蘋果一篇論文得罪大模型圈?Transformer不會推理,只是高級模式匹配器!所有LLM都判死刑

新智元報導
編輯:peter東 Aeneas
【新智元導讀】蘋果研究者發現:無論是OpenAI GPT-4o和o1,還是Llama、Phi、Gemma和Mistral等開源模型,都未被發現任何形式推理的證據,而更像是複雜的模式匹配器。無獨有偶,一項多位數乘法的研究也被拋出來,越來越多的證據證實:LLM不會推理!
LLM真的會推理嗎?

最近,蘋果研究員發文質疑道:LLM根本沒有不會推理,所謂的推理能力只是複雜的模式匹配罷了。
 論文地址:https://arxiv.org/abs/2410.05229
論文地址:https://arxiv.org/abs/2410.05229這項研究也在AI社區引起了廣泛討論。
GoogleDeepMind科學家Denny Zhou表示,自己ICML 2023的一片論文中,也發現了類似現象。

Meta AI研究者田淵棟表示,梯度下降可能無法學習到這樣的權重。

巧的是,AI2等機構在23年的一篇研究也被翻出,證實模型根本沒有學會數學推理,只是在「照背」答案而已。
網民們蒐羅了越來越多的學術證據,一致證明:LLM可能根本不會推理!

圖靈三巨頭之一的LeCun,也在最近的萬字演講表示,Meta現在已經完全放棄純語言模型,因為僅靠文本訓練,它永遠不可能達到接近人類水平的智能!

目前Transformer架構的大語言模型,難道真的是一條彎路?
換個馬甲,大模型的數學能力就滑坡了!
這次,蘋果的研究者們仔細研究了GPT-4o和o1系列閉源模型,以及Llama、Phi、Gemma、Mistral等開源模型的數學能力。
此前,業界用來評價大模型數學能力的數據集是2021年發佈的GSM8K,該數據集包含8000可小學水平的數學應用題,例如下面的例子:
當索菲照顧她侄子時,她會為他拿出各種各樣的玩具。積木袋里有31塊積木。毛絨動物桶里有8個毛絨動物。堆疊環塔上有9個五彩繽紛的環。索菲最近買了一管彈性球,這使她為侄子準備的玩具總數達到了62個。管子裡有多少個彈性球?
此時距OpenAI發佈GSM8K已經三年了,模型性能也從GPT-3的35%,提升到了30億參數模型的85%以上。

不過,這真的能證明LLM的推理能力確實提高了嗎?
要知道,由於是21年發佈的數據集,如今的主流大模型可能抓取的訓練數據無意間涵蓋了GSM8K的題目。
雖然大部分模型沒有公開訓練數據的信息,但存在數據汙染的可能,這就會導致大模型能夠靠背題答對GSM8K中題目。
因此,用這個數據集去評判LLM的數學能力,並不準確。
於是,為了客觀評價LLM的數學能力極限,蘋果的研究者們開發了一個名為GSM-Symbolic的數據集。
GSM-Symbolic將GSM8K的題目進行了修改,例如改變了索菲這個名字,侄子這個家人的稱謂,以及各種玩具的多少(數字)。
這樣一來,就可以產生出很多個看起來全新,但實際上卻是具有相同內核的題目。

另外,除了GSM-Symbolic,這項研究還提出了GSM-NoOp數據集,GSM-NoOp 向題目中添加看似相關但實際上無關的數據,來判斷大模型在執行邏輯推理任務時是否會受到無關數據的影響。
不管開源閉源,都會因題目換皮表現更差
實驗結果很有趣:就跟人類一樣,數學題幹一換,很多LLM就不會了!

