微調失格?持續反向傳播算法將解鎖新的訓練範式嗎?
機器之心PRO · 會員通訊 Week 43
—- 本週為您解讀 ③個值得細品的 AI & Robotics 業內要事 —-
1. 微調失格?持續反向傳播算法將解鎖新的訓練範式嗎?
當前深度學習有什麼根本缺陷?微調將來不存在了?Dynamic DL 是什麼?反向傳播算法是什麼?持續學習在 LLM中有哪些進展?反向傳播算法會解鎖新的訓練範式嗎?…
2. 從卷文本到卷多模態:國內的大模型公司都在忙什麼?
MLLM 和 LMM 兩種不同思路,哪種更有可能實現多模態交互?未來的通用智能是否一定是多模態智能?在多模態的競爭中,AI 大模型創企、科技大廠、多模態大模型服務廠商推出的產品表現如何?在佈局上,有哪些異同?為什麼說雖然產品數據表現亮眼,但距離實現 PMF 還仍有很長的一段路要走?…
3. 三季度對生成式 AI 投資超 39 億美元:風投仍看好 AI 的長期潛力
第三季度,生成式 AI 的融資情況如何?哪些領域的公司融資情況更好?為何處於早期融資輪次階段的 AI 創企融資更加困難?有哪些大額融資事件值得關注?為什麼投資者依然看好 AI 的長期增長潛力?….
…本期完整版通訊含 3 項專題解讀 + 28 項本週 AI & Robotics 賽道要事速遞,其中技術方面 10 項,國內方面 8 項,國外方面 10 項。
本期通訊總計 23576 字,可免費試讀至 10%
消耗 99 微信豆即可兌換完整本期解讀(約合人民幣 9.9 元)
要事解讀① 微調失格?持續反向傳播算法將解鎖新的訓練範式嗎?
引言:深度學習先驅 Richard S。Sutton 近期在 Amii(阿爾伯塔機器學習學院)發表演講,指出當前的深度學習方法存在根本上的缺陷,進而分享了他對更好的深度學習的願景,並將新的範式命名為 Dynamic Deep Learning。他在該願景下提出了反向傳播算法,解決了當前持續學習中模型可塑性喪失的問題,並為未來能適應動態環境的深度學習網絡指出了可行的方向。
Sutton:現在的深度學習在根本上有缺陷?[31]
大型語言模型會在大型通用訓練集上進行訓練,然後在針對特定應用或滿足政策和安全目標的較小數據集上進行微調,但最後在網絡投入使用前會凍結其權重。就目前的方法而言,當有新數據時,簡單地繼續對其進行訓練通常是無效的。新數據的影響要麼太大,要麼太小,無法與舊數據適當平衡。[32]
1、Sutton 在演講的開頭就直觀地介紹了他對深度學習的願景,他將其稱為 Dynamic Deep Learning(動態深度學習),而這種動態是為了讓深度學習適應持續學習的環境。
① Sutton 強調了持續學習的重要性,即學習應該在每個時刻都在進行。持續學習更接近自然學習過程,所有自然系統(如動物和人類)都在持續學習,而不是在特定階段學習。
② 當前的深度學習是瞬態學習(Transient Learning),其在一個特殊的訓練階段學習,且算法會在持續學習環境中失敗,失去可塑性,產生災難性遺忘,並在強化學習策略中崩潰。
2、圍繞讓深度學習更好地適應持續學習環境的願景,Sutton 提出了 Dynamic Deep Learning 的範式。
① Dynamic DL 的網絡被分為主幹(Backbone)和邊緣(Fringe)兩部分。
② Backbone 是網絡中已經學習且對當前功能重要的部分,應當被保護和保留。Fringe 則是網絡中動態和探索性的部分,它試圖生成對 Backbone 有用的特徵。
3、Dynamic DL 的網絡是動態地逐步構建的,通過逐個單元的增長來實現,而非預先設定的固定結構。如果 Fringe 生成的特徵對 Backbone 有用,它就可以成為 Backbone 的一部分。
