Jurgen、曼寧等大佬新作:MoE重塑6年前的Universal Transformer,高效升級
機器之心報導
編輯:杜偉、蛋醬
7 年前,Google在論文《Attention is All You Need》中提出了 Transformer。就在 Transformer 提出的第二年,Google又發佈了 Universal Transformer(UT)。它的核心特徵是通過跨層共享參數來實現深度循環,從而重新引入了 RNN 具有的循環表達能力。層共享使得 UT 在邏輯推理任務等組合問題上的表現優於 Transformer,同時還在小規模語言建模和翻譯任務上得到改進。
UT 已被證明具有更好的組合泛化特性,能夠在無監督的情況下解構結構化問題並泛化到更長的序列。因此與 Transformer 相比,UT 是一種具有卓越泛化特性的通用性更強的架構。
但 UT 的計算效率遠低於標準 Transformer,不適合當前語言建模等以參數為王的任務。那麼,我們能不能開發出計算效率更高的 UT 模型,並這類任務上實現比標準 Transformer 更具競爭力的性能呢?
近日,包括 LSTM 之父 Jürgen Schmidhuber、史丹福大學教授 Christopher Manning 等在內的研究者從全新視角出發,提出瞭解決 UT 基礎計算參數比問題的最新方案。具體來講,他們提出 Mixture-of-Experts Universal Transformers(簡稱 MoEUT),它是一種混合專家(MoE)架構,允許 UT 以計算和內存高效的方式擴展。

-
論文標題:MoEUT: Mixture-of-Experts Universal Transformers
-
論文地址:https://arxiv.org/pdf/2405.16039
-
代碼地址:https://github.com/robertcsordas/moeut
在文中,研究者利用了 MoE 在前饋和自注意力層方面的各種最新進展,並將這些進展與以下兩項創新工作相結合:1)layer grouping,循環堆疊 MoE 層組;2)peri-layernorm 方案(位於 pre-layernorm 和 post-layernorm 之間),並且僅在緊接 sigmoid 或 softmax 激活之前應用層範數。這兩者都是專為共享層 MoE 架構設計,並且有強有力的實證證據支持。
從其作用來講,MoEUT 允許構建參數和資源高效的 UT 語言模型,不僅在我們可以負擔得起的所有規模(最高 10 億參數)上對算力和內存的需求更低,性能也超越了標準 Transformer。
研究者在 C4、SlimPajama 和 peS2o 語言建模數據集、以及 The Stack 代碼數據集上測試 MoEUT 的能力,結果表明,循環對於模型實現具有競爭力的性能至關重要。同樣地,研究者在 BLiMP 和兒童圖書測試、Lambada、HellaSwag、PIQA 和 ARC-E 等下遊任務上展現了良好的零樣本性能。
MoEUT 架構概覽
如前文所述,MoEUT 是一種具有層共享參數的 Transformer 架構,其中使用 MoE 來解決參數計算比問題。雖然最近出現了很多關於 Transformer 語言模型的 MoE 方法研究,但要讓它們在參數相同的情況下與密集方法競爭,仍然是一項艱巨的任務。
因此,研究者利用了 MoE 前饋網絡塊(FFN)、MoE 自注意力層,並引入了兩種考慮到共享層模型特定屬性的新方法 ——layer grouping 和信號傳播。這些技術的結合對於實現有效的共享層 MoE Transformer 發揮了巨大作用。
MoE 前饋塊
為了通過 MoE 來參數化共享層 Transformer 的前饋塊,研究者使用了 σ-MoE 並做了一些修改。σ-MoE 將前饋塊劃分為 N_E 個切片,稱為專家(expert)。每個專家都有兩組權重,分別是