蘋果的研究者們對比了GSM8k和GSM-Symbolic在多種模型上的性能差異,結果發現——
無論是主流的開源模型還是閉源的GPT系列模型,甚至專門為數理推斷專門優化的o1模型,當面對GSM-Symbolic的換皮題目時,準確率都會下降。
大多數模型在GSM-Symbolic上的平均性能,都低於在GSM8K上的平均性能。

 GSM8k和GSM-Symbolic和模型性能對比
GSM8k和GSM-Symbolic和模型性能對比即使只更改了題目中的名稱,大模型的表現也會有存在差異,當只改變了題目中的專有名詞時,性能下降在1%-2%之間,當實驗者更改數字或結合兩類更改時,差異則更為顯著。
 對比只修改題目中的專有名詞,題目中數字和都修改時的準確度
對比只修改題目中的專有名詞,題目中數字和都修改時的準確度從圖2中可看出,幾乎所有模型都明顯出現了分佈均值從右向左的逐漸移動(準確度變低),以及方差增加。
僅僅是更改一下專有名詞,就會存在如此大的差異,這種現象實在是令人擔憂:看來,LLM的確沒有真正理解數學概念。
即使理解了數學題目的小學生,都不會因為題目換湯不換藥,就不會做了。

隨後,蘋果的研究者繼續給這些LLM上難度。
他們引入了GSM-Symbolic的三個新變體:刪除一個分句(GSM-M1),增加一個分句(GSM-P1)或增加兩個分句(GSM-P2)。
果然,當模型面對的題目變難時,例如題目從「打電話每分鐘10分錢,打60分鐘多少錢?」變為「打電話前10分鐘每分鐘10分錢,之後每分鐘8分錢,如此打60分鐘電話費多錢?」,大模型回答的準確性降低,方差變大,這就意味著,LLM的性能極不穩定,可靠性越來越差。

最後,當模型面對增加了和題目無關的論述的題目(GSM-NoOP),性能的下降更是慘不忍睹。
所有模型的性能下降都更加明顯,其中Phi-3-mini 模型下降了超過 65%,甚至像o1-preview這樣的預期表現更好的模型也顯示出顯著的下降(17.5%)。
這是由於模型會將無關的論述當成需要操作的步驟,從而畫蛇添足地回答錯誤。
也就是說,當今性能最強大的模型,也依然無法真正理解數學問題。
 GSM-NoOP數據集相比GSM8k數據集的性能下降
GSM-NoOP數據集相比GSM8k數據集的性能下降 o1系列模型,依然無法避免這些問題
o1系列模型,依然無法避免這些問題從這項研究的結果來看,大模型在執行真正的數學推理方面的重大局限性。
大模型在不同版本的同一問題上的表現高度差異,隨著難度輕微增加而表現大幅下降,以及對無關信息的敏感度表明,大模型進行的推理及運算是脆弱的。
最終,蘋果研究者給出這樣的結論——它們可能更像是複雜的模式匹配,而不是真正的邏輯推理。
也就是說,即使我們繼續堆數據、參數和計算量,或者用更好的訓練數據,也只能得到「更好的模式匹配器」,而非「更好的推理器」。
大模型實際不是解數學題,還是在進行模式匹配
無獨有偶,23年的一項研究《信仰與命運:Transformer作為模糊模式匹配器》也證實——
大模型並沒有真正的理解數學概念,而只是根據模糊模式匹配來從訓練數據的題庫中尋找答案。
 論文地址:https://arxiv.org/abs/2305.18654
論文地址:https://arxiv.org/abs/2305.18654研究者們很疑惑,為什麼Claude或GPT-4這樣的模型輸出時,聽起來非常像一個人在推理,而且問題也都是需要推理才能解決的。
它們彷彿已經在超人類智能的邊緣,但在處理一些簡單的事情上卻有很蠢。
比如,人類在學習基本計算規則後,可以解決三位數乘三位數的乘法算術。但在23年底,ChatGPT-3.5和GPT-4在此任務上的準確率分別只有55%和59%。
到底發生了什麼?
在《信仰與命運》這篇論文中,Allen AI、華盛頓大學等的學者對LLM的這種表現提出了一種解釋——「線性化子圖匹配」。
線性子圖匹配
他們猜測,大模型解決問題的方式是這樣的。
1. 任何任務的解決問題都可以表示為一個有向圖,該圖將任務描述為一系列步驟,這些步驟會被分別解決,然後將結果組合在一起。
2. 如果整個任務的解決方案過程可以用一個圖來描述,那麼其中的子任務就是該圖中的子圖。圖的結構描述了哪些步驟依賴於其他步驟,而這種依賴順序限制了子圖如何被展平成線性序列。
3. GPT類的模型,通常就是通過近似匹配來「解決」上述子圖的。給定一個可以用子圖描述的問題,大模型就會通過大致將其與訓練數據中相似的子圖相匹配,來進行預測。
為了證明這項猜測,研究者測試了三個任務——
乘法、愛恩斯坦邏輯謎題和動態規劃問題。
拿乘法舉例。
如果LLM真的能通過足夠的數據學會東西,或者能通過系統化的推理解決複雜的多步驟問題,那它應該能通過足夠的例子或對算法的充分解釋來學習乘法。
而乘法問題可以被分解為更小的問題,因此模型應該能通過逐步推理來做出來。
LLM可以完成嗎?
為了檢驗多位數乘法任務,研究者定義了一組大量的乘法問題。從計算兩位數和兩位數的乘積到五位數和五位數的乘積。
首先,他們會要求模型解決如下問題:
問題:35 乘以 90 等於多少?答案:3150。
其次,他們向模型提供了思維鏈示例,將其分解為更小的任務,使用學校教授的標準乘法算法。
 提示模型執行任務的程序
提示模型執行任務的程序但如何衡量一項任務比另一項更難呢?如何追蹤模型在哪些地方失敗,如何失敗?
研究者將乘法算法描述為一個包含加法和乘法等基本操作的定向圖。
比如下面是7乘以49所涉及的運算的圖表示:

