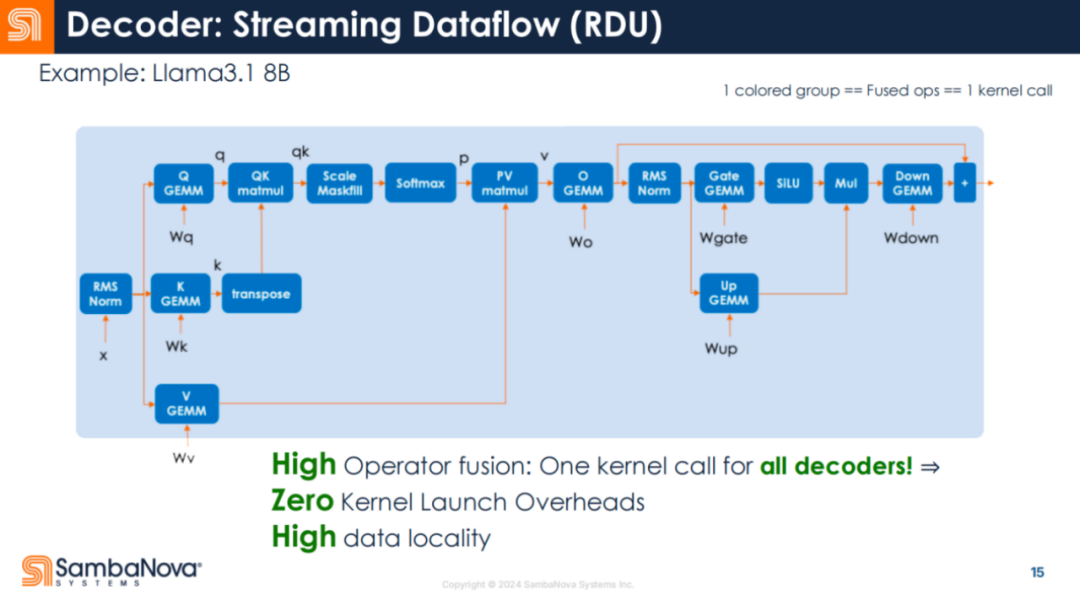
這意味著調用開銷會顯著減少,芯片對數據進行有效工作的時間則增加了。
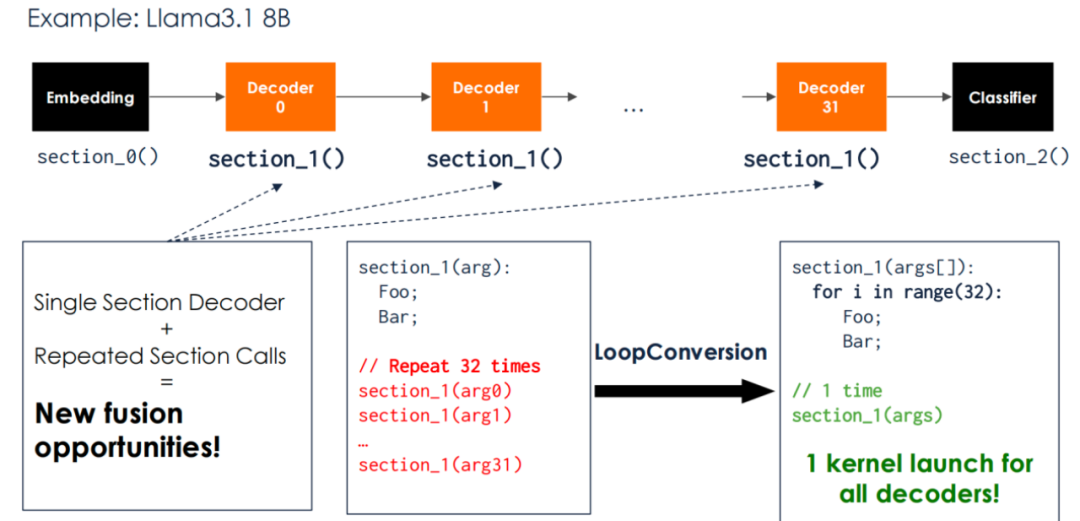
另外一方面,極致的算子融合使 RDU 能夠達到類似 GPU 的批處理能力。GPU 有很好的批處理能力(比如從 BS1 到 BS16),可將吞吐量提高 12 到 15 倍。比如在上圖中,當 decoder0 在進行批處理運算時,可以同時從 HBM 讀取 decoder1 的參數。

SambaNova 的研究者觀察到,SN40L 在 Llama 3.1 70B 上可以實現較好的吞吐量 Scaling。
為什麼業內普遍看好數據流架構?
