突破時間序列組合推理難題,南加大發佈一站式多步推理框架TS-Reasoner
【導讀】TS-Reasoner是一個創新的多步推理框架,結合了大型語言模型的上下文學習和推理能力,通過程序化多步推理、模塊化設計、自定義模塊生成和多領域數據集評估,有效提高了複雜時間序列任務的推理能力和準確性。實驗結果表明,TS-Reasoner在金融決策、能源負載預測和因果關係挖掘等多個任務上,相較於現有方法具有顯著的性能優勢。
隨著近年來大型語言模型(LLMs)的迅速發展,學術界對將其應用於時間序列分析領域表現出濃厚的興趣。
時間序列分析在金融、能源管理、氣候科學、自然科學和社會科學等眾多關鍵領域中發揮著至關重要的作用,影響著從經濟預測到事件檢測、從能源調度到氣候變化建模等廣泛應用。
然而,儘管已有許多模型在特定的時間序列任務上取得了顯著成果,現有的方法仍然面臨諸多挑戰。
首先,大多數模型主要專注於單一任務,如時間序列預測、異常檢測或分類,缺乏在多任務環境中的靈活性。現實應用中常常需要多步推理過程,將多個已確立的任務作為中間步驟。

此外,這些模型在上下文推理和多步推理能力方面存在不足。雖然在處理時間模式上表現良好,但難以應對需要結構化多步推理的複雜任務。這種局限性在需要綜合多個時間序列信息的復合問題中尤為突出,限制了模型在複雜應用場景中的適用性。
為了應對這些挑戰,南加州大學的研究人員提出了一種全新的時間序列推理範式——TS-Reasoner:利用大型語言模型的上下文學習和推理能力,將複雜的時間序列任務分解為結構化的多步推理過程,實現對複雜問題的高效解決。

論文地址:https://arxiv.org/pdf/2410.04047
不同於傳統的程序輔助推理系統,TS-Reasoner 支持創建自定義模塊,能夠適應外部知識和用戶指定的約束,具有高度的靈活性和可擴展性。
這種高度的靈活性不僅增強了模型應對複雜時間序列任務的能力,還使其在需要嚴格約束的領域(如氣候建模和投資組合)中表現出色。
此外,TS-Reasoner 的模塊化設計使其易於擴展和定製,能夠根據不同應用場景集成特定的領域知識和約束條件。這一特性使得模型在金融、能源以及氣候監測等領域具有廣泛的適用性,進一步提升了其在實際應用中的價值和影響力。
背景與挑戰
然而,時間序列分析領域面臨著一系列獨特的挑戰,這使得直接將大型語言模型(如 GPT-4、LLaMA 等)的成功經驗應用於處理複雜和復合時間序列推理任務並不現實。
這些挑戰包括:
1. 缺乏多步推理能力:現有的時間序列模型主要專注於提高單一任務的性能,如預測、異常檢測和分類等。它們通常為特定任務而設計,缺乏處理需要綜合多個任務和領域知識的複雜多步驟推理能力,難以滿足現實世界中複雜應用的需求。
2. 難以整合領域知識和外部約束:在實際應用中,科學家和工程師需要將領域知識(如物理定律、業務規則)與統計分析相結合。例如,在能源供應預測中,需要基於特定約束優化預測結果。然而,現有模型在整合外部知識和用戶指定的約束方面存在局限,限制了其在專業領域中的適用性。
3. 模型的靈活性和可擴展性不足:傳統的時間序列模型通常為特定任務和數據結構設計,缺乏在複雜多任務環境中的靈活性。它們難以適應不同領域和多樣化的數據特性,無法在多任務、多模態的環境中有效工作。
4. 缺乏端到端的任務執行框架:由於在結構化推理和時間信號的數值計算交叉點上的研究較少,實現端到端的時間序列任務執行仍然面臨挑戰。現有方法往往需要跨學科專家的協作,流程繁瑣,耗時長,且中間任務通常是獨立優化的,導致效率低下。
5. 對複雜復合任務的適用性有限:現有模型在處理需要結構化多步推理的複雜任務時表現不佳,無法充分利用大型語言模型的上下文學習和推理能力。這種局限性在需要綜合多個時間序列信息的復合問題中尤為突出,限制了模型在複雜應用場景中的表現。