其中包含7乘以4的子任務。
 子程序是圖中的子圖
子程序是圖中的子圖研究者在評估中發現,即使經過微調,模型也無法從訓練集中看到的小乘法問題,推廣到更大的乘法問題。
在左側圖中,藍色的單元格表示模型是在這樣的乘積上訓練的,得分相當不錯。
原因在於,模型在預測與訓練數據規模相同的問題時就表現良好。
然而在橙色的單元格,如三位數與三位數或更高位數的乘積,得分就要差得多了。
 GPT-3準確率與規模對比
GPT-3準確率與規模對比在操作圖中可以看出,當任務變得更加複雜時,準確度會急劇下降。
 寬度衡量需要同時維護多少個中間結果,而深度衡量需要組合多長的步驟序列才能達到結果
寬度衡量需要同時維護多少個中間結果,而深度衡量需要組合多長的步驟序列才能達到結果由此,研究者總結出一些真正有趣的東西。
錯誤告訴我們,LLM中真正發生的事
首先,研究者觀察到:LLM是否能成功解決問題,取決於模型之前是否見過相關的子問題。
換句話說——
1. LLM無法解決大型問題,因為它們只能解決大型問題中的部分子問題。
2. 如果它們在解決訓練數據中頻率更高或更精確的子問題上成功了,這表明它們只是記住了答案,通過回憶解決。
這就是為什麼7乘以49會失敗,但7乘以4卻取得一些進展,因為LL沒記住了「7乘以4的呢關於28」這個子問題。
更大的意義在於:與其將模型視為以一般和系統的方式處理問題的各個部分,不如將其視為搜索引擎,它會先召回與特定問題部分大致匹配的例子,然後將這些近似回憶拚接起來。
也就是說LLM通過僅完成整體問題的一部分而取得部分成功。
它是以自己反直覺、更膚淺、更實際的方式分解問題,更關注文本的「表面」,而非系統地思考給定的乘法算法。
 高信息增益,甚至能預測意外的部分解決方案
高信息增益,甚至能預測意外的部分解決方案一些問題
作者提出,子圖匹配的想法,更多的是一個起點,而非對現狀的精確完整描繪。
後續的實證研究,又削弱了這一解釋的普遍性。
比如McLeish 等人(2024 年)表明,通過「算盤嵌入」的架構修改,可以顯著提高Transformer在算術上的性能。
LLM能夠解決比訓練數據中更大的多位數加法問題,但未體現乘法性能的同等提升。
如果線性子圖匹配是Transformer的一般性限制,那麼加法為何會如此容易受到特定修復的影響,而非乘法呢?
這又引出了新的問題:什麼樣的文本表示將使模型更容易處理多步問題——比如推理鏈問題?
那些從外部看起來像是在推理的系統,即使我們知道其內部並未在邏輯蘊涵空間中執行搜索,它們的實際限制在哪裡?
這些都留待未來解決。
馬庫斯:我早說過了
對於蘋果的研究,馬庫斯也專門寫了一篇博客進行論述。

