算力通縮下的「老黃經濟學」
雨天週末,不想讀書不想學習,就想扯淡。
先吐個槽,最近看到某DPU廠商80億估值然後因為各種原因玩不下去了的公眾號文章,然後還有一個會還在討論DPU怎麼怎麼的……我還記得三四年前和某個機構一起基本上把這些廠家都調研過,當時就不停地diss這群人沒想明白,但似乎幾年過去還是沒想明白。
不過最近似乎想明白了一點為什麼叫DPU了,從Pradeep在互聯網泡沫時期創建的Juniper,到後面離職創建Fungible,其實DPU的意思是從網絡需要處理數據的視角定義的,但是到後來逐漸演進的過程中,老黃把DPU的概念發揚光大後,發現這詞還是有問題,這不又SmartNIC和DPU都無法定義,又開始造出了一個SuperNIC了麼?
倒是Tesla人間清醒的一個DumbNIC講的很清楚,大道至簡順便還把HBM-Disaggragation搞了……
回到正題,在算力通縮情況下,老黃如何維持或者進一步衝高到五萬億市值是一個很有趣的話題,所以今天從經濟學的角度扯個淡……渣B也沒正經地讀過經濟學的書,另一方面對於建模的量化數據因為合規原因,沒有數據也沒有意願去瞭解數據,因此也不作過多的分析了,只是單純地扯個淡而已。
一、什麼是算力通縮
上週一篇《把GPU當成一個金融產品如何加槓桿?》談到了算力通縮(computility deflation,以下簡稱CD), 首先我們來給CD一個定義:
算力通縮(computility deflation,CD):在經濟學中,通貨緊縮是指商品和服務總體價格水平的下降。從算力的角度來看,我們也可以定義平均1GFLOPS的價格作為GPU和算力服務的總體價格水平。
就算力服務價格(以租用H100等GPU)的價格來看, 總體價格是在下降的。例如H100的租金價格從4美元一小時如今降到不到2美元一小時。而從GPU本身的商品價格來看,國內一些H100的整機價格也從早期的300多萬降到了220萬。
二、經濟學的悖論
一般來說,我們簡單地以經濟學中的IS-LM模型來看,也就是說供給增加或者需求下降或者兩者同時發生引起的。簡單來說就是供給過量(過量生產),需求低迷(消費減少),或者是信貸緊縮等帶來的貨幣供應減少而產生的。
當然有另一種觀點是,通縮和經濟中的技術進步有關,隨著全要素生產率的提高,商品成本會下降。也就是老黃期待的需要一年一代新卡來降低算力架構。
有一個悖論的地方是H100售價3萬美金,而物料成本大概只有3000美金,HBM成本佔了2000。在算力通縮背景下,如何能夠持續性地維持高Margin,同時還能通過不停的迭代增加營收來衝高市值?
歸根結底還是要回答一個問題:錢從哪兒來,錢期望的收益率曲線是什麼?
從貨幣供應的角度來看,針對AI的投資並沒有減緩,OAI這一輪的融資還算正常,然後H100/H200的需求還在持續,國內各地的「智算中心」項目也還在持續的建設中。全球來看Blackwell也供不應求。
但是反過來看有一個很有趣的觀點,到底是誰在為這些投資買單?錢從哪兒來的?投資回報率怎麼估計?槓桿率是多少?特別是從算力提供方來看,算力自身由於技術迭代產生貶值非常快(算力服務價格和算力商品價格都在加速下滑),既然算力通縮背景下,為什麼不延遲消費,再等等新卡?另一方面對於基礎設施投入的槓桿加在什麼地方?智算中心建設的ROI如何計算?
最近還有一種觀點是在互聯網泡沫時期的基礎設施為後來互聯網蓬勃發展奠定了基礎,特別是大量的海底光纖的成本在後期是完全收回來了的。但是對於智算中心的成本,或許要在幾年後收回從投資回報率的角度是很難的。對此我一直持比較負面的態度,只有少數幾家規模大有可能收回一部分,對於它們來說,算力投資的風險並不是太大。
1. Azure,微軟通過OAI投資和更上層的copilot業務收入可以填補,同時也在佈局自己的推理芯片;
2. Meta,大量的H100通過Llama的生態以及內部的推薦系統可以攤薄成本,同時也有自己的推理芯片;
3. AWS Trainium/Google Trillium(TPU)的供應量具體數值不清楚,但是至少Google自家的搜索等業務還是有大量的算力消耗的;
4. Tesla的自動駕駛,字節等企業的搜廣推以及影片生成等業務上,大量的H100的消耗實際上也不會帶來很大的虧損。
至於各地建設的各種智算中心, 是不是過兩年要開始不良資產處置了呢? 不良的定義和定價還分兩種情況:
1. 不良算力資產處置
2. 算力不良資產處置
即不良算力本身的評估:先還不要說那些各種以DSA卡建設的算力集群了……簡單的以NV H系列卡為例,初期很多人以為買點機器回來插上電給個管理口IP地址就可以賣了,然後發現網絡建設也需要跟上,還有就是穩定性和故障運維,緊接著發現如果要尋推一體,又要搭一個存儲集群,然後還有互聯網帶寬……
另一個問題是:算力通縮和不良算力以及算力不良本身是否有很大的關係, 需要考證一下?
