陶哲軒神預言,Transformer破解百年三體難題,憑數學直覺找到李雅普諾夫函數

【導讀】Transformer解決了三體問題?Meta研究者發現,132年前的數學難題——發現全局李雅普諾夫函數,可以被Transformer解決了。「我們不認為Transformer是在推理,它可能是出於對數學問題的深刻理解,產生了超級直覺。」AI可以搞基礎數學研究了,陶哲軒預言再成真。
三體問題,竟被Transformer解決了?
發現全局李雅普諾夫函數,已經困擾了數學家們132年。
作為分析系統隨時間穩定性的關鍵工具,李雅普諾夫函數有助於預測動態系統行為,比如著名的天體力學三體問題。
它是天體力學中的基本力學模型,指三個質量、初始位置和初始速度都是任意的可視為質點的天體,在相互之間萬有引力作用下的運動規律問題。
現在已知,三體問題不能精確求解,無法預測所有三體問題的數學情景。(「三體人」的困境,就是三體問題的一個極端案例。)
現在,Meta AI解決了這個問題。目前,論文已被NeurIPS 2024接收。

論文地址:https://arxiv.org/abs/2410.08304
今天,論文發佈十幾天后,AI社區再度被它刷屏。

就在前一陣,蘋果的一項研究引起廣泛熱議:LLM不具備推理能力,可能只是複雜的模式匹配器而已。
有趣的是,這篇論文在結尾呼應了這個問題,做了極其精彩的論述——
從邏輯和推理的角度來看,有人認為規劃和高層次的推理可能是自回歸Transformer架構的固有限制。然而,我們的研究結果表明,Transformer確實可以通過精心選擇訓練樣本,而非更改架構,來學會解決一個人類通過推理解決的複雜符號數學問題。我們並不認為Transformer是在進行推理,而是它可能通過一種「超級直覺」來解決問題,這種直覺源自對數學問題的深刻理解。
雖然這個系統化的方法仍是一個黑箱,無法闡明Transformer的「思維過程」,但解決方案明確,且數學正確性可以得到驗證。
Meta研究者表示:生成式AI模型可以用於解決數學中的研究級問題,為數學家提供可能解的猜測。他們相信,這項研究是一個「AI解決數學開放問題」的藍圖。
無論如何,陶哲軒和今天的這項研究都已證明,無論LLM究竟會不會推理,它都已經徹底改變數學這類基礎科學的研究範式。
那些在歷史長河中的未解數學之謎,破解答案的一天或許已經離我們無比接近。
Transformer解決132年前數學難題
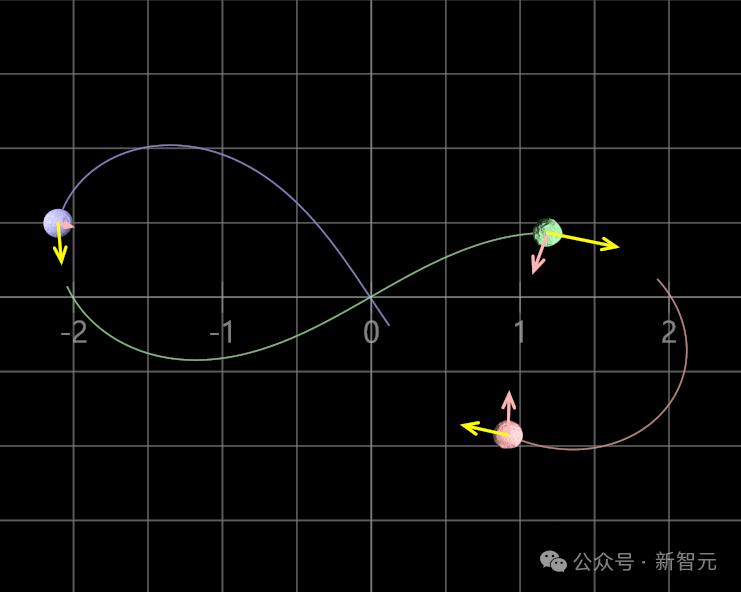
全局李亞普諾夫函數,控制著動力系統的穩定性。它會衡量一個開始接近平衡的系統,是否會始終保持接近平衡(或偏離平衡)?
其中最著名的案例,就是「三體問題」了。

