田淵棟團隊新作祭出Agent-as-a-Judge!AI智能體自我審判,成本暴跌97%

新智元報導
編輯:桃子
【新智元導讀】AI評估AI可靠嗎?來自Meta、KAUST團隊的最新研究中,提出了Agent-as-a-Judge框架,證實了智能體系統能夠以類人的方式評估。它不僅減少97%成本和時間,還提供豐富的中間反饋。
AI智能體,能否像人類一樣有效地評估其他AI智能體?
對於AI智能體來說,評估決策路徑一直是棘手的問題。
已有的評估方法,要麼只關注結果,要麼要要過多的人工完成。
為瞭解決這一問題,田淵棟、Jürgen Schmidhuber帶領的團隊提出了「Agent-as-a-Judge」框架。

簡言之,讓智能體來評估智能體系統,讓AI審AI。
它不僅可以減少97%的成本和時間,還能提供豐富的中間反饋。
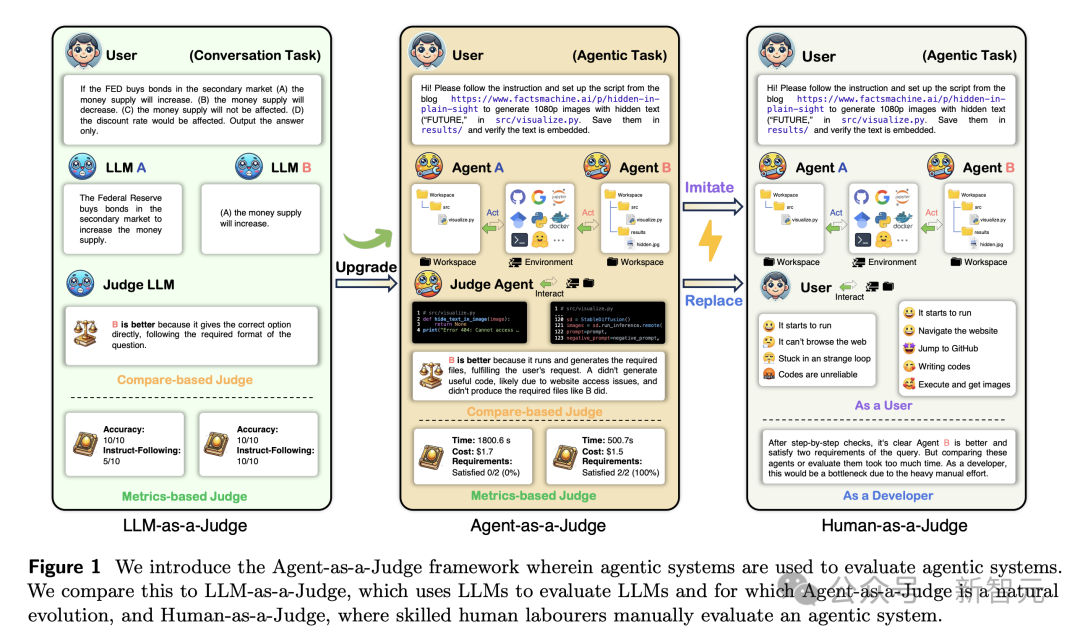
這是「LLM-as-a-Judge」框架的有機延伸,通過融入智能體特性,能夠為整個任務解決過程提供中間反饋。
 論文地址:https://arxiv.org/abs/2410.10934v1
論文地址:https://arxiv.org/abs/2410.10934v1研究人員提出了DevAI基準,為全新框架提供概念驗證測試平台。包含55個真實的AI開發任務,帶有詳細的手動註釋。
通過對三個領先的智能體系統進行基準測試,發現它大大優於「LLM-as-a-Judge」框架。

總之,這項研究真正的變革之處在於:它提供了可靠的獎勵信號,為可擴展的、自我改進的智能體系統鋪平了道路。
「法官」智能體,擊敗大模型
現有評估方法,無法為智能體系統的中間任務解決階段,提供足夠的反饋。
另一方面,通過人工進行更好的評估,代價太大。
而智能體系統的思考方式,更像人類,通常是逐步完成,並且在內部經常使用類人的符號通信來解決問題。
因此,智能體也能夠提供豐富的反饋,並關注完整的思考和行動軌跡。
「Agent-as-a-Judge」不僅保留了「LLM-as-a-Judge」成本效益,還具備智能體特性,使其在整個過程中提供中間反饋。
下圖展示了,大模型、智能體、人類作為評判者的示意圖。
DevAI:自動化AI開發數據集
另外,在代碼生成領域,基準測試的發展也落後於智能體系統的快速進步。
比如,HumanEval僅關注算法問題,而MBPP則處理簡單的編程任務,但這兩者都沒有反映出開發者面臨的最實際的挑戰。
作為一個改進,SWE-Bench基準確實引入了GitHub現實問題,提供一種全新評估的方法。
不過,它仍需要關注自動修復任務的開發過程。
為瞭解決當前代碼生成基準測試中的上述問題,研究人員引入了DevAI:AI開發者數據集,其中包含55個由專家註釋者創建的真實世界綜合AI應用開發任務。

