DeepMind聯合MIT團隊開發Fluid,讓自回歸模型實現文生圖的大規模擴展
在視覺領域,擴散模型(diffusion model)已然成為圖像生成的新範式。我們熟知的 Stable Diffusion、DALL-E 和 Imagen 等文生圖工具都以擴散模型為基礎。
而在語言模型領域,自回歸模型(autoregressive model)則佔據主導位置,大名鼎鼎的 ChatGPT 就使用了此類模型來生成回覆。所謂的擴展法則(Scaling Law)在以自回歸模型為基礎的大模型身上展現出了強大的力量,可以有效的提升性能。
不過,如果回到視覺領域(比如文本生成圖像),擴展自回歸模型並未像在大語言模型中那樣顯著有效。許多研究人員正在努力搞清楚原因,並且想辦法彌合自回歸模型在視覺模型與語言模型之間的性能差距。
近日,來自GoogleDeepMind 和美國麻省理工學院的研究人員發表了一篇預印本論文,介紹了他們在「提升自回歸文生圖模型性能」方面的最新進展。
 圖 | 論文標題《FLUID:使用連續 Token 擴展自回歸文本到圖像生成模型》(來源:資料圖)
圖 | 論文標題《FLUID:使用連續 Token 擴展自回歸文本到圖像生成模型》(來源:資料圖)該研究團隊開發的新模型 Fluid,通過採用連續 Token 和隨機順序策略,成功實現了自回歸模型在文生圖任務上的大規模擴展,不僅在多項基準測試中達到了領先水平,還提出了關於自回歸模型的新見解。
自回歸模型在自然語言處理領域取得了巨大成功,但在計算機視覺特別是文生圖任務中的表現一直不如擴散模型。
為了探究背後的原因,研究團隊對自回歸圖像生成模型的兩個關鍵設計因素進行了系統性的研究:Token(離散或連續)和生成順序(光柵順序或隨機順序)。
研究發現,採用連續 Token 的模型在視覺質量和評估指標上都顯著優於使用離散 Token 的模型。這主要是因為離散 Token 化過程會導致大量信息丟失,即使增加模型參數也無法彌補這一缺陷。
例如,在生成著名的蒙娜麗莎畫像時,基於離散 Token 的模型即使擴展到 30 億參數,也無法準確還原畫像細節。相比之下,基於連續 Token 的模型可以生成更高質量、更符合文本描述的圖像。
 圖 | 105 億參數的 Fluid 模型生成的圖片(來源:資料圖)
圖 | 105 億參數的 Fluid 模型生成的圖片(來源:資料圖)在生成順序方面,研究表明隨機順序模型在生成多個對象和複雜場景時表現更佳。這可能是因為隨機順序允許模型在每個預測步驟中調整圖像的全局結構,而光柵順序模型則缺乏這種靈活性。這一發現對提高文本到圖像的對齊度具有重要意義。
基於這些新發現,研究團隊開發了 Fluid 模型。Fluid 採用連續 Token 和隨機順序生成策略,在可擴展性和生成質量上都表現出色。
實驗結果顯示,Fluid 模型的驗證損失、FID(Fréchet Inception Distance,是用於衡量兩個多元正態分佈之間距離的評價指標)評分和 GenEval 得分都隨著模型參數規模的增加而持續改善。