軌跡可能很複雜,但只要從紅球開始,它們最終都會留在藍球的位置
1892年,李亞普諾夫證明,如果可以找到一個函數V,在平衡時具有嚴格的最小值,在無窮大時具有無限大,並且梯度始終指向遠離系統梯度的方向,那麼全局穩定性就能得到保證。
遺憾的是,他未能提供尋找函數V的方法。
好在,一百多年後,大模型出現了。
以前,不存在尋找李亞普諾夫函數的通用方法,現在LLM是否能解決?
研究者們驚喜地發現,自己的模型發現了兩個穩定系統,以及相關的李雅普諾夫函數。

為此,Meta AI研究者引入一種後向生成技術來訓練模型。這項技術根據Lyapunov函數創建動力系統,而這些系統的分佈與我們實際想要解決的問題不同。
儘管模型必須在分佈外進行泛化,但使用逆向生成數據訓練的模型,在可以用數值工具求解的多項式系統測試集上仍能取得良好的性能。

通過向後向訓練集中添加少量(0.03%)簡單且可解決的「前向」示例,性能就得到極大提高。這種「啟動模型」大大優於最先進的方法。

在穩定性未知的一組隨機動力系統上,研究者測試了自己的模型,發現在10%到13%的情況下,都能找到新的新的李亞普諾夫函數。

在這項任務上,這些增強的模型在各種基準測試中大大超越了最先進的技術和人類表現。
它們的準確率超過80%,但碩士生級別的人類數學家在這項任務上的準確率不到10%。
最後,研究者測試了模型在隨機生成系統中發現未知李雅普諾夫函數的能力。
在多項式系統中(當前方法唯一能解決的系統),模型為10.1%的系統找到了李雅普諾夫函數,而最先進的技術僅為2.1%。
在非多項式系統中(當前沒有已知算法),最佳模型為12.7%的系統發現了新的李雅普諾夫函數。
系統穩定性與李雅普諾夫函數
發現控制動力系統全局穩定性的李雅普諾夫函數,是一個長期存在但易於形式化的數學開放問題。
這個函數代表著當時間趨於無窮時,其解相對於平衡點或軌道的有界性。
動力系統的穩定性是一個複雜的數學問題,吸引了許多代數學家的興趣,從18世紀的牛頓和拉格朗日,到20世紀研究三體問題的龐加萊。

評估穩定性的主要數學工具是由李雅普諾夫提出的,他在1892年證明,如果可以找到一個遞減的類似熵的函數——李雅普諾夫函數,那麼系統就是穩定的。

系統穩定性
 全局漸進穩定性
全局漸進穩定性 後來,李雅普諾夫函數的存在被證明是大系統穩定性的必要條件。

不幸的是,目前尚無已知方法可以在一般情況下推導出李雅普諾夫函數,已知的李雅普諾夫函數僅適用於少數系統。
事實上,130年後,系統推導全局李雅普諾夫函數的方法僅在少數特殊情況下已知,而在一般情況下的推導仍然是一個著名的開放問題。
為此,研究者提出了一種從隨機采樣的李雅普諾夫函數中生成訓練數據的新技術。
在這些數據集上訓練的大語言模型中的序列到序列Transformer,在保留測試集上實現了接近完美的準確率(99%),並在分佈外測試集上表現出很高的性能(73%)。
實驗設置
在這項工作中,研究者訓練了序列到序列的Transformer,來預測給定系統的李雅普諾夫函數(如果存在)。
他們將問題框定為翻譯任務:問題和解決方案被表示為符號token的序列,模型從生成的系統和李雅普諾夫函數對中進行訓練,以最小化預測序列與正確解決方案之間的交叉熵。
為此,研究者訓練了具有8層、10個注意力頭和嵌入維度為640的Transformer,批大小為16個樣本,使用Adam優化器,學習率為10^−4,初始線性預熱階段為10,000次優化步驟,並使用反平方根調度。
所有實驗在8個32GB內存的V100 GPU上運行,每個epoch處理240萬樣本,共進行3到4個epoch。每個GPU的訓練時間在12到15小時之間。
數據生成
研究者將模型在大型數據集上進行訓練和測試,這些數據集由穩定系統及其相關的李雅普諾夫函數對組成。
采樣此類穩定系統有兩個難點。
首先,大多數動力系統是不穩定的,並且沒有通用的方法可以決定一個系統是否穩定。
其次,一旦采樣到一個穩定系統,除了特定情況下,沒有通用的技術可以找到李雅普諾夫函數。
在本文中,研究者依賴於反向生成,通過采樣解決方案並生成相關問題來處理一般情況,以及正向生成,通過采樣系統並使用求解器計算其解決方案,來處理小度數的可處理多項式系統。
反向生成
反向生成方法,從解決方案中采樣問題,只有在模型能夠避免學習逆轉生成過程或「讀取」生成問題中的解決方案時才有用。
例如,當訓練模型解決求整數多項式根的難題時,人們可以輕鬆從其根(3、5、7)生成多項式:

然而,如果模型是從P(X)的因式分解形式進行訓練的,它將學會讀取問題的根,而非計算它們。
另一方面,簡化形式

也並未提供任何線索。
反向生成的第二個困難是,對解決方案而非問題進行采樣,會使訓練分佈產生偏差。
為此,研究者提出了一種從隨機李雅普諾夫函數V生成穩定系統S的過程。

經過以上六步,產生了一個穩定系統S:ẋ=f(x),其中V作為其Lyapunov函數。
正向生成
儘管在一般情況下穩定性問題尚未解決,但當多項式系統的李雅普諾夫函數存在並可以寫成多項式的平方和時,已有方法可以計算這些函數。
這些多項式複雜度的算法對於小型系統非常高效,但隨著系統規模的增長,其CPU和內存需求會急劇增加。
研究者利用這項算法,來生成前向數據集。

這種方法也有幾個局限性,限制了該方法可以解決的多項式系統的類別。
數據集
研究者生成了兩個用於訓練和評估目的的反向數據集和兩個正向數據集,以及一個較小的正向數據集用於評估目的。

結果
研究者在不同數據集上訓練的模型,在保留測試集上取得了接近完美的準確率,並且在分佈外測試集上表現非常出色,特別是在用少量正向示例增強訓練集時。
它們大大超越了當前最先進的技術,並且還能發現新系統的李雅普諾夫函數。以下是這些結果的詳細信息。
分佈內和分佈外的準確率
在本節中,研究者展示了在4個數據集上訓練的模型的性能。
所有模型在域內測試中都取得了高準確率,即在它們訓練所用數據集的留出測試集上進行測試時。
在正向數據集上,障礙函數預測的準確率超過90%,李雅普諾夫函數的準確率超過80%。
在反向數據集上,訓練於BPoly的數據集的模型幾乎達到了100%的準確率。
研究者注意到,束搜索,即允許對解進行多次猜測,顯著提高了性能(對於表現較差的模型,束大小為50時提升了7到10%)。
在所有後續實驗中,研究者都使用了50的束大小。