SN40L 讓我們重新認識了 SambaNova RDU 相對於主流 GPU 的速度優勢,而數據流架構的價值也在被越來越多的從業者重新發現。
與 GPU 本質上不同的是,數據流架構通過數據流動來驅動計算過程,而非常規指令流動。在該架構中,程序被表示為一個 Dataflow Graph,其中節點代表計算操作,邊代表數據依賴關係。每個節點在其所有輸入數據準備好後立即執行,並將結果傳遞給下遊節點。這種架構天然支持並行處理,多個獨立的計算操作可以同時執行,從而顯著提高了計算性能。
從下圖可以看到,SambaNova RDU 的片上空間數據流可以做自動的算子融合 (kernel fusion),與 GPU 的傳統 kernel-by-kernel 運行相比,明顯消除了大量的內存流量和開銷。
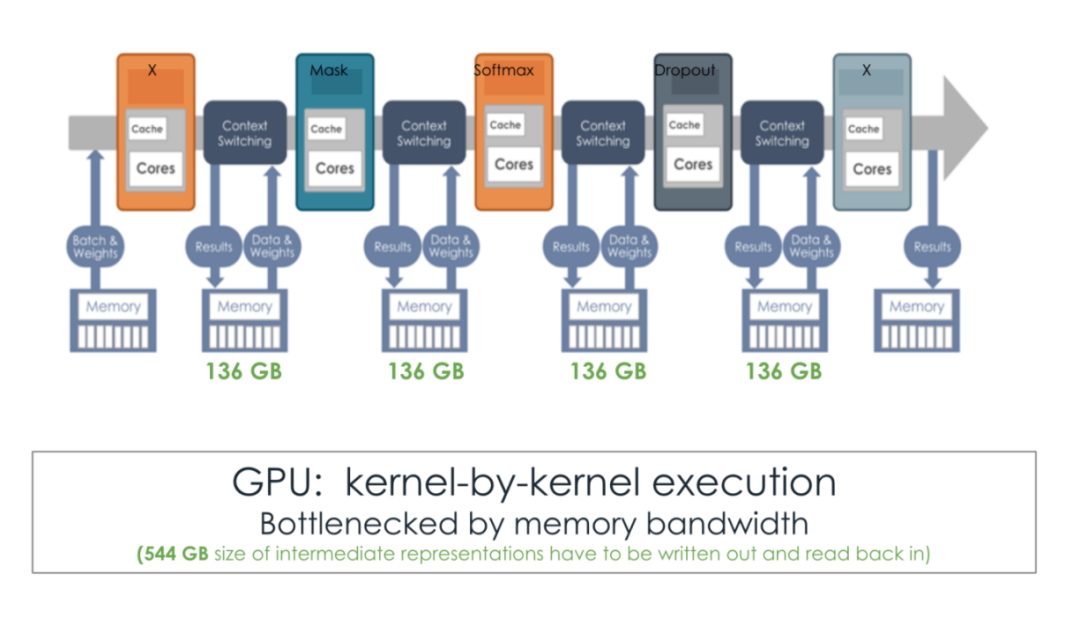

近年來,GPU 廠商明顯意識到非 Dataflow 架構的短板,並為 GPU 部分引入一些 Dataflow 的功能。例如,從 H100 開始,GPU 開始加入分佈式共享內存(Distributed Shared Memory) ,也加入了新的張量內存加速器 (Tensor Memory Accelerator) 單元,使其某種程度上模仿了片上空間流水線運行的「範式」。
但這種程度的改動遠遠不夠,GPU 追趕的速度恐怕已經跟不上 AI 領域推理需求的暴漲。畢竟 GPU 最初不是專門為 AI 而設計的,廠商們很難在不影響主營業務的情況下對基本架構做完全的重新設計,即使增加了上述的「修補」工作,也無法完全採用高效的數據流架構,這從根本上限制了 GPU 推理的提速。