值得注意的是,僅有 3.69 億參數的小型 Fluid 模型就達到了 7.23 的零樣本 FID 得分,還在 GenEval 基準測試中達到了 0.62,與擁有 200 億參數的 Parti 模型(Google開發的自回歸文生圖模型)持平。
受到這一趨勢的啟發,研究團隊將 Fluid 模型進一步擴展到 105 億參數。該模型在 MS-COCO 數據集上實現了 6.16 的零樣本 FID 得分,在 GenEval 基準測試中的綜合得分達到 0.69,超越了 DALL-E 3 和 Stable Diffusion 3 等多個使用擴散模型的文生圖系統。
Fluid 模型的成功不僅體現在量化指標上,在視覺質量方面也有顯著提升。
研究人員展示了 Fluid 模型在各種複雜場景下的生成結果,使用了如「一隻憤怒的鴨子在健身房舉重」「冬天的蒙娜麗莎」「辦公室里三隻穿西裝的泰迪熊為朋友慶祝生日」等提示。

圖 | 不同參數、不同生成順序和 Token 連續或離散的圖像對比,紅色方框圈出的是表現最好的模型:31 億參數、隨機順序和連續 Token(來源:資料圖)
這些生成的圖像不僅細節豐富,而且準確反映了文本描述的內容和情感,展現出模型對文本和圖像之間複雜關係的深入理解。
研究團隊的實驗還揭示了一個現象,即驗證損失與評估指標(如 FID 和 GenEval 得分)之間存在強相關性。這意味著通過簡單地監測驗證損失,就可以在一定程度上預測模型在下遊任務中的表現。
此外,研究還發現與語言模型類似的是,增加訓練步數和計算量可以持續提升 Fluid 模型的性能。但是,該團隊也觀察到對於較小的模型,增加訓練步數的效果不如直接擴大模型規模。這一發現強調了模型規模在提升性能中的關鍵作用。
Fluid 模型不僅標誌著自回歸模型在文生圖任務上的新進展,也為計算機視覺領域的模型擴展提供了新的思路。課題組指出,這項工作可能有助於縮小視覺模型和語言模型在擴展性能上的差距。
然而,研究人員也承認,儘管 Fluid 模型在多個指標上取得了領先,但在某些方面仍有提升空間。
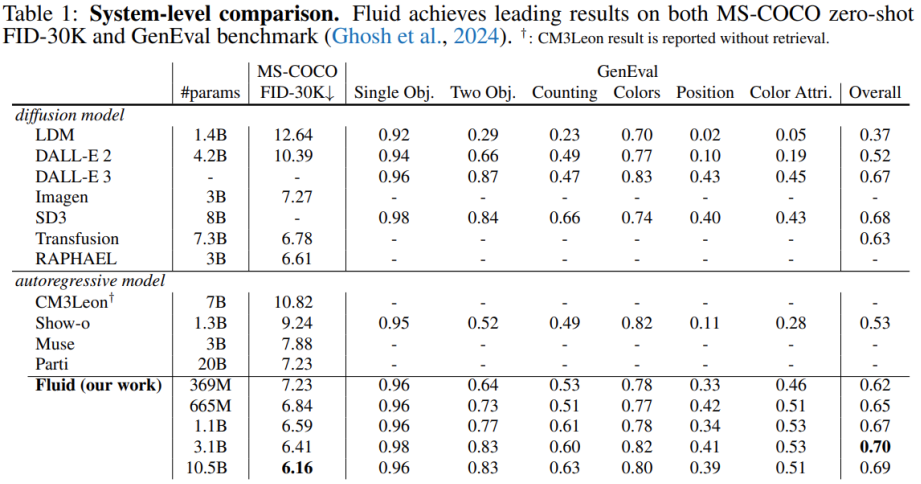 圖 | 不同模型之間的性能對比(來源:資料圖)
圖 | 不同模型之間的性能對比(來源:資料圖)例如,在 GenEval 基準測試的某些子任務中,如位置關係理解和渲染兩個物體,Fluid 模型的表現仍落後於一些最先進的擴散模型。這表明在處理某些特定類型的視覺任務時,不同的模型架構可能各有優勢。
總的來說,這項研究為自回歸文生圖模型的發展開闢了新方向。通過採用連續 Token 和隨機順序生成策略,Fluid 模型成功實現了大規模擴展,在多個關鍵指標上達到或超越了現有最先進的模型。
隨著這一技術的進一步發展和完善,我們或許可以期待看到更多令人驚歎的應用,如更精確的圖像編輯工具、更智能的視覺內容創作輔助工具等等。也可以激發更多人探索自回歸模型在視覺任務中的潛力,推動 AI 在理解和生成視覺內容方面取得新的突破。
參考資料:
https://arxiv.org/pdf/2410.13863
排版:初嘉實











