大模型是否有推理能力?DeepMind數月前的論文讓AI社區吵起來了
機器之心報導
編輯:張倩、陳陳
最近一段時間,隨著 OpenAI o1 模型的推出,關於大型語言模型是否擁有推理能力的討論又多了起來。比如蘋果在前段時間的一篇論文中指出,只要給模型一些干擾,最聰明的模型也會犯最簡單的錯誤。這種現象被歸結為「當前的 LLM 無法進行真正的邏輯推理;相反,它們試圖複製在訓練數據中觀察到的推理步驟」。然而,事實真的是這樣嗎?Google DeepMind 的一篇論文似乎得出了相反的結論。
最近,DeepMind 今年 2 月份的一篇論文在社交媒體上掀起了一些波瀾。

關於該論文的早期報導。
這篇論文題為「Grandmaster-Level Chess Without Search」。文中介紹說,DeepMind 的研究者訓練了一個參數量為 2.7 億的 Transformer 模型,這個模型無需依賴複雜的搜索算法或啟髮式算法就能達到「特級大師( Grandmaster-Level )」的國際象棋水平,優於 AlphaZero 的策略和價值網絡(不含 MCTS)以及 GPT-3.5-turbo-instruct 模型。
這一結果非常有趣,也很容易激發想像力,因為到目前為止,能達到這個級別的計算機國際象棋系統 —— 無論是否基於機器學習 —— 都使用了搜索組件。而 DeepMind 模型不依賴搜索似乎就能達到如此強大的下棋水平。
很多人將其解讀為:這表明 Transformer 不是簡單的「隨機鸚鵡」,而是具有一定的推理和規劃能力。就連該論文的作者也在「結論」部分寫道:「我們的工作為快速增長的文獻增添了新的內容,這些文獻表明,複雜而精密的算法可以被蒸餾為前饋 transformer,這意味著一種範式的轉變,即從將大型 transformer 視為單純的統計模式識別器,轉變為將其視為通用算法近似的強大技術。」

不過,這種解讀也引來了一些爭議。比如,Meta FAIR 研究科學家主任田淵棟指出,論文採用的評估方法 ——「blitz」可能存在一些局限。「blitz」字面意思是閃電戰,在國際象棋中指超快棋。在這種棋賽中,對局每方僅有幾分鐘的時間思考,玩家往往依賴直覺而非深入的搜索和解決問題的能力。此外,模型與機器人對弈時的分數比與人類對弈時的分數要低。田淵棟認為這可能是因為人類在有限的時間內可能沒有機器人那麼擅長髮現戰術上的失誤。所以,這種比賽可能並不足以用來測試模型是否擁有推理能力。

一向喜歡唱反調的紐約大學教授 Gary Marcus 這次也沒有缺席,他也認為論文的結論被誇大了,模型的泛化能力存在嚴重問題。

其實,在今年 2 月份論文剛出來的時候,就有一些研究者寫過關於該論文的質疑文章,有興趣的讀者可以點開閱讀。

博客鏈接:https://arjunpanickssery.substack.com/p/skepticism-about-deepminds-grandmaster