當前的幾家主流 AI 芯片 Startup,都選擇了數據流架構。其中來自 SambaNova 的 RDU 展現出了獨特優勢,也被視為 GPU 的最有力競爭者 。與英偉達相比,Sambanova 最新 Llama 3.1 模型上生成 token 的性能快了 10 倍以上,並且通過 cloud.sambanova.ai 公開供開發人員使用。

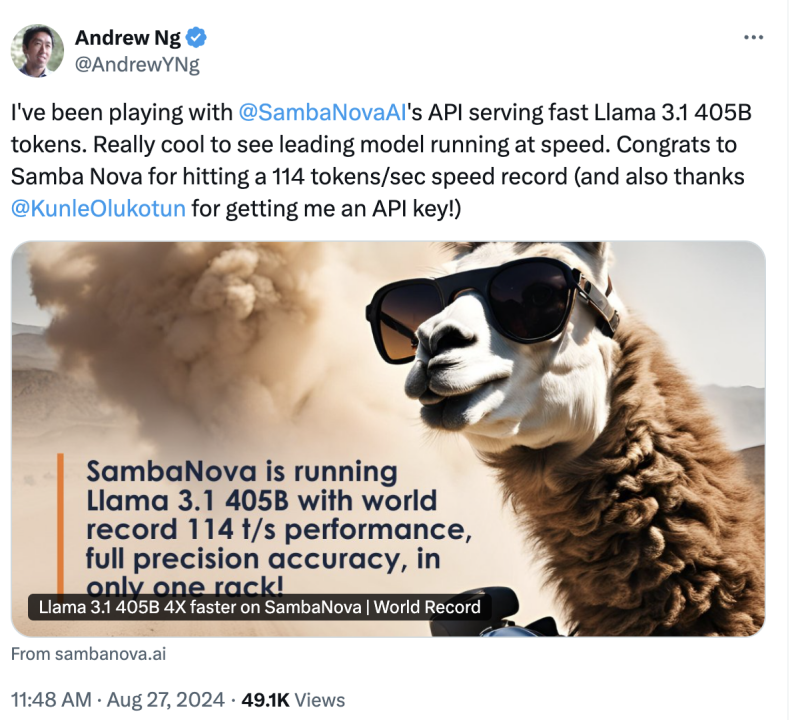
RDU 能夠實現更快的推理速率,更利於大模型的部署。連人工智能專家吳恩達也驚歎 SambaNova 的推理速率:
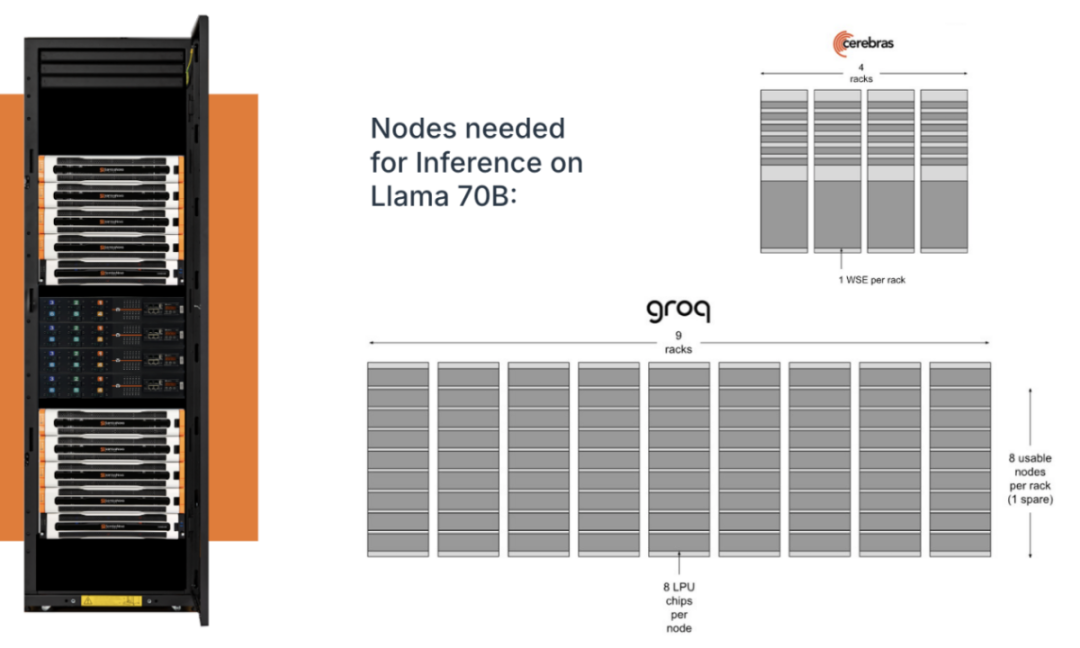
從最基礎的成本上說,由於 Sambanova 的數據流架構 RDU 不僅擁有大的片上 SRAM,同時擁有 HBM 層面的優勢,相比於其他的幾個單純依靠片上 SRAM 的數據流企業,用戶需要支持大型語言模型的基礎設施更少。例如,想在 Llama 70B 上推理,對於有些 AI 芯片來說需要五百多個芯片,或者相當於三百多個芯片的 4 個 wafer ,而 SambaNova 只需要 擁有 16 個芯片的 1 個機架。(https://sambanova.ai/blog/sn40l-chip-best-inference-solution)
更進一步說,RDU 所帶來推理速度提升的意義不只是體現在效率上,更能體現在質量上,也體現對 AGI 探索的加速上。
基於 OpenAI o1 帶來的推理 Scaling Law 的啟發,人們意識到,在推理端,更多的算力同樣會帶來更強的智能。因為在同一時間單位內,推理速度越快,就能實現越複雜的推理,就能解鎖越多複雜任務,大模型應用的天花板就越高。
這意味著,如果我們想更快實現 AGI,我們本質上最需要建設足夠的基礎設施並持續降低計算成本。與此同時,計算資源還要更多地向推理側增加。但在目前的條件下,算力往往是大模型廠商們拓展技術上限的頭道難關,即使對於實力雄厚的玩家們也一樣。
