時序大模型突破十億參數!新混合專家架構,普林斯頓格里菲斯等機構出品
TimeMoE團隊 投稿自 凹非寺
量子位 | 公眾號 QbitAI
時序大模型,參數規模突破十億級別。
來自全球多隻華人研究團隊提出了一種基於混合專家架構(Mixture of Experts, MoE)的時間序列基礎模型——Time-MoE。
據瞭解,該模型首次將時間序列預訓練大模型的參數規模推向十億級別。
Time-MoE模型通過MoE架構的獨特優勢,將模型參數成功擴展至24億,不僅顯著提升了預測精度,還在降低計算成本的同時超越了眾多現有模型,全面達到了SOTA(State of the Art)水平。

與此同時,團隊精心整理了預訓練數據集Time-300B,這是目前時序領域最大的公開數據集,為各類時序任務提供了通用解決方案。
十億參數時序大模型
這篇文章主要有以下三點技術突破:
強大的混合專家架構:Time-MoE採用稀疏激活機制,在預測任務中僅激活部分網絡節點,這不僅確保了高預測精度,還顯著降低了計算負擔,完美解決了時序大模型在推理階段的計算瓶頸。
靈活的預測範圍:Time-MoE支持任意長度的輸入和輸出範圍,能夠處理從短期到長期的各種時序預測任務,實現了真正的全域時序預測。
全球最大規模的開源時序數據集:團隊開發了Time-300B數據集,涵蓋9個領域的超過3000億個時間點,為模型提供了豐富的多領域訓練數據,確保其在多種任務中的卓越泛化能力。

在相同激活參數條件下,Time-MoE顯著超越了現有的時序基礎模型。在相同的FLOPs下,其稀疏架構展現出相較於密集模型的卓越精度優勢。
模型框架:

輸入Token Embedding
Time-MoE使用逐點分詞方法以確保時間序列信息的完整性,提高了模型處理不同長度序列的靈活性與適用性,如模型框架圖中①所示。在②中,SwiGLU激活函數對每個時間序列點進行嵌入,其中包括一個Feed-forward network (FFN) 和一個Swish FFN,從而增強模型對多維輸入的處理能力:

MoE Transformer模塊
Time-MoE基於decoder-only Transformer,並結合了大規模語言模型中的最新技術。Transformer模塊里, RMSNorm對每個子層輸入進行了歸一化處理,從而提升了訓練的穩定性。同時,採用旋轉位置編碼代替絕對位置編碼,使得模型在處理可變序列長度時具備更好的外推能力。此外,模型引入了稀疏激活的混合專家層來取代標準Transformer模塊里的FFN。公式化概括如下:

其中Mixture代表混合專家層。如模型框架圖中③所示,單個時間序列數據點可以被分配給一個或多個專家。通過選擇部分專家網絡來處理特定時間點的輸入,模型的計算效率得到了提高。

多解像度預測
如模型框架圖中④和⑤所示,Time-MoE設計了一種多解像度預測頭,可以同時進行不同尺度的預測,突破了單一尺度預測的局限。在訓練時,不同解像度頭會被聯合優化。
在與推理時,模型採用貪心算法,利用不同尺度的輸出組合成任意的預測長度。這種設計允許模型根據不同的預測範圍進行靈活預測,並在訓練過程中綜合多個預測尺度的誤差來優化模型的泛化能力,從而顯著提升預測的準確性和魯棒性。
實驗效果
零樣本Zero-shot預測
零樣本預測能有效檢驗時序基礎模型的泛化能力和通用性。實驗表明,與現有的時序基礎模型相比,Time-MoE達到了最好的預測效果,均方誤差(MSE)降低了約20%。

全樣本Full-shot預測
在全樣本預測中,預訓練的Time-MoE會使用相應數據的訓練集進行微調。
實驗表明,與專門為全樣本預測設計的時序模型相比,Time-MoE依然能達到最優的效果, MSE降低了約24%。這體現了模型對於不同領域數據的適用性,以及預訓練基礎模型對於下遊任務幫助的有效性。

消融實驗
文中進一步提供了一系列消融實驗來驗證模型框架設計的合理性。實驗表明,Time-MoE的設計在提升模型精度上是有效的。特別地,在不使用混合專家的情況下,模型的MSE會有明顯的退化。

Scalability 分析
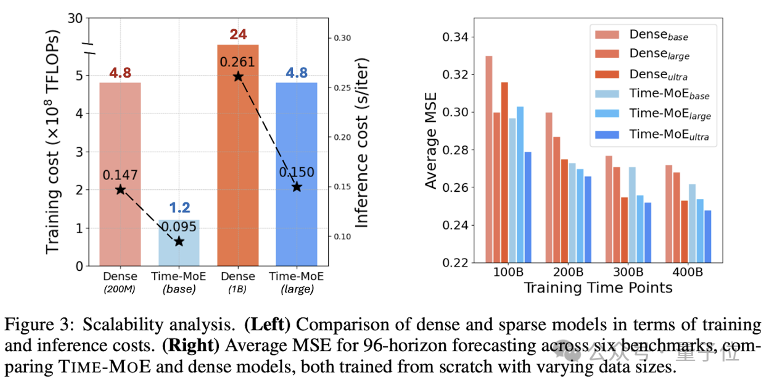
作者對於模型的規模化效果進行了詳細分析,如下圖所示。左圖的實驗表明,與稠密模型相比,稀疏模型減少了平均78%的訓練成本和39%的推理成本。右圖的結果表明,隨著數據量和模型參數的增大,Time-MoE持續表現出穩定的性能提升,並且與同規模的稠密模型相比,總能達到更小的MSE和更好的預測性能。
此外,作者還分析了訓練精度的影響。如下表所示,與使用float32精度進行訓練相比,使用bfloat16精度能得到相似的預測性能,但是bfloat16模型能在訓練速度上獲得12%的提升,內存佔用上有 20%的減少。
此外,bfloat16還可以與flash-attention(表中簡稱為FA)無縫結合,從而進一步在訓練和推理速度上帶來23%和19%的提升。

Time-MoE不僅在性能上超越了現有模型實現SOTA,更為構建大規模、高效、通用的時序預測基礎模型提供一個可行的範式。除此之外,Time-MoE在工業界的多種時序場景也很有應用潛力,比如在能源管理、金融預測、電商銷量、氣象預報等領域。
論文地址:
https://arxiv.org/pdf/2409.16040
Github地址:
https://github.com/Time-MoE/Time-MoE


