模型創新
為瞭解決上述問題,本文提出了一種新的多步推理框架——TS-Reasoner。該框架結合了大型語言模型(LLMs)的上下文學習能力與推理能力,能夠實現對複雜任務的結構化分解以及多步推理。TS-Reasoner通過將複雜的推理任務分解為多個可執行的步驟,並利用預定義的程序模塊和用戶自定義模塊來逐步解決這些任務。
TS-Reasoner模型通過以下幾個方面的創新來應對時間序列推理的挑戰:
1. 程序化多步推理
傳統的時間序列模型通常專注於單一任務推理,難以應對複雜的多任務推理問題。TS-Reasoner通過引入程序化的多步推理,利用LLMs生成的程序來對複雜任務進行分解,並調用時間序列模型與數值方法模塊來執行每一步的推理任務。這種方法能夠將結構化的推理步驟與時間序列數據的數值計算結合起來,有效提高模型在複雜任務中的表現。
2. 模塊化設計
TS-Reasoner框架內置了多個用於時間序列分析的模塊,包括趨勢檢測、波動性檢測、預測等。這些模塊通過預先訓練的時間序列模型和數值方法進行操作,確保任務分解後的每個步驟能夠高效執行。此外,TS-Reasoner還允許用戶生成自定義模塊,以適應外部知識或用戶特定的約束需求,極大提升了系統的靈活性和適應性。
3. 自定義模塊生成
為了處理用戶在複雜推理任務中的特定需求,TS-Reasoner提供了一個自定義模塊生成功能。該功能基於LLMs解析用戶輸入的自然語言要求,將其轉化為可執行的代碼模塊。這些自定義模塊能夠無縫整合到推理流程中,使得系統能夠根據不同領域的外部知識(如物理定律或領域規則)進行調整,滿足多樣化的任務需求。
4. 多領域數據集與綜合評估
為了驗證TS-Reasoner的有效性,本文在金融和能源領域構建了多個新數據集,並設置了一系列複雜的推理任務。這些任務涉及金融決策、時間序列預測、因果關係挖掘等。實驗結果表明,TS-Reasoner在多個評估指標上都優於現有的先進方法,尤其在多步推理任務中展現了顯著的優勢。
模型架構與實現

圖1:TS-Reasoner的總體架構。大型語言模型(LLM)作為任務分解器,通過學習上下文中的示例來將任務實例分解為程序。然後,程序執行器將調用我們工具箱中的模塊,按給定順序運行相關程序以獲得最終結果
TS-Reasoner的模型架構設計圍繞程序化多步推理展開,其核心理念是通過將複雜的時間序列任務分解為多個子任務,並逐步調用相應的模型和程序模塊來執行每一步的推理任務。架構整體由大型語言模型(LLM)進行任務分解,結合專門設計的時間序列模型模塊和數值方法模塊,確保複雜推理任務能夠被高效處理。
TS-Reasoner的核心架構由三個主要模塊組成:時間序列模型模塊、數值方法模塊和自定義模塊生成器。
1. 時間序列模型模塊:此模塊主要負責時間序列數據的基本處理和分析任務,如預測、趨勢分析、異常檢測等。這些操作基於預先訓練的時間序列模型來完成,能夠保證較高的預測精度。每個任務都會調用適當的模型模塊以執行特定的推理步驟,例如使用預測模型處理未來時間點的預測,或者調用異常檢測模型識別數據中的異常點。
2. 數值方法模塊:該模塊負責對數據進行定量操作,如波動性計算、趨勢檢測和統計分析。通過這一模塊,模型能夠執行定量的時間序列分析任務,使得時間序列動態變化能夠被充分理解和表達。此模塊對複雜的數值推理任務至關重要,尤其是在多步驟推理中,它能將時間序列數據轉化為具體的數值輸出,供下一個推理步驟使用。
3. 自定義模塊生成器:在遇到用戶提供的特定約束或外部知識時,TS-Reasoner會調用自定義模塊生成器。該模塊基於LLM解析用戶的自然語言輸入,生成對應的代碼模塊,將這些個性化的約束和需求轉化為可以執行的程序。這一模塊賦予了模型較強的靈活性,確保模型可以適應多樣化的任務需求。