三、算力的槓桿
槓桿的產生通常是在時間維度上帶來的,例如在期貨市場上通過保證金來對遠期交割物達成一個協議,另一方面就是對於大型基礎設施建設通過融資租賃的方式。本質上還是要在近期創造出一個巨大的需求,然後通過遠期相對確定的現金流來完成。
而本質上解決通縮的方法大概就是: 增加貨幣供給,以及擴大總需求。
3.1 Scaling-Law: 需求的創設
最簡單明顯的需求創設就是老黃經濟學中的「The More You Buy,The More You Save」。
從pre-train scaling-law構造了一個宏大敘事: 從千卡的A100到萬卡的H100再到10萬卡的訓練,但很顯然的是OAI在GPT-5的訓練上遇到了蠻大的麻煩。但在整個槓桿賭局里,沒有一方會那麼容易的平倉認輸,以至於Inference Scaling-law的出現。
另一方面這樣的槓桿也在吞噬著市場里的玩家,花一個億預訓練的模型成了貶值最快的商品,更大的模型有幾家跟?國內所謂六小虎的情況以及前幾天剛爆出ST的裁員……
3.2 供應端的流動性緊縮
對於供給過量的問題,首先來談一談存量市場。其實H100的存量市場會清洗出一大批玩家,對於H100的估值可能還存在爭議,那麼我們以現階段對一些A100/A800算力中心的不良資產估值該怎麼做?這些需要考慮算力的時間價值和資金的時間價值。我們單獨放一章來談。
那麼我們來談另一個話題:為什麼新卡的供應上,微軟等幾個巨頭要瘋搶GB200?一方面是後一節講的算力的時間價值,新卡出來的前幾個月的需求是非常旺盛的,同時帶來的流動性溢價會產生更好的短期現金流。這對算力商品提供方(NV)和算力服務提供方(Azure等)都是有利的,但是前提是要構造出足夠的需求來支付這樣的短期現金流,那麼也就只能進一步的找一個算力消耗方,然後通過更遠的現金流預期在解決期限錯配的問題。
四、算力的時間價值
既然上了槓桿,那麼資金的成本和對應的算力通縮下算力的時間價值就是一個我們值得探討的問題。本質上很多機構對大規模投資的短期回報逐漸產生質疑和喪失耐性了,畢竟ChatGPT也出來快滿兩年了,但是大量的投資似乎還暫時看不到回報。
另一方面隨著時間的流逝,當年搶購的H100逐漸出現商品價格和服務價格的快速下滑,這也讓一些算力投資方逐漸感受到了風險,接下來隨著Blackwell的出現,H100的貶值速度還會進一步加快,整個H系列的成本攤銷週期似乎和兩年前預測的週期也在縮短。
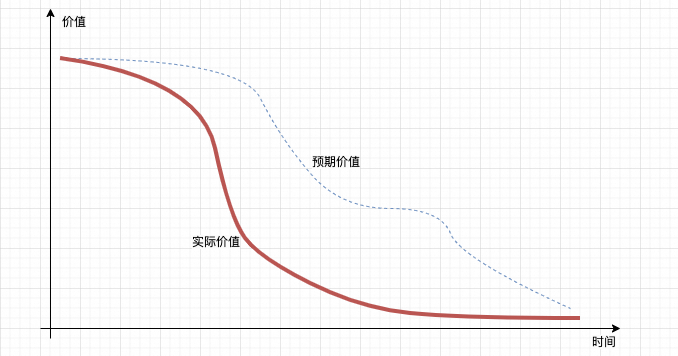
也就是說實際上算力價格的TimeDecay速度遠超過了當初投資的現金流模型,這種期限錯配產生的不良資產處置,是一個非常有趣的話題,但是就點到為止吧。
五、談談貨幣投放受限下的算力通縮
其實寫了這麼多並不是說在反對Scaling-Law或者說是看空AIGC,其實任何新技術的出現都是醜陋且反直覺的,但是算力的問題除了基礎設施迭代外,更多的還是需要算法去解決。渣B以前的量化算法複雜度從剛開始研究的時候也是因為計算複雜度基本上一次全量計算需要30天左右,因此從那個時候開始就在折騰一些並行計算的框架,但是後來還是算法上的優化解決的問題。
而對於這一次AIGC來看,從根本上我持有一個懷疑態度是新的數學工具並沒有應用於模型之上,這個直接決定了當前生成式大模型的天花板,雖然當前的天花板足夠高足夠容納很多想像空間。但總是覺得哪裡不對,舉個例子吧,例如為了網絡規模和深度採用LayerNorm等帶來的訪問內存壓力,是否有更好的算法來解決?
另一方面是基礎設施上,是否有不需要NVLink,不需要CoWoS,不需要HBM的基礎設施,哪怕是訓練不行,先擼一下對算力需求相對較低一些的推理場景》例如蘇媽出一個多帶一點PCIe接口的多帶一些GDDR的家用級顯卡,並且放開GDR,讓一些買不起H100又要做大模型研究的中小規模團隊先用起來,放低一下姿態實在是生態不行,不談rocm,光拿來給NV做內存池的二奶都行?在NV帶來的流動性緊缺上繞開CoWoS和HBM,從而打開一個突破口,即便是數據中心賣得不好,擼掉NV家用卡RTX的市場也是好事?
大概就胡扯這麼多吧,其實蠻希望若干年後,我們能對這一場槓桿局做一些總結和回顧,特別是監管層的視角。歷史雖然不會簡單地重覆, 但是每次都會押韻。
本文來自微信公眾號:zartbot,作者:渣B


















