10秒創造一個世界!吳佳俊團隊新作實時交互式3D世界生成,比現有技術快100倍
WonderWold團隊 投稿
量子位 | 公眾號 QbitAI
史丹福吳佳俊團隊與MIT攜手打造的最新研究成果,讓我們離實時生成開放世界遊戲又近了一大步。
從單一圖像出發,在用戶的實時交互下生成無限延展的3D場景:

只需上傳一張圖片,就能踏入一個由AI創造的虛擬世界。用戶可以通過移動視角和輸入文本提示,實時決定接下來要探索的方向和場景內容:

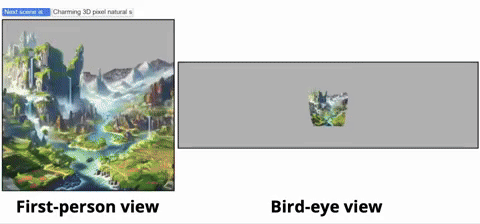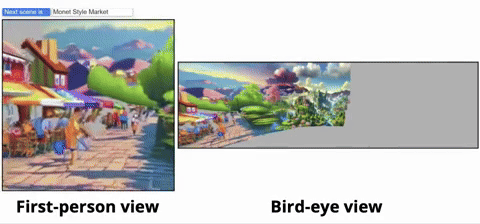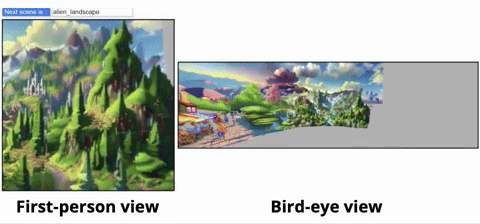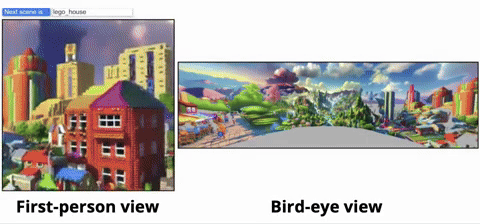
從鳥瞰圖的視角,可以清晰看到虛擬世界的生成過程:

無論是魔幻森林、現實都市,還是寧靜鄉村,WonderWorld都能在眨眼間為你呈現:

這項工作名為WonderWorld,由史丹福吳佳俊團隊和MIT聯合打造。

WonderWorld的項目主頁上還有能以第一視角移動的交互式場景:

資深遊戲創業者,GOAT Gamin的首席AI官興奮地表示:「它還能對非真實感的圖片work。有無限多的可能性!」

在矽谷廣受歡迎的Hacker News上,WonderWorld也一度被放在頭版討論:

要知道,之前的生成式AI方法都需要數十分鐘甚至若干小時才能生成一個單獨的場景,WonderWorld的速度可謂打開了交互式新世界的大門。
那這究竟是如何做到的?
交互式生成 3D 世界
要讓用戶來控制生成一個3D世界,最核心的難點在於生成速度。先前的AI生成3D場景的方法大都需要先逐步生成許多目標場景的2D圖片來補全被遮擋的部分,然後再優化得到一個3D場景的表示。這個過程耗時頗多。

WonderWorld的核心突破在於其驚人的速度。
研究團隊開發的FLAGS (Fast LAyered Gaussian Surfels) 場景表示方法,使得系統能在短短10秒內生成一個新場景。這一速度比現有方法快了近100倍,真正將交互式3D世界生成推向了實時的門檻。
具體來說,WonderWorld生成新場景時,會先生成一張場景的2D圖片(對於第一個場景則是直接使用輸入圖片),從圖片中生成三張layer images,再從layer images來生成 FLAGS 表示。

FLAGS表示由三層Gaussian surfels組成:天空層,背景層,以及前景層。每一層都從對應的layer image中生成。天空和背景的layer image 都單獨進行了遮擋的補全,因此WonderWorld不需要逐步生成多張圖片。
另外,FLAGS表示的每個Gaussian surfel都唯一對應一個layer image 上的像素,因此它可以使用估計的像素級別幾何信息(如單目深度和單目法向量)來初始化Gaussian surfels的參數,從而加速其優化過程。

最後,WonderWorld 還針對多個3D場景之間經常出現幾何「裂縫」的問題,提出了Guided depth diffusion。核心想法是,利用已經生成的3D場景的深度信息作為guidance,使新生成場景的深度與其一致。只要新舊場景在連接處的深度一致,那麼場景的裂縫就得以彌合。

值得一提的是,無論是2D圖片生成還是深度估計模塊,都可以直接採用預訓練模型,因此整個框架不需要任何訓練。
實驗測試
由於先前沒有任何方法可以做到交互式3D場景生成,研究人員採用了連貫3D場景生成的方法WonderJourney,單一場景生成的Text2Room以及LucidDreamer作對比。由於缺乏現有可用評估數據集,研究人員生成了28個場景作為測試。
研究人員首先展示了更多的交互式生成的場景,從而說明WonderWorld可以在應用到不同場景類型以及不同視覺風格:

與基準方法的比較表明,WonderWorld明顯優於各個方法:

從人類偏好評估的角度,WonderWorld 也顯著更受青睞:

此外,從一張輸入圖片,WonderWorld能夠接受不同的用戶控制,生成不同的場景內容:

作者簡介
該篇論文主要作者來自史丹福大學吳佳俊團隊。
論文一作俞洪興,史丹福大學五年級博士生。

主要研究領域為重建可交互的物理世界。他曾獲得 SIGGRAPH Asia 最佳論文獎,高通獎學金,以及 Meta 獎學金和 NVIDIA 獎學金的提名。
吳佳俊,現任史丹福大學助理教授,隸屬於史丹福視覺與學習實驗室(SVL)和史丹福人工智能實驗室(SAIL)。

在麻省理工學院完成博士學位,本科畢業於清華大學姚班,曾被譽為「清華十大學神」之一。
論文鏈接:https://arxiv.org/pdf/2406.09394
參考鏈接:
[1]https://x.com/Koven_Yu/status/1835769026934673595
[2]https://kovenyu.com/wonderworld

