TS-Reasoner的實現依賴於任務分解和模塊化的任務執行。通過LLM的上下文學習能力,模型能夠將複雜的任務分解為若干獨立的程序步驟。每一步都會調用一個預定義的模塊來處理特定的推理任務。整個流程遵循「分解—執行—合成」的邏輯,確保推理任務能夠被逐步解決。
1. 任務分解:模型首先通過LLM對輸入的自然語言任務進行解析,生成相應的推理步驟。這些步驟以偽代碼的形式表示,包括預測、優化、波動檢測等操作。然後,模型調用預定義的模塊或生成自定義模塊來執行這些任務。
2. 模塊執行:在推理過程中,每一個推理步驟都會被轉化為實際的程序代碼,模型根據任務要求執行這些代碼。每個模塊處理完任務後,輸出會作為下一步的輸入,依次傳遞,直至最終任務完成。
3. 約束與自定義模塊的整合:對於帶有複雜約束的任務,TS-Reasoner能夠利用自定義模塊生成器,將用戶的約束條件轉化為代碼,並在推理過程中動態調用這些模塊。這一實現確保了模型可以根據外部知識或領域規則進行推理,如考慮金融市場的風險控制或能源系統的負載管理。
實驗驗證與結果分析
為了驗證TS-Reasoner的有效性,本文進行了大量的實驗,並將其與基於思維鏈推理的基線模型(如Chain-of-Thought (CoT) 和 CoT + code)進行了對比數析。

在金融決策任務上,TS-Reasoner展現了卓越的表現,尤其是在風險容忍度(Risk Tolerance)和預算分配(Budget Allocation)任務中(見表1)。

表1:TS-Reasoner在決策製定上相較於其他基線模型的成功率和性能。SR代表成功率;AAP代表絕對平均利潤。RAP是相對平均利潤。在利潤百分比和預算分配任務中,我們的目標是提高利潤。因此,預期RAP為正值。在風險容忍度任務中,模型需要首先確保風險並最小化利潤的減少。因此,預期RAP為負值,但絕對值較低。粗體表示最佳結果
實驗結果表明,TS-Reasoner在嚴格成功率(Success Rate)和相對平均利潤(RAP)上顯著優於其他模型。
例如,在風險容忍度任務中,TS-Reasoner達到了96%的成功率,並且在控制風險的同時,表現出較低的相對利潤損失,而CoT和CoT + code模型的表現遠遜於TS-Reasoner,完全無法有效應對風險控制場景。
在預算分配任務中,TS-Reasoner同樣表現出色,在保持預算限制的同時實現了正的相對利潤,進一步證明了該方法在應對複雜約束條件下的強大能力。
圖2:評估TS-Reasoner的框架。在我們的框架當中,任務生成器從指令-程序對中采樣指令與對應的測試程序。然後TS-Reasoner根據指令與數據給出回覆。最後,一個通用測試框架根據測試程序根據對應的測試程序評估結果
在組合問題問答(Compositional Question Answering)任務中,TS-Reasoner再次超越了其他基線模型(見表2)。隨著任務複雜性的增加,TS-Reasoner的優勢愈加明顯。在涉及能源負載預測的多步推理任務中,TS-Reasoner不僅實現了較高的成功率,還在預測誤差(MAPE)上大幅降低了計算誤差。在最大負載和最小負載約束下,TS-Reasoner的成功率分別達到了97.83%和97.87%,相比CoT和CoT + code模型的成功率大幅提高,展現了卓越的多步推理能力。

表2:在組合問題回答(compositional QA)上,我們模型相對於其他基線模型的整體成功率和性能。SR代表成功率;MAPE代表平均絕對百分比誤差。粗體表示最佳結果。