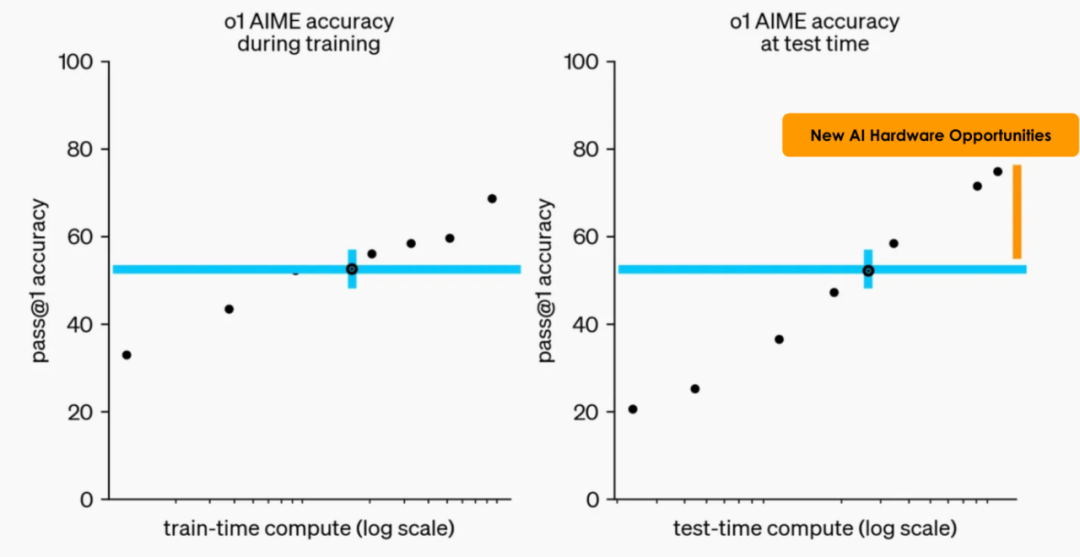
OpenAI 在發佈 o1 時似乎就遇到了這個問題。機器學習研究員 Nathan Lambert 在博客《逆向工程 OpenAI 的 o1》中寫到,在已發佈的基準測試分數和曲線圖中,o1 preview 並非是能力最強的,但 OpenAI 並未立即發佈最強版本的 o1 (詳情見下圖),原因是「最強配置」過於昂貴,他們沒有對應的基礎設施支持大規模的部署。
但推理算力需求並非天塹不可跨越。在 o1 發佈後不久,SambaNova 便在 Hugging Face 上發佈了 Llama 3.1 Instruct-O1 演示 。這個項目由 SambaNova 的 SN40L RDU 提供算力支持,用戶可與 LLama 3.1 405B-instruct 模型進行實時對話,體驗風馳電掣般類 o1 的推理過程。
項目地址:https://huggingface.co/spaces/sambanovasystems/Llama3.1-Instruct-O1
這意味著,在強大算力的支持下,開源大模型推理能力會不斷提升,複現完整 o1 甚至觸達更高級的智能是指日可待的。
一個新的時代正在開啟,當大模型 Scaling Law 的重心從預訓練向後訓練和推理側轉移,廠商們在算力層面的分配與設計也會更深刻影響大模型領域的競爭格局。而對於 SambaNova 或其他以提供算力和計算基礎設施見長的公司來說,接下來會迎來前所未有的機遇。
英偉達的挑戰者
在 AI 芯片賽道的諸多初創公司中,SambaNova 是目前估值最高的一家獨角獸。