和
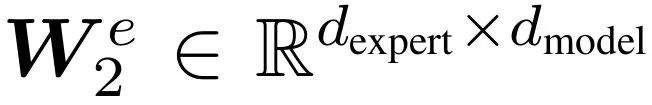
,其中 e ∈{1,…,N_E} 是專家索引。
在每個 token 位置 t,給定層輸入 x_t ∈ R^d_model,MoE 前饋層會為每個專家計算一個分數,從而得到一個向量 s ∈ R^N_E,其計算如下:

MoE 層僅選擇與 s_t ∈ R^N_E 中 top-K 元素相對應的 K 個專家(從 N_E 中),來產生層輸出 y_t ∈ R^d_model,如下所示:
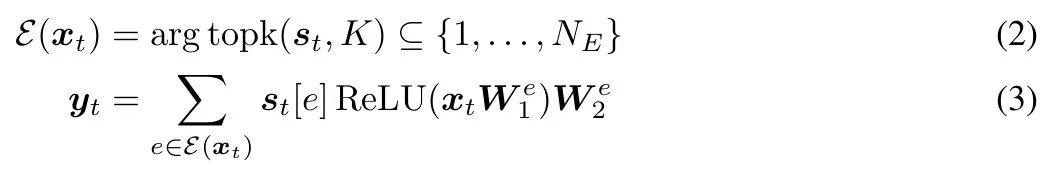
初步實驗表明,σ-MoE 的原始正則化往往不穩定,有時會導致訓練期間損失激增。為了避免這種情況,研究者僅在序列內應用正則化(而不是批次中的所有 token)。對於輸入序列 x_t,t ∈ {1,…,T},計算平衡損失 L 如下所示:

MoE 自注意力層
為了將 MoE 引入自注意力層,研究者應用了 SwitchHead,它是一種將 σ-MoE 擴展到注意力層的 MoE 方法。與標準多頭注意力層一樣,SwitchHead 層中的每個頭包含四個轉換:查詢、鍵、值和輸出投影。但是,SwitchHead 使用 MoE 來參數化值和輸出投影。
也即,每個頭都有一個與之關聯的查詢和鍵投影以及 N_A 值和輸出投影,它們針對每個輸入進行動態選擇。
鍵和查詢「照常」計算:給定位置 t 處的一個輸入,x_t ∈ R^d_model,並且 k^h_t = x_tW^h_K、q^h_t = x_tW^h_Q,h ∈{1,…,H} 是頭索引。專家對這些值的選擇計算如下:

值和輸出的選擇是獨立的。輸出的選擇使用不同的權重矩陣 W^h_SO ∈ R^d_model× N_A 來類似地計算,即

和

。輸出 y ∈ R^d_model 計算如下:

層分組:MoE 高效層共享和操作內的子操作
研究者觀察到,基於 MoE 的原始 UT 只有一個共享層,在更大規模上往往難以獲得良好的性能。假設原因有二:首先,隨著網絡規模的擴大,層中專家的數量會迅速增加,但我們無法以相同的速度增加活躍專家 K 數量而不大幅增加所需計算量。這就迫使我們降低活躍專家的比例,而這通常是不利的。其次,注意力頭的總數保持在相對較低的水平,這對於一個大型模型來說可能是不夠的。增加註意力頭的數量也同樣代價高昂。
因此,在增加註意力頭總數的同時,可以調用一組層,減少每個 σ-MoE 中的專家數量。最終的網絡是通過重覆堆疊這些共享相同參數的小組而得到的(從某種意義上說,將組重新定義為 UT 中的共享層)。
下圖 1 提供了一個示例,標記為「層 A」(或層 B)的所有層在整個網絡中共享相同的參數。組 G 的大小是非共享層的數量。在研究者的實驗中,組大小在 2 到 4 之間,典型的循環步驟數為 8 或 9。