他表示,LLM的這種「在受到干擾材料的影響下推理失敗」的缺陷,並非新現象。
在2017年,史丹福大學的Robin Jia和Percy Liang就進行過類似研究,得出了相似的結果。

在問答系統中,即使只是改變一兩個無關緊要的詞或添加一些無關信息,也可能得到完全不同的答案
另一個體現LLMs缺乏足夠抽像、形式化推理能力的證據是,當問題變得更大時,其性能往往會崩潰。
這源於Subbarao Kambhapati團隊近期對GPT o1的分析:
 性能在小問題上尚可,但很快就會下降
性能在小問題上尚可,但很快就會下降在整數算術中,我們也可以看到相同現象。
在越來越大的乘法問題中,這種下降趨勢在舊模型和新模型中都被反復觀察到。
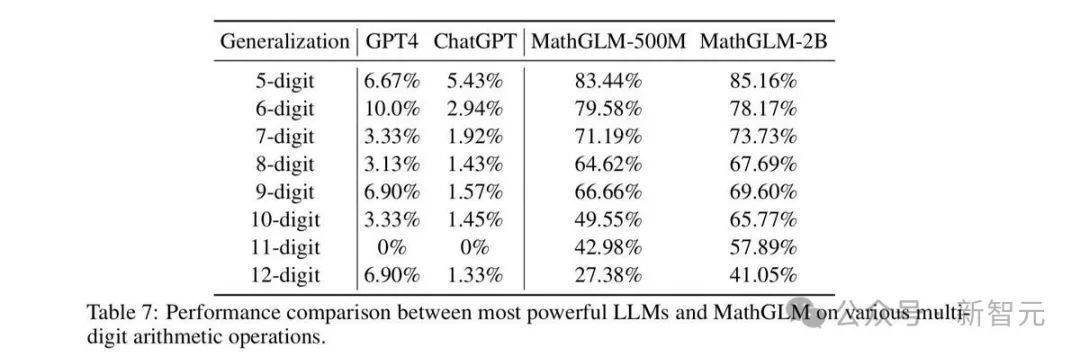
即使 o1 也受到這個問題的影響:

LLM不遵守棋類規則,是其形式推理持續失敗的另一個例子:

馬斯克提出,甚至馬斯克的Robotaxi也會受到類似困擾:它們可能在最常見的情況下安全運行,但在某些情況下可能難以足夠抽像地推理。
馬庫斯指出:LLM愛好者總是為它們的個別錯誤開脫,然而最近的蘋果研究及其他相關研究和現象,都太過廣泛和系統化,讓我們無法視而不見了。
他表示,自1998和2001年以來,標準神經網絡架構無法可靠地外推和進行形式化推理,一直是自己工作的核心主題。
最後,他再次引用了自己在2001年的《代數心智》一書中的觀點——
符號操作,即某些知識通過變量及其上的操作以真正抽像的方式表示,就像我們在代數和傳統計算機編程中看到的一樣,必須成為AI發展的組成部分。
神經符號AI——將這種機制與神經網絡結合起來——很可能是未來前進的必要條件。

總的來看,無論是將乘法拆解為有向圖,還是一旦面對應用題中稱謂和數字變換就答錯,這都反映了大模型在邏輯推理上的本質缺陷。
總之,LLM在背題這件事,算是「人贓俱獲」了。
這兩項研究也警示我們:正如Meta的AI科學家田淵棟所說,只要大模型還是依賴梯度下降,那麼就不要期待它變得不那麼愚蠢。
參考資料:
https://www.reddit.com/r/MachineLearning/comments/1g3cumr/d_will_scale_be_enough_to_get_llms_to_reason/
https://garymarcus.substack.com/p/llms-dont-do-formal-reasoning-and?r=17uk7&triedRedirect=true
https://www.answer.ai/posts/2024-07-25-transformers-as-matchers.html


