對生成數據訓練的模型的試金石,是其分佈外(OOD)泛化能力。
所有反向模型在測試正向生成的隨機多項式系統(具有平方和李雅普諾夫函數)時,都取得了高準確率(73%到75%)。
最佳性能由非多項式系統(BNonPoly)實現,這是最多樣化的訓練集。
反向模型在具有障礙函數的正向生成系統集(FBarr)上的較低準確率,可能是因為許多障礙函數不一定是李雅普諾夫函數。在這些測試集上,反向模型必須應對不同的分佈和略有不同的任務。
另一方面,正向模型在反向測試集上的表現較差。這可能是由於這些訓練集的規模較小。
總體而言,這些結果似乎證實了反向訓練的模型並未學習反轉其生成過程。如果是這樣,它們在正向測試集上的表現將接近於零。它們還顯示了良好的OOD準確率。
通過豐富訓練分佈來提高性能
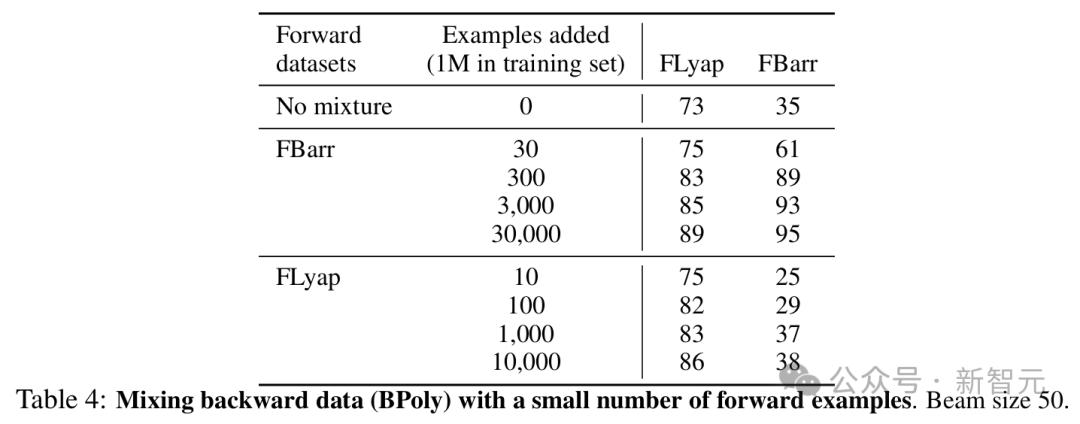
為了提高反向模型的OOD性能,研究者在其訓練集中加入了一小部分正向生成的示例。
值得注意的是,這帶來了顯著的性能提升。
將300個來自FBarr的示例添加到BPoly中後,FBarr的準確率從35%提高到89%(儘管訓練集中正向示例的比例僅為0.03%),並使FLyap的OOD準確率提高了10多個百分點。從FLyap添加示例帶來的改進較小。
這些結果表明,在反向生成數據上訓練的模型的OOD性能,可以通過在訓練集中加入少量我們知道如何解決的示例(幾十或幾百個)來大大提高。
在這裏,額外的示例解決了一個較弱但相關的問題:發現障礙函數。因為所需示例數量很少,因而這種技術特別具有成本效益。
與當前最先進的基線比較
為了給模型提供基線,研究者開發了findlyap,這是MATLAB的SOSTOOLS中的李雅普諾夫函數查找器的Python對應版本。
他們還引入了FSOSTOOLS,這是一個包含1500個整數係數多項式系統的測試集,具有SOSTOOLS可以求解的整數係數。
研究者還測試了基於AI的工具,例如Fossil 2、ANLC v2和LyzNet。
這些方法在測試集上取得了較低的準確率。這可能是因為這些工具旨在解決不同的問題:發現局部或半全局李雅普諾夫函數(並可能尋找控制函數),而研究者的目標是全局李雅普諾夫函數。
表5比較了findlyap和基於AI的工具以及研究者模型在所有可用測試集上的表現。
一個在BPoly上訓練並補充了500個來自FBarr的系統的模型(PolyMixture)在FSOSTOOLS上達到了84%的準確率,證實了混合模型的高OOD準確率。
在所有生成的測試集上,PolyMixture的準確率都超過了84%,而findlyap在反向生成的測試集上僅達到了15%。
這表明,在多項式系統上,從反向生成數據訓練的Transformer模型,相比於之前的最先進技術取得了非常強的結果。
平均而言,基於Transformer的模型也比SOS方法快得多。
當嘗試解決一個包含2到5個方程的隨機多項式系統時,findlyap平均需要935.2秒(超時為2400秒)。
對於研究者的模型,使用貪婪解碼進行一個系統的推理和驗證平均需要2.6秒,使用束大小為50時需要13.9秒。
探索未知領域:發現新的數學
這次研究的最終目標,就是發現新的李雅普諾夫函數。
為了測試模型發現新的李雅普諾夫函數的能力,研究者生成了三個隨機系統的數據集:
– 包含2或3個方程的多項式系統(Poly3)
– 包含2到5個方程的多項式系統(Poly5)
– 包含2或3個方程的非多項式系統(NonPoly)
對於每個數據集,生成100,000個隨機系統,並消除那些在x^∗ = 0處局部指數不穩定的系統,因為系統的雅可比矩陣具有實部嚴格為正的特徵值。
然後,將findlyap和基於AI的方法與兩個在多項式系統上訓練的模型進行比較:FBarr和PolyM(ixture)——BPoly與來自FBarr的300個示例的混合——以及一個在BPoly、BNonPoly和來自FBarr的300個示例的混合上訓練的模型(NonPolyM)。
在多項式數據集上,最佳模型(PolyM)為11.8%和10.1%的(3階和5階)系統發現了李雅普諾夫函數,比findlyap多出十倍。對於非多項式系統,李雅普諾夫函數在12.7%的示例中被找到。
這些結果表明,從生成的數據集和李雅普諾夫函數訓練的大語言模型確實能夠發現尚未知的李雅普諾夫函數,並且表現遠高於當前最先進的SOS求解器。