在 UT 中改進信號傳播的新型層歸一化方案
研究者提出另一種方法來避免上述問題:在「主數據路徑」中不使用分層歸一化。這意味著,對於本文的 UT,在注意力值投影之前不使用分層矩陣,在 σ-MoE 層之前也不使用分層矩陣。相反,只有在緊跟著 sigmoid 或 softmax 激活函數的線性層(在這些非線性層之前產生關鍵的重歸一化激活)之前,即注意力中的查詢和關鍵投影、注意力層和前饋層上的專家選擇以及最終分類層之前,才會使用 layernorm。如圖 3 所示。
由於前饋層內的主數據路徑上只使用了 ReLU 激活函數,因此輸出更新將與輸入成正比,從而有效地解決了殘差增長問題,同時也提供了高效的梯度流路徑。這種方案稱為 「peri-layernorm」方案,它介於「pre-layernorm」和「post-layernorm」方案之間,將 layernorm 定位在殘差連接的「周圍」(但不在其上)。具體如下圖 3 所示。

實驗結果
在論文中,研究者展示了使用流行的 C4 數據集進行語言建模時 MoEUT 性能和效率的主要實驗結果。為了證明 MoEUT 的通用性,研究者還展示了在 SlimPajama 和 peS2o 語言建模數據集上的主要結果,以及在 「The Stack」上的代碼生成。
與標準 Transformer 對比 Scaling
MoEUT 的 Scaling 結果如圖 4 所示。y 軸顯示的是 C4 held-out 子集上的複雜度。在參數數量相同的情況下,MoEUT 模型略微優於密集模型(圖 4a),而且隨著規模的擴大,差距呈擴大趨勢。研究者還與非共享 σ-MoE 模型進行了比較,該模型的表現明顯不如 MoEUT,這表明共享層具有明顯的優勢。此外如圖 4b 顯示,就訓練期間所有前向傳遞所花費的總 MAC 運算次數而言,MoEUT 遠遠優於基線密集模型。

代碼生成性能
為了證實 MoEUT 在不同任務領域的有效性,研究者在「The Stack」數據集的一個子集上對其進行了訓練,該數據集是一個代碼生成任務。由於無法進行完整的 epoch 訓練,因此這裏只使用了幾種語言並混合使用了這些語言:Python、HTML、C++、Rust、JavaScript、Haskell、Scala 和彙編。研究者在數據集的一個 held-out 子集上評估了 MoEUT。結果如圖 5 所示,與自然語言領域的結果一致:MoEUT 的表現優於基線。

圖 6 展示了 layer grouping 對 244M 參數 MoEUT 模型的影響。研究者發現 G = 2 是最佳值,而且層維度的循環確實是有益的。
下遊任務上的零樣本表現
研究者評估了 MoEUT 在六個不同下遊任務中的零樣本性能:LAMBADA、BLiMP、Children’s Book Test (CBT) 、HellaSwag、PIQA 和 ARC-E。結果見表 1,MoEUT 的表現往往優於基線,但在所有情況下差異都很小。

研究者還將 MoEUT 與另一個基準模型 Sparse Universal Transformer(SUT)進行了比較,SUT 是最近提出的一個 UT 模型,也使用了 MoE 層,且以前未在標準語言建模任務中進行過評估。雖然 MoEUT 和 SUT 都在前饋層和注意力層使用了 MoE,但這兩種方法在不同層面上存在一些技術差異:SUT 使用競爭性專家選擇(softmax)、多重負載平衡損失和更大的專家規模,且採用 post-layernorm 模式,不使用 layer grouping。與 MoEUT 的方法不同,SUT 在層維度上使用了自適應計算時間(ACT)。
結果如圖 7 所示。與 MoEUT 和參數匹配的密集基線相比, SUT 在性能上有明顯的劣勢。研究者認為這種性能低下的主要原因是作者將 ACT 機制作為其模型的主要組成部分之一。移除 ACT 後,性能顯著提高。然而,即使在這種設置下,它的性能仍然低於 MoEUT 和標準 Transformer 基線。