博客鏈接:https://gist.github.com/yoavg/8b98bbd70eb187cf1852b3485b8cda4f#user-content-fnref-3-b6ec0872d32c5df9324eccad8269953b
論文概覽
人工智能最具標誌性的成功之一是 IBM 的深藍(Deep Blue)在 1997 年擊敗了國際象棋冠軍 Garry Kasparov。人們普遍認為,這證明了機器能夠在需要複雜理性推理和戰略規劃的智力領域中超越人類 —— 而這些智力領域一直被認為只有人類才能涉足。
深藍是一個專家系統,它結合了廣泛的象棋知識和啟髮式規則以及強大的樹搜索算法(alpha-beta 剪枝)。幾乎所有當代且更強大的象棋引擎都遵循類似的模式,目前世界上最強大的(公開可用的)引擎是 Stockfish 16。
值得注意的例外是 DeepMind 的 AlphaZero,以及它的開源複製品 Leela Chess Zero(它目前在象棋電腦比賽中經常排名第二),它們使用搜索和自學的啟髮式規則,但不依賴人類的象棋知識。
最近,人工智能系統在擴展方面取得了突破性進展,這使其在認知領域取得了巨大進步,而這些領域對於像「深藍」這樣的早期系統來說仍然具有挑戰性。推動這一進步的是通用技術,特別是在專家數據上進行(自)監督訓練,並大規模應用基於注意力的架構。在此過程中,研究者們開發出了具有令人印象深刻的認知能力的 LLM,如 OpenAI 的 GPT 系列、LLaMA 模型系列或Google DeepMind 的 Chinchilla 和 Gemini。
然而,目前還不清楚同樣的技術是否適用於國際象棋這樣的領域,因為在這一領域,成功的策略通常依賴於複雜的算法推理(搜索、動態規劃)和複雜的啟髮式規則。因此,本文的主要問題是:是否有可能利用監督學習來獲得一種國際象棋策略,這種策略能很好地泛化到新棋局,而不需要顯式搜索?
為了研究這一問題,作者將大規模通用監督訓練的成功秘訣應用於國際象棋(見圖 1)。

作者使用基於注意力的標準架構和標準監督訓練協議來學習預測棋盤的動作 – 值(action-value,對應勝率)。因此,由此產生的國際象棋策略的強度完全取決於底層行動值預測器的強度。
為了獲得大量「真實」動作 – 值的數據庫,作者使用 Stockfish 16 作為預言機,對數百萬個棋盤狀態進行註釋,這些棋盤狀態來自 lichess.org 上隨機抽取的人類對弈棋局。正如論文中展示的那樣,這將產生一個強大的特級大師級國際象棋策略(在 Lichess 平台上的閃擊戰中,該模型對陣人類玩家的 Elo 評分為 2895 分)。該策略由一個當代 transformer 驅動,無需任何顯式搜索即可預測動作 – 值。該策略優於 GPT-3.5- turbo-instruct(也優於 GPT-4)和 AlphaZero 的策略和價值網絡,後者的 Elo 評分分別為 1755、1620 和 1853。
因此,這項工作表明,通過標準監督學習,有可能在足夠大的規模上將 Stockfish 16 的良好近似值蒸餾到前饋神經網絡中 —— 正如 1921 年至 1927 年國際象棋世界冠軍 José Raúl Capablanca 所言:「我只看到前面的一步棋,但它總是正確的一步」。

論文地址:https://arxiv.org/pdf/2402.04494
方法介紹
數據。為了構建數據集,作者從 2023 年 2 月開始在 Lichess (lichess.org) 下載了 1000 萬場遊戲。並從這些遊戲中提取所有棋盤狀態 s,並使用 Stockfish 16 估計每個狀態的狀態值
,時間限制為每局 50 毫秒。
方法。對於預測器,作者使用僅有解碼器的 transformer 作為主幹來參數化離散概率分佈,並對 transformer 的輸出應用 log-softmax 層進行歸一化。因此,模型輸出對數概率。
在動作 – 值預測中,上下文大小為 79,而在狀態 – 值預測和行為複製中,上下文大小為 78。對於動作和狀態 – 值預測,輸出大小為 𝐾,對於行為複製,輸出大小為 1968(所有可能合法動作的數量)。之後作者使用學習到的位置編碼,從而保持輸入序列的長度是恒定的。最大的模型大約有 2.7 億個參數。
Token 化。棋盤狀態𝑠被編碼為 FEN 字符串,作者將其轉換為固定長度為 77 個字符的字符串,其中每個字符的 ASCII 碼即為一個 token。FEN 字符串描述了棋盤上所有棋子的位置、當前輪到哪方、雙方玩家的易位、半步計時器和全步計數器。
作者採用 FEN 字符串中任何可變長度的字段,在必要時用填充的方法,將其轉換為固定長度的子字符串。對於動作,作者以 UCI 表示法存儲動作。為了對其進行 Token 化,作者確定了所有可能的合法動作總共有 1968 個,按字母數字順序(區分大小寫)排序,並取動作的索引作為 token,這意味著動作是由單一 token 描述的。
預測器協議
預測器是離散分佈的,根據預測目標,作者將任務分成三類(參見上圖 1):動作 – 值預測 (AV, Action-value ) 、 狀態 – 值預測 (SV, State-value ) 以及行為複製 (BC, Behavioral cloning )。
基準
作者將本方法與 Stockfish 16、AlphaZero 的三種變體進行了比較,但並沒有和 GPT-4 進行比較,因為他們發現 GPT-4 很難在不做出非法動作的情況下玩完整個遊戲。
實驗結果
表 1 主要評估了具有 9M、136M 和 270M 參數的三個 Transformer 模型。結果表明,這三個模型都表現出對新棋盤的非凡泛化能力,並且可以成功解決大部分謎題。
在所有指標中,擁有更大的模型可以持續提高得分,這證實了模型規模對於國際象棋表現至關重要。最大的模型在與人類玩家的比賽中取得了 2895 Elo,達到大師級別。