4、Sutton 進而探討了尋找、保護和緩慢增長 Backbone 的新想法,以及通過「印記」(imprinting)、「主單元」(master units)和「影子權重」(shadow weights)、「效用傳播」(Utility Propagation)、「持續反向傳播算法」(Continual Backpropagation)以及「步長優化」(Step Size Optimization)在邊緣創建特徵的新想法。
5、Sutton 強調他在演講中的分享的工作僅僅是實現 Dynamic DL 的第一步,尚不完整。他的想法建立於許多已完成的工作,部分研究已經發表,而其他案例則出現在別人的論文中。
① Sutton 在演講中提到了一種持續反向傳播方法。該方法出自 Sutton 團隊 8 月 21 日發表於 Nature 上的論文《Loss of plasticity in deep continual learning》,該工作解決了深度學習網絡在持續學習環境中會失去可塑性的問題。[32]
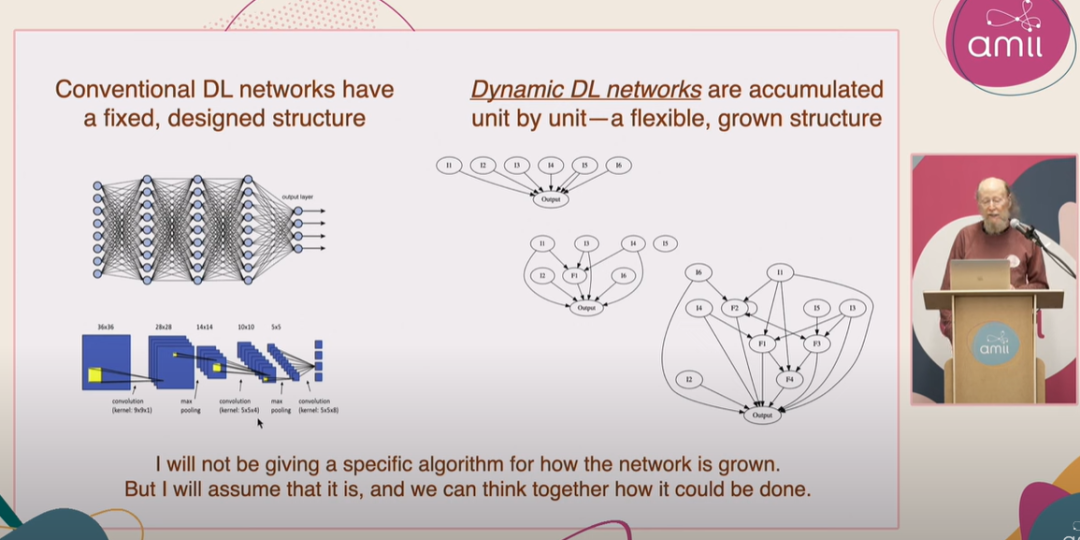
圖:Sutton 演講中展示 Dynamic Deep Learning 網絡的特徵。這種網絡會逐個單元積累,從只有一個輸出節點和許多輸入開始成長,不斷引入中間的特徵單元(有用的 Fringe),然後不斷增加 Bakebone 單元,最終成為一個大型的多層網絡。[31]
持續反向傳播算法瞭解一下?[32]
持續反向傳播算法最初由 Sutton 在 CoLLAs 2022 會議中,題為「Maintaining Plasticity in Deep Continual Learning」 的演講中提出[33] 。而後,Sutton 團隊在 2024 年 9 月於《Nature》發表論文《Loss of plasticity in deep continual learning》,闡述了持續反向傳播的技術細節。[32]
1、持續反向傳播算法是 Sutton 團隊提出的一種反向傳播的變體,解決標準深度學習方法在持續學習環境中遇到的可塑性喪失問題。
① 現有方法往往是一個階段更新網絡權重,另一個階段在使用或評估網絡時權重保持不變。這與許多需要持續學習的應用程序形成鮮明對比。
② 持續反向傳播算法的核心思想是選擇性地對網絡中貢獻效用(contribution utility)較低的的單元進行初始化處理,從而向網絡注入可變性並保持其某些權重較小,實現無限期地保持深度網絡的可塑性(Plasticity)。
2、選擇性初始化的思想受到了 2012 年 Mahmood 和 Sutton 提出的生成和測試方法的啟發。該方法只需要生成一些神經元並測試它們的實用性。持續反向傳播算法將這一概念擴展到多層網絡,並使用深度學習方法進行優化。[34]
3、該工作定義了一個名為「貢獻效用」的值來衡量每個單元的重要性。貢獻效用通過計算即時貢獻的移動平均值來衡量,這個值由衰減率表示。
① 如果一個隱藏單元對下遊單元的影響很小,那麼它的作用可能會被網絡中其他更有影響力的隱藏單元掩蓋。
② 在前饋神經網絡中,每個隱藏單元的貢獻效用會根據其輸出和下遊單元的權重進行更新。當一個隱藏單元被重新初始化時,它的輸出權重將被初始化為零,以確保新添加的隱藏單元不會影響模型已經學到的功能。
4、為了防止新的隱藏單元很快被重新初始化,研究團隊設置了「成熟閾值」(maturity threshold),在一定次數的更新前,即使新的隱藏單元的效用是零,也不會被重新初始化。
① 當更新次數超過成熟閾值後,每一步中會有一定比例的「成熟單元」(mature unit)被重新初始化。這個比例稱為替換率,通常設置為一個非常小的值,這意味著在數百次更新後只替換一個單元。
5、最終的持續反向傳播算法結合了傳統的反向傳播和選擇性重新初始化兩種方法,以持續地從初始分佈中引入隨機單元。每次更新時,持續反向傳播將執行梯度下降並選擇性地重新初始化。