研究者還對「peri – 層歸一化」進行了評估。圖 8 顯示了結果。本文的層歸一化方案始終表現最佳。小模型的差距更大,而大模型的差距則越來越小(對於 719M 參數模型,peri-norm 和 post-norm 之間的差距微乎其微)。同時,隨著訓練步數的增加,peri-norm 和 post-norm 之間的差距也在增大,因此如果模型的訓練時間更長,就有可能獲得更高的收益。
調整專家選擇機制
為了更好地理解 MoEUT 的專家選擇,研究者分析了在 C4 上訓練的 244M 參數 MoEUT 模型的 MLP 塊中的專家選擇。本節中的所有實驗都是通過計算 C4 驗證集上 G = 2(即模型組中有兩層)模型的統計數據進行的。這裏只展示了模型組第一層的行為,因為研究者發現第二層的結果在本質上是相似的。
結果表明,MoEUT 能夠根據不同情況動態調整其專家選擇機制。有時,專家會被分配給流行的 token,而在其他情況下,專家會在各層之間共享或專門化,這取決於哪種方式更適合任務。
專家的跨層使用。如圖 9 所示,右下角的黃點表示一些專家主要被分配到最後一層。然而,對於其他專家來說,專家被激活的層範圍很廣。專家似乎是在連續的層序列中被激活的,這可以從縱向排列的寬闊結構中看出。因此可以得出這樣的結論:如果有必要,MoEUT 能夠專注於特定層,並可在各層之間共享權重。

每個 token 專家選擇的多樣性。研究者分析了 MLP 各層針對給定輸入 token 在不同層和上下文中的專家選擇多樣性。為此,他們測量了不同層在不同位置 / 上下文下為單個 token 激活的專家總數。結果如圖 10 所示。
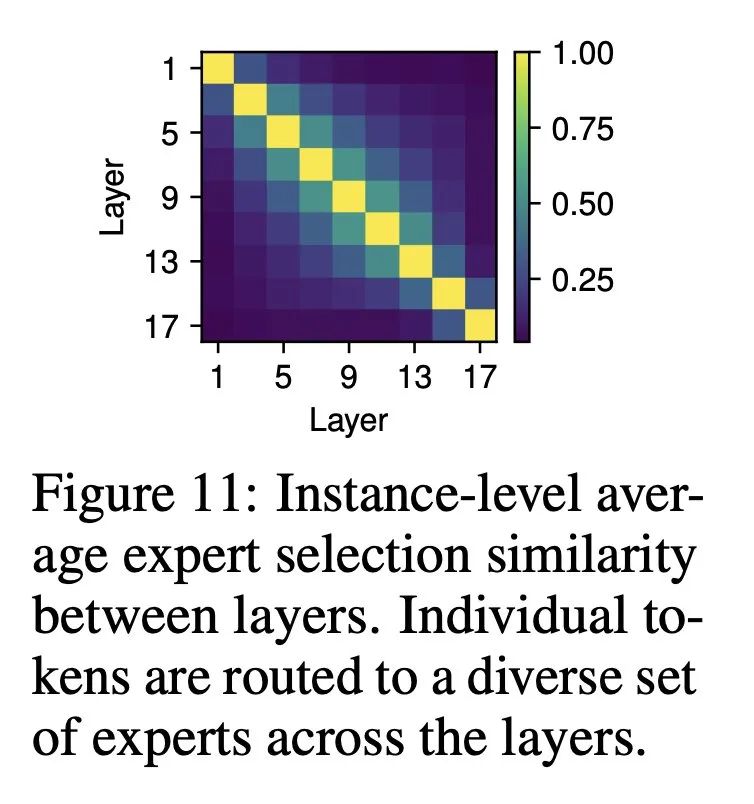
各欄/位置的專家選擇動態。結果如圖 11 ,在後續層中,所選專家之間存在不可忽略的重疊;但是,這種重疊還遠遠沒有達到完全重疊的程度。這表明,專家通常在單列中動態變化,在不同層中執行不同的功能。
更多研究細節,可參考原論文。


