圖 2 中作者將 270M 參數模型與 Stockfish 16、GPT-3.5-turbo-instruct 和 AlphaZero 價值網絡的性能進行了比較。實驗中使用了 10k 個謎題的大型謎題集進行實驗。
Stockfish 16 在所有難度類別中表現最佳,其次是本文的 270M 模型。
作者強調,解決謎題需要正確的移動順序,並且由於本文的策略無法明確提前規劃,因此解決謎題序列完全依賴於良好的值估計。
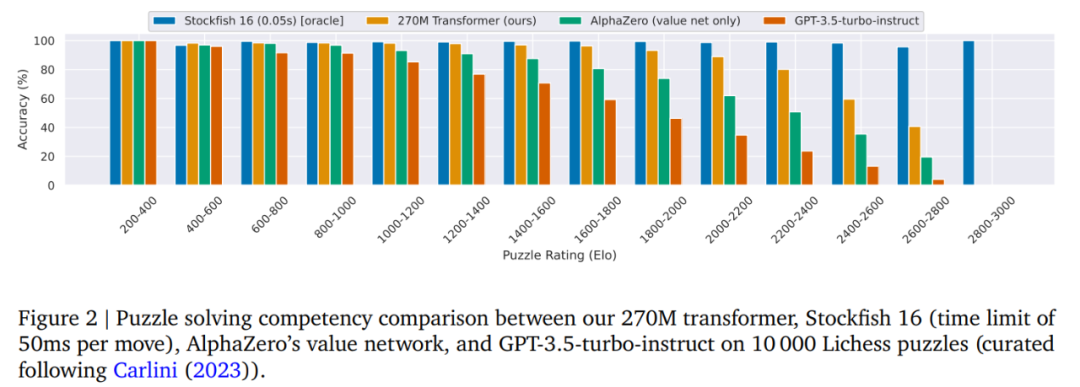 圖 3 展示了對數據集和模型大小進行擴展的分析。
圖 3 展示了對數據集和模型大小進行擴展的分析。對於較小的訓練集大小(10k 個遊戲),較大的架構(≥ 7M)隨著訓練的進行開始過度擬合。
當數據集大小增加到 100k 和 1M 場遊戲時,這種影響會消失。
結果還表明,隨著數據集大小的增加,模型的最終準確率會提高(在模型大小之間保持一致)。同樣,作者觀察到架構大小增加的總體趨勢是無論數據集大小如何,整體性能都會提高。

通過下表 2 可以得出以下幾點:
動作 – 值預測器在動作排名、動作準確率和謎題準確率方面更勝一籌。
模型的性能隨著深度的增加而增加,但似乎在 8 層左右達到飽和,這表明深度很重要,但不能超過某個點。




















