低內存佔用也能實現滿血訓練?!北理北大港中文MMLab推出Fira訓練框架
Fira團隊 投稿
量子位 | 公眾號 QbitAI
內存佔用小,訓練表現也要好……大模型訓練成功實現二者兼得。
來自北理、北大和港中文MMLab的研究團隊提出了一種滿足低秩約束的大模型全秩訓練框架——Fira,成功打破了傳統低秩方法中內存佔用與訓練表現的「非此即彼」僵局。

展開來說——
為了突破內存瓶頸,許多低秩訓練方法應運而生,如LoRA(分解參數矩陣)和GaLore(分解梯度矩陣)。
 △
△圖1:從宏觀層面分析三種內存高效低秩訓練方法
然而,如上圖所示,LoRA將訓練局限於參數的低秩子空間,降低了模型的表徵能力,難以實現預訓練;GaLore將訓練局限於梯度的低秩子空間,造成了子空間外梯度的信息損失。
相較於全秩訓練,這兩種方法由於施加了低秩約束,會導致訓練表現有所下降。
但是,若提高秩值,則會相應地增加內存佔用。
因此,在實際應用中,它們需要在確保訓練表現與降低內存消耗之間找到一個恰當的平衡點。
這引發了一個核心問題:
能否在維持低秩約束以確保內存高效的同時,實現全秩參數、全秩梯度的訓練以提升表現?
Fira即為最新答案,它有三大亮點:
-
即插即用:Fira簡單易用,其核心實現僅涉及兩行關鍵公式,現已封裝進Python庫,可直接融入現有的大模型訓練流程中,替換原有優化器。代碼示例如下:
from fira import FiraAdamW, divide_paramsparam_groups = divide_params(model, target_modules_list = [「Linear」], rank=8)optimizer = FiraAdamW(param_groups, lr=learning_rate)
-
雙贏解決方案:在維持低秩約束的前提下,Fira實現了大模型的全秩訓練,打破了內存佔用與訓練表現的取捨難題。與此同時,區別於系統方法(如梯度檢查點),Fira不以時間換內存;
-
實驗驗證:Fira在多種規模的模型(60M至7B參數)以及預訓練和微調任務中均展現出卓越性能,優於現有的LoRA和GaLore,甚至能達到或超越全秩訓練的效果。
打造Fira訓練框架
Fira訓練框架由兩部分組成:
1) 基於梯度模長的縮放策略:利用了團隊在大模型低秩和全秩訓練中發現的共通點——自適應優化器對原始梯度的修正效應,實現了低秩約束下的全秩訓練。
2) 梯度模長限制器,通過限制梯度模長的相對增長比例,解決了大模型訓練中常出現的損失尖峰問題。
背景動機
大模型訓練常常面臨顯著的內存瓶頸,尤其是其中的優化器狀態。
舉例來說,使用Adam優化器從頭預訓練一個LLaMA 7B模型(batchsize為1,精度為BF16)可能需要至少58GB內存。
其中14GB用於加載參數,14GB用於儲存梯度,28GB用於儲存優化器狀態,剩下2GB用於儲存激活值。
在這之中,優化器狀態所佔內存甚至要大於參數本身。
因此,使用低秩方法來減少這一部分內存,實現大模型的內存高效訓練十分重要。
而在現有的低秩方法中,LoRA通過分解參數矩陣,使用低秩適配器來減少內存佔用;Galore通過分解梯度矩陣,在自適應優化器中儲存低秩梯度來減少內存佔用。
鑒於使用LoRA低秩適配器方法來實現全參數訓練的困難性,團隊選擇拓展Galore的梯度投影方法來實現全秩訓練。
在Galore中,全秩梯度G
𝑡 ∊ ℝmxn,會被投影矩陣P𝑡 ∊ ℝmxr分解成兩項低秩梯度P𝑡R𝑡和(G𝑡—P𝑡R𝑡),其中
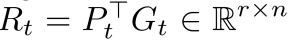
為減少像Adam這樣的自適應優化器在內存中對應的狀態佔用,Galore僅在優化器核心𝞧中保留低秩梯度R𝑡,而非全秩梯度G𝑡。
而另一項梯度(G𝑡—P𝑡R𝑡),則會因為缺少對應的優化器狀態,被Galore直接丟棄,從而造成嚴重的信息損失。
這也解釋了,為什麼Galore的性能會在rank值減小時,顯著衰減。
 △
△圖2:Fira與Galore及其變體的訓練損失對比
為了彌補上述信息損失,最直觀的方法是直接加上這一部分梯度(G𝑡—P𝑡R𝑡):

其中,W是參數矩陣, 𝜂是學習率。
然而,如圖所示,使用這種方法(Galore-add)不僅未能帶來性能提升,反而可能導致訓練過程更加不穩定,且結果更差。
分析原因可歸結於這一部分的梯度缺乏優化器狀態,直接使用會退化為單純的SGD算法,並且可能與前面使用的Adam優化器的梯度不匹配,導致效果不佳。
基於梯度模長的縮放策略
為瞭解決上述挑戰,團隊提出了scaling factor概念,來描述Adam這樣的自適應優化器對原始梯度的修正效應,並揭示了它在大模型的低秩訓練和全秩訓練之間的相似性。