在因果關係挖掘(Causal Relationship Recognition)任務中,TS-Reasoner也展現了較強的推理能力(見圖3)。儘管該任務難度較大,各模型的表現均不盡如人意,但TS-Reasoner在所有測試指標上仍然略勝一籌。在因果關係分類準確率(CRA)和因果圖準確率(CGA)上,TS-Reasoner分別實現了相對較高的成功率,進一步證明了其在複雜因果推理任務中的潛力。
此外,本文對錯誤類型進行了詳細分析,揭示了TS-Reasoner在應對時間序列任務中的優勢(見圖4)。通過引入程序輔助的推理機制,TS-Reasoner大幅降低了數值計算中的錯誤率,而CoT和CoT + code模型在執行代碼時常常會引發執行錯誤,這表明TS-Reasoner的模塊化設計提高了任務執行的穩健性和可靠性。
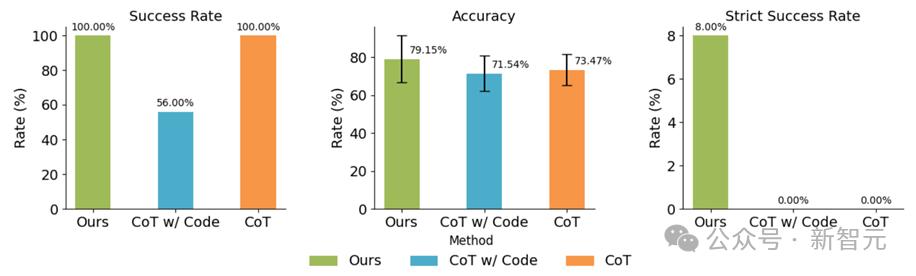 圖4:在因果關係識別上,TS-Reasoner相對於其他基線模型的整體成功率和性能
圖4:在因果關係識別上,TS-Reasoner相對於其他基線模型的整體成功率和性能 圖5:在最小負載下能源功率問題回答中不同方法的錯誤分佈
圖5:在最小負載下能源功率問題回答中不同方法的錯誤分佈在這些實驗中,TS-Reasoner模型在多個任務上都取得了突出的結果,表現出極高的泛化能力和適應性。
1. 時序預測任務:在股票價格預測和波動性預測任務中,TS-Reasoner實現了較高的成功率。例如,在股票未來價格預測任務中,TS-Reasoner實現了100%的成功率,並且在誤差評估指標(如MAPE)上顯著優於基線模型,證明了其在處理時間序列預測任務上的卓越性能。
2. 金融決策任務:在金融投資決策任務中,TS-Reasoner展現了強大的表現,尤其是在風險容忍度和預算分配任務中。相比於CoT和CoT + code模型,TS-Reasoner在嚴格的約束下依然能保持較高的相對平均利潤(RAP)和成功率(SR)。例如,在風險容忍度任務中,TS-Reasoner實現了96%的成功率,並有效控制了風險,同時保持較低的利潤損失,展現了其在複雜決策任務中的穩健性。
3. 組合問題問答任務:對於能源預測任務,TS-Reasoner在滿足複雜數據約束(如最大負載、最小負載和負載變動率限制)時表現優異。相比於CoT和CoT + code模型,TS-Reasoner在滿足這些外部約束的情況下,仍然保持了較低的誤差和較高的成功率,顯示了其強大的定製模塊生成和外部知識整合能力。
4. 因果關係挖掘任務:在多變量時間序列的因果關係挖掘任務中,TS-Reasoner同樣展現了出色的表現。儘管該任務難度較大,但TS-Reasoner在因果關係識別任務中表現優於其他模型,展現了其在複雜因果推理中的潛力。
總體而言,實驗結果表明,TS-Reasoner在處理複雜的多步推理任務時具有顯著的優勢,尤其是在金融決策、能源預測和因果推理等場景下,展現了強大的任務分解和約束滿足能力。這些結果為未來的多步推理和組合推理研究提供了有力的支持。
模型優勢與局限
TS-Reasoner模型的主要優勢在於其強大的多步推理能力和靈活的模塊化設計。與傳統的時間序列模型不同,TS-Reasoner不僅能夠處理預測、分類、異常檢測等單步任務,還可以通過程序輔助的推理框架,靈活地將複雜任務分解為多個步驟。
它能夠結合外部知識和用戶自定義的約束條件,使其在金融決策、能源負載預測等複雜場景中表現出卓越的適應性和靈活性。此外,TS-Reasoner在面對不確定性和複雜因果關係挖掘時,通過自定義模塊生成的機制,可以有效處理外部信息,提升推理的精確度和穩定性。
實驗結果表明,TS-Reasoner在處理決策、組合問題問答和因果關係挖掘等任務時,成功率和誤差評估指標顯著優於現有的最先進模型。
同時,TS-Reasoner能夠在複雜約束條件下保持較低的計算誤差,顯示出其在應對多維度、多約束任務中的強大魯棒性。