模型找到正確解決方案的百分比
專家迭代
接下來,研究者為多項式系統創建了一個經過驗證的模型預測樣本,FIntoTheWild,將其添加到原始訓練樣本中,並繼續訓練模型。
n1:添加20,600個樣本,分別來自BPoly(20,000)、FBarr(50)、FLyap(50)和FIntoTheWild(500)
n2:添加2,000個樣本,分別來自FLyap(1,000)和FIntoTheWild(1,000)
n3:添加50個來自FIntoTheWild的樣本
n4:添加1,000個來自FIntoTheWild的樣本
n5:添加2,000個來自FIntoTheWild的樣本
n6:添加5,000個來自FIntoTheWild的樣本
此外,研究者還從頭開始重新訓練一個模型(n7),使用BPoly(1M)、FBarr(500)、FLyap(500)和FIntoTheWild(2,000)的混合。

不同微調策略下,模型在前向基準和「探索未知領域」中的表現
可以看到,向100萬訓練集添加1,000個經過驗證的預測可將「探索未知領域」測試集的性能提高約15%,同時不會影響其他測試集(n4)。
而添加更多樣本似乎是有害的,因為它降低了其他基準的性能(n5和n6)。
此外,使用來自其他分佈的混合數據進行微調效率不高(n1和n2),而少量貢獻已經有助於取得一些改進(n3)。
最後,從頭開始使用FIntoTheWild的數據預訓練模型效率不高(n7)。
Transformer不會推理,但有「超級直覺」
這項研究已經證明,模型可以通過生成的數據集進行訓練,以解決發現穩定動力系統的李雅普諾夫函數。
對於隨機多項式系統,研究者的最佳模型可以在五倍於現有最先進方法的情況下,發現李雅普諾夫函數。
它們還可以發現非多項式系統的李雅普諾夫函數(目前尚無已知算法),並且能夠重新發現由Ahmadi等人發現的多項式系統的非多項式李雅普諾夫函數。
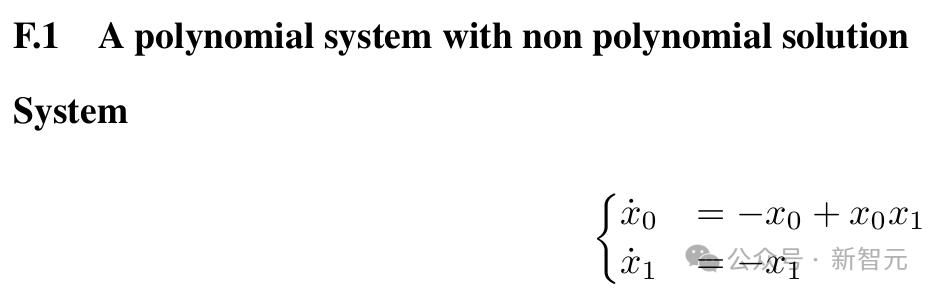


研究者也承認,工作仍有一些局限性。
由於沒有已知的方法來判斷隨機系統是否穩定,他們缺乏非多項式系統的良好基準。
此外,本文研究的所有系統都相對較小,多項式系統最多為5個方程,非多項式最多為3個方程。
他們相信,擴展到更大的模型應該有助於處理更大、更複雜的系統。
最後,這項工作可以擴展到考慮非多項式系統的定義域。
總之,這項工作在兩個方向上具有更廣泛的影響:Transformer的推理能力,以及AI在科學發現中的潛在作用。
參考資料:
https://arxiv.org/abs/2410.08304
本文來自微信公眾號「新智元」,編輯:Aeneas 好睏,36氪經授權發佈。