其中,𝜙 就是scaling factor,代表經過優化器修正過的梯度與原始梯度的模長比例。
如下圖,如果根據scaling factor的平均值對參數矩陣進行排序,可以發現低秩和全秩之間的排序非常相似。
 △
△圖3:scaling factor在大模型低秩和全秩訓練間的相似性
基於這個觀察,團隊就嘗試在矩陣層面用低秩梯度R𝑡的scaling factor,作為全秩梯度G𝑡的scaling factor的替代,從而近似地修正(G𝑡—P𝑡R𝑡),彌補其缺少的優化器狀態:
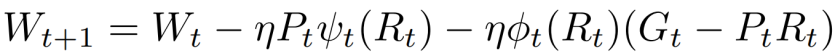
這樣團隊就在低秩約束下成功實現了全秩訓練。
進一步來說,剛才是從矩陣層面來考慮scaling factor。
順理成章地,團隊可以從更細粒度的角度——列的層面,來考慮scaling factor,實現更加精細地修正。

其中R
𝑡,:,𝑖 是低秩梯度R𝑡的第i列,
是scalingfactor的第i項。
梯度模長限制器
在訓練過程中,梯度常常會突然增大,導致損失函數出現尖峰,從而影響訓練的表現。
經過分析,可能原因是Galore在切換投影矩陣時存在不穩定性,以及維持(G𝑡—P𝑡R𝑡)這種原始梯度的方向的方式,無法像Adam這樣的自適應算法,有效應對大模型訓練中存在的陡峭損失景觀。
 △
△圖4:3種Fira變體的訓練損失與梯度模長
然而,常見的梯度裁剪方法(如圖中的Fira-gradient-clipping)由於採用絕對裁剪,難以適應不同參數矩陣間梯度的較大差異,從而可能導致次優的訓練結果。
為此,團隊提出了一種新的梯度模長限制器,它通過限制梯度模長的相對增長比例,來更好地適應不同梯度的變化:

其中𝛾是比例增長的上限,S𝑡=𝜙𝑡(R𝑡)(G𝑡—P𝑡R𝑡)是原始梯度(G𝑡—P𝑡R𝑡)修正後的結果。
通過提出的控制梯度相對增長比例的方法,能夠將梯度的驟然增大轉化為平緩的上升,從而有效穩定訓練過程。
如圖2和圖3所示,團隊的限制器成功避免了損失函數的尖峰情況,並顯著提升了訓練表現。
實驗結果
如下表所示,在預訓練任務中,Fira在保持內存高效的前提下,驗證集困惑度(↓)顯著超過各類基線方法,甚至超越全秩方法。
具體來說,在預訓練LLaMA 1B模型時,Fira節約了61.1%優化器狀態所佔內存,並且取得了比全秩訓練更加好的結果。
 △
△使用C4數據集預訓練不同大小的LLaMA模型驗證集困惑度(↓)對比
在預訓練LLaMA 7B模型時,Fira在使用了比Galore小8倍的秩rank的情況下,訓練表現遠超Galore。
這展現了Fira在大規模大模型上的有效性,以及相較Galore更高的內存減少能力。
 △
△使用C4數據集預訓練LLaMA 7B的驗證集困惑度(↓)對比
在八個常識推理數據集微調LLaMA 7B的任務中,相較其他基線方法,Fira在一半的數據集下表現最好,平均準確率最高的同時實現了內存高效。
 △
△在八個常識推理數據集微調LLaMA 7B準確率對比
另外,消融實驗也顯示了:
-
Fira-w.o.-scaling說明了Fira使用基於梯度模長的縮放策略的有效性;
-
Fira-matrix說明了從更細粒度的列級別,而不是矩陣級別,考慮scaling factor的有效性;
-
Fira-w.o.-limiter說明了Fira中梯度模長限制器的有效性;
-
Fira-gradient-clipping說明了梯度裁剪可能無法完全解決損失尖峰問題,導致結果次優。
 △
△消融實驗
與GaLore相比,Fira的表現幾乎不受秩rank值減少的影響。
在低秩的情況下(rank=16, rank=4),Fira仍然能與全秩訓練相當,相較Galore更加內存高效。
 △
△不同rank下的預訓練驗證集困惑度(↓)
最後,團隊在不同模型大小,以及低秩和全秩條件下,訓練10,000步,並對得到的矩陣和列級別上Scaling factor做平均。
接著,使用了斯皮爾曼(Spearman)和肯德爾(Kendall)相關係數分析了Scaling factor在矩陣和列級別上大小順序的相關性。
其中,Coefficient中1代表完全正相關,-1代表完全負相關,而P-value越小越好(通常小於0.05為顯著)。
在所有規模的LLaMA模型中,Scaling factor在矩陣和列的級別上都表現出很強的正相關關係,並且所有的P-value小於0.05,非常顯著,為Fira中基於梯度模長的縮放策略提供了堅實的實驗基礎。
 △
△矩陣和列級別上的Scaling factor低秩與全秩相似性分析
更多細節歡迎查閱原論文。
論文鏈接:https://arxiv.org/abs/2410.01623代碼倉庫:https://github.com/xichen-fy/Fira