然而,TS-Reasoner也存在一定的局限性。
首先,儘管模型能夠有效處理多步推理任務,但在面對超長推理鏈時,任務分解的精度和模塊執行的效率仍有提升空間。隨著任務複雜度的增加,模塊化設計可能導致子任務之間的依賴關係增加,從而影響整體推理速度。
其次,TS-Reasoner雖然在合成時間序列推理任務上表現良好,但在極端數據稀缺或噪聲數據較多的環境下,其模型魯棒性仍需進一步驗證。
最後,雖然TS-Reasoner能夠通過自定義模塊生成處理外部約束,但不同類型的外部知識(例如不同領域的領域知識)對模型性能的具體影響還需要更多的實證研究和驗證。
總的來說,TS-Reasoner在多步推理和複雜時間序列任務中展現了強大的能力,但在應對極端數據情況和推理鏈長度優化方面,仍有提升空間。
未來工作展望
未來的工作可以從以下幾個方向進一步提升TS-Reasoner的能力:
1. 推理鏈長度優化:未來的研究可以致力於提高TS-Reasoner在處理更長推理鏈上的能力,尤其是在面對多步推理和複雜問題分解的場景中。優化模型在分解複雜任務時的效率和準確性,將有助於解決更大規模的任務鏈,並提升任務執行的速度與精度。
2. 多領域知識融合:研究如何更有效地整合來自不同領域的外部知識,如醫學、氣候科學等,通過進一步開發自定義模塊生成機制,使得TS-Reasoner能夠在多領域、多任務中保持高效的推理表現。這將有助於提升模型在多模態推理和複雜場景下的應用潛力。
3. 魯棒性提升:未來工作還應關注如何提升TS-Reasoner在面對噪聲數據或稀缺數據時的魯棒性。在真實世界的應用場景中,時間序列數據往往存在較高的噪聲或不完整,研究如何使模型在這些極端條件下依然保持高精度推理,將是重要的發展方向。
4. 跨任務泛化能力:進一步探索TS-Reasoner在跨任務泛化能力上的提升,使其能夠在未見過的任務類型或數據上依然保持良好的推理能力。研究如何讓模型在面對不同任務時高效適應,將有助於其在多任務環境中的應用,如金融決策、能源管理等複雜領域。
5. 多模態數據集成:未來還可以研究如何將TS-Reasoner擴展至多模態數據領域,結合如圖像、文本等非時間序列數據,從而使其能夠在更廣泛的應用場景中得到應用。這將進一步提升TS-Reasoner在多任務、多數據源推理中的表現能力。
總之,未來的工作可以圍繞推理鏈優化、多領域知識融合、模型魯棒性以及多模態數據集成等方向進行探索,以進一步提升TS-Reasoner在複雜時間序列推理任務中的應用潛力和廣泛適應性。
結論
本文提出的TS-Reasoner模型通過結合大型語言模型(LLMs)與程序輔助的多步推理框架,為時間序列推理任務提供了一種新穎且有效的解決方案。
與傳統的時間序列模型不同,TS-Reasoner不僅能夠處理單一的預測和分類任務,還具備強大的多步推理能力,可以靈活地分解複雜任務,並結合外部知識與自定義約束來優化推理過程。模型的模塊化設計使其在金融決策、能源負載預測和因果關係挖掘等複雜場景中表現出色。
實驗結果表明,TS-Reasoner在多個時間序列任務中優於現有的最先進模型,特別是在多任務推理和複雜決策任務中展示了出色的成功率和預測精度。其在處理帶有外部約束的複雜時間序列數據時表現尤為優異,進一步驗證了其靈活性和魯棒性。
總的來說,TS-Reasoner為複雜時間序列推理任務提供了一種創新的解決方案,展示了其在廣泛應用場景中的潛力。未來的研究可以進一步提升模型在處理更長推理鏈、跨領域知識融合以及多模態數據集成方面的能力,使其在更多的實際應用中發揮作用
參考資料:
https://arxiv.org/pdf/2410.04047
本文來自微信公眾號「新智元」,編輯:LRST ,36氪經授權發佈。










