智源研究院:原生多模態世界模型Emu3發佈, 實現視頻、圖像、文本大一統
新浪科技10月23日下午消息,智源研究院近日宣佈原生多模態世界模型Emu3發佈。該模型實現了視頻、圖像、文本三種模態的統一理解與生成。據悉,Emu3只基於下一個token預測,無需擴散模型或組合式方法,便能把圖像、文本和視頻編碼為一個離散空間,在多模態混合序列上從頭開始聯合訓練一個Transformer,展現了其在大規模訓練和推理上的潛力。
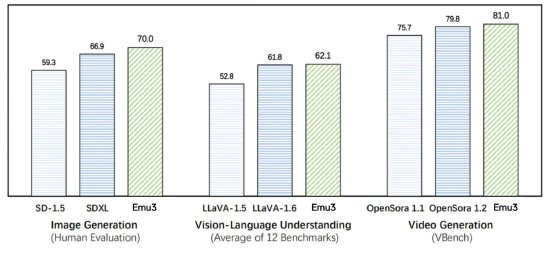
在圖像生成、視覺語言理解、視頻生成任務中,Emu3的表現超過了 SDXL 、LLaVA-1.6、OpenSora等知名開源模型。在圖像生成任務中,人類評估得分Emu3高於SD-1.5與SDXL;在視覺語言理解任務中,12 項基準測試的平均得分,Emu3領先於LlaVA-1.6與LlaVA-1.5;在視頻生成任務中,VBench基準測試得分,Emu3優於OpenSora 1.2。
下一token預測被認為是通往AGI的可能路徑,但這種範式在語言以外的多模態任務中沒有被證明。此前,多模態生成任務仍然由擴散模型(例如 Stable Diffusion)所主導,而多模態理解任務則由組合式的方法(例如 CLIP視覺編碼器與LLM結合)所主導。智源研究院院長王仲遠表示:“Emu3證明了下一個token預測能在多模態任務中有高性能的表現,這為構建多模態AGI提供了廣闊的技術前景。Emu3有機會將基礎設施建設收斂到一條技術路線上,為大規模的多模態訓練和推理提供基礎,這一簡單的架構設計將利於產業化。未來,多模態世界模型將促進機器人大腦、自動駕駛、多模態對話和推理等場景應用。”
目前,智源研究院已將Emu3的關鍵技術和模型開源至國際技術社區。相關技術從業者表示:“對於研究人員來說,Emu3意味著出現了一個新的機會,可以通過統一的架構探索多模態,無需將複雜的擴散模型與大語言模型相結合。這種方法類似於transformer在視覺相關任務中的變革性影響。”(文猛)



