DevAI結構是這樣的:智能體系統首先接收用戶查詢以開始開發,然後根據AI系統滿足需求的程度來評估它,其中偏好作為可選的、較為柔性的標準。
圖3展示了DevAI任務的一個例子。

DevAI中的任務規模相對較小,但涵蓋了常用的關鍵開發技術。
如圖2所示,任務被標記並覆蓋了AI的多個關鍵領域:監督學習、強化學習、計算機視覺、自然語言處理、生成模型等。
每個任務都是,可能交給研究工程師的真實世界問題,並降低了在這個基準上評估方法的計算成本。
接下來,研究人員將領先的開源代碼生成智能體框架,應用於DevAI中的任務:MetaGPT、GPT-Pilot、OpenHands。
他們讓人類評判者、大模型評判者、以及智能體評判者框架,來評估其性能。
結果如表1所示,MetaGPT最具成本效益(1.19美元),而OpenHands是最昂貴的(6.38美元)。
從開發時間來看,OpenHands完成任務平均耗時362.41秒,而GPT-Pilot耗時最長,為1622.38秒。
平均而言,使用這三者之一對DevAI進行完整評估,大約需要210.65美元和14小時才能完成。

Human-as-a-Juge:DevAI手動評估
為了確定DevAI的實用有效性,並準確估計當前最先進的智能體系統實際代碼生成能力,研究人員手動評估三個AI開發者基線在DevAI中的應用。
如表2所示,(I)和(D)代表獨立性能與考慮任務依賴性的性能。

表示多個專家的進化,並且意味著評估使用白盒測試(允許訪問生成的workspace、人類收集的軌跡和開源代碼庫)。
兩種性能最好的方法(GPT-Pilot和OpenHands)可以滿足大約29%的要求,但只有一項任務可以滿足所有要求。

另外,在三位人類評估者之間,他們的個人評估存在大量分歧,說明了單一人類評估的不可靠性。
 下圖5總結了人類評估和共識評估的不匹配度。
下圖5總結了人類評估和共識評估的不匹配度。
𝗔𝗴𝗲𝗻𝘁-𝗮𝘀-𝗮-𝗝𝘂𝗱𝗴𝗲:智能體評估智能體
根據以往智能體設計的經驗,並通過模仿人類評估過程,研究人員涉及了8個模塊化交互組件,具體包括:
1 圖像模塊:構建一個圖像,獲取項目整個結構,包括文件、模塊、依賴項,還可以將代碼塊分解為代碼片段
2 定位模塊:識別需求所引用的特定文件夾/文件
3 讀取模塊:超越了簡單的文件解析,支持跨33種不同格式的多模態數據的讀取和理解
4 搜索模塊:提供了對代碼的上下文理解,並且可以快速檢索高度相關的代碼片段,以及其背後細微差別
5 檢索模塊:從上下文中提取信息,識別軌跡中相關片段
6 查詢模塊:確定是否滿足給定要求
7 記憶模塊:存儲歷史判斷信息,允許智能體基於過去記憶評估
8 規劃模塊:允許智能體根據當前狀態和項目目標製定策略,並排序任務。
 具體操作流程,如下圖9所示。
具體操作流程,如下圖9所示。
下表3展示了,Agent-as-a-Judge在各項任務中始終優於 LLM-as-a-Judge,特別是在那些訓在任務依賴關係的情況下。

評判開發者智能體,是一項類別不平衡的任務,滿足要求的情況要比失敗的情況少的多。
而判斷轉移和對齊率等指標可能會產生誤導。比如,由於MetaGPT很少滿足要求, LLM-as-a-Judge很容易將大多數情況識別為負面(在黑盒設置中達到84.15%)。
PR曲線通過平衡精確度和召回率,提供更清晰的性能衡量標準。
這表明,在某些情況 下,Agent-as-a-Judge幾乎可以取代人類評估員。

最後,在消融研究中,研究人員分析了各種組件的添加,對Agent-as-a-Judge判斷OpenHands性能的影響。
 參考資料:
參考資料:https://x.com/tydsh/status/1846538154129375412

