SambaNova 成立於 2017 年,擁有三位資深的聯合創始人:Rodrigo Liang、Kunle Olukotun、Christopher Ré。CEO Rodrigo Liang 畢業於史丹福大學,在創立 SambaNova 之前,Rodrigo 領導了甲骨文和 Sun Microsystems 的工程團隊,負責 SPARC 處理器和 ASIC 的開發。Kunle Olukotun 和 Christopher Ré 都來自史丹福大學。
 從左到右分別為 Kunle Olukotun、Rodrigo Liang、Christopher Ré。
從左到右分別為 Kunle Olukotun、Rodrigo Liang、Christopher Ré。此外,被譽為「芯片風險投資教父」的陳立武,自創立之初便作為創始投資人和董事會主席加入 SambaNova,並於 2024 年 5 月出任執行主席,以加速和擴大公司的發展。自 1987 年創立華登國際(Walden International)以來,陳立武投資了許多公司(包括 SambaNova),在推動半導體創新和發展方面發揮了重要作用。

在深度學習引發的第三次人工智能浪潮中,算力對人工智能發展的決定作用已成共識。一系列極具影響力的 AI 研究,如 AlexNet、ResNet 和 Transformer 都是在 GPU 上實現和評估的,這也讓英偉達十年來始終處於 AI 硬件市場的主導地位。
不過,時代可能真要變了。正如 Transformer 會迎來新的挑戰者,比如 Mamba;英偉達和 GPU 也會迎來下一階段的強勁競爭者,比如 SambaNova 的 RDU。
o1 發佈之後,AI 推理市場正處於爆炸式增長的新起點。從 SambaNova 的 RDU 開始,人工智能領域可能正在翻開全新的一頁。