讓機器人擁有人一樣「潛意識」,英偉達1.5M小模型就能實現通用控制了
機器之心報導
編輯:Panda、佳琪
當機器人也有潛意識。
大模型固然性能強大,但限制也頗多。如果想在端側塞進 405B 這種級別的大模型,那真是小廟供不起大菩薩。近段時間,小模型正在逐漸贏得人們更多關注。這一趨勢不僅出現在語言模型領域,也出現在了機器人領域。
昨天晚上,朱玉可和 Jim Fan 團隊(英偉達 GEAR 團隊)新鮮發佈了他們的最新研究成果 HOVER。這是一個僅有 1.5M 參數的神經網絡,但它足以控制人形機器人執行多種機體運動。
先來看看效果,將 HOVER 在不同模式下控制的機器人放到一起組成陣列,其中每一台機器人都有自己的控制模式。還挺壯觀的!這也佐證了 HOVER 的通用性。你能看出它們的不同之處嗎?

無論是 H2O 模式、OmniH2O Mode 模式、還是 ExBody 模式 、HumanPlus 模式,左手和右手的慢動作都直接被 HOVER 大一統了。

實際上,HOVER 就是一個通用型的人形機器人控製器。

HOVER 一作 Tairan He(何泰然)的推文,他是 CMU 機器人研究所的二年級博士生,還是個有 38 萬多粉絲的 B 站 up 主(WhynotTV)
據介紹,HOVER 的設計靈感來自人類的潛意識。人類在行走、保持平衡和調整四肢位置時都需要大量潛意識的計算,HOVER 將這種「潛意識」能力融合進了機器人。這個單一模型可以學習協調人形機器人的電機,從而實現運動和操控。

Jim Fan 的推文

-
論文標題:HOVER: Versatile Neural Whole-Body Controller for Humanoid Robots
-
論文地址:https://arxiv.org/pdf/2410.21229
-
項目地址:https://hover-versatile-humanoid.github.io/
HOVER 的訓練使用了 NVIDIA Isaac,這是一個由 GPU 驅動的模擬套件,可將物理加速到實時的 1 萬倍。按 Jim Fan 的比喻就是說,只需在一張 GPU 卡上運算大概 50 分鐘,機器人就像是在虛擬「道場」中經歷了一整年的密集訓練。
然後,無需微調,就可以將這個神經網絡以零樣本方式遷移到真實世界。
HOVER 可以接收多種高級運動指令,即所謂的「控制模式(control mode)」,比如:
-
頭部和手部姿勢,可通過 Apple Vision Pro 等增強現實設備捕捉;
-
全身姿勢,可通過 MoCap 或 RGB 相機;
-
全身關節角度:外骨骼;
-
根速度命令:操縱杆。

這項研究的貢獻包括:
-
一個統一的界面,可讓控制者使用任何方便的輸入設備來控制機器人;
-
一種更簡單的全身遠程操作數據收集方法;
-
一個上遊的視覺 – 語言 – 動作模型,可用於提供運動指令,之後 HOVER 會將其轉換為高頻的低級運動信號。
HOVER 是如何煉成的?
用於人形機器人的基於目標的強化學習
該團隊將所研究的問題表述成了一個基於目標的強化學習任務,其中策略 π 的訓練目標是跟蹤實時的人類運動。其狀態 s_t 包含智能體的本體感受 s^p 和目標狀態 s^g。其中目標狀態 s^g 會為目標運動提供一個統一的表徵。基於此,可將策略優化的獎勵定義成
-
動作

表示目標關節位置,這些位置會被輸入到PD控製器中以驅動機器人,他們使用了近端策略優化 (PPO) 算法來最大化累積折扣獎勵
該設置被表述為一個命令跟蹤任務,其中人形機器人會學習在每個時間步驟遵從目標命令。
用戶人形機器人控制的命令空間設計
對於腿部運動,根速度或位置跟蹤是常用的命令空間。然而,僅僅關注根跟蹤會限制人形機器人的全部能力,尤其是對於涉及全身運動的任務。
該團隊研究了之前的工作,發現它們提出了一些各不一樣的控制模式,並且每種模式通常都是針對某些特定的任務,因此缺乏通用人形機器人控制所需的靈活性。
而該團隊的目標是設計一個全面的控制框架,以適應多種多樣的場景和各種不同的人形機器人任務。為此,在構建命令空間時,必須滿足以下關鍵標準:
-
通用性:命令空間應包含大多數現有配置,允許通用控製器替換針對特定任務的控製器,同時還不會犧牲性能或多功能性。並且該空間應具有足夠的表現力,以便與現實世界的控制設備交互,包括操縱杆、鍵盤、動作捕捉系統、外骨骼和虛擬現實 (VR) 頭設,如圖 1 所示。
-
原子性:命令空間應由獨立的維度組成,從而能夠任意組合控制選項以支持各種模式。

基於這些標準,該團隊定義了一個用於人形機器人全身控制的統一命令空間。該空間由兩個主要控制區域組成 —— 上身和下身控制 —— 并包含三種不同的控制模式:
-
運動位置跟蹤:機器人上關鍵剛體點的目標 3D 位置;
-
局部關節角度跟蹤:每個機器人電機的目標關節角度;
-
根跟蹤:目標根速度、高度和方向,由滾動、俯仰和偏航角指定。
在如圖 1 所示的框架中,該團隊引入了一個 one-hot 掩碼向量來指定激活命令空間的哪些組件,以便後面跟蹤。
如表 1 所示,可以將其它基於學習的人形全身控制的最新研究看作是新提出的統一命令空間的子集,其中每項研究都代表特定的配置。

-
運動重定向
近期有研究表明,如果學習的運動數據集很大,學習到的人形機器人全身運動控制策略就會更加穩健。
為了獲得大型數據集,可將人類運動數據集重定向成人形機器人運動數據集,這個過程分為三步:
1. 使用正向運動學(forward kinematics)計算人形機器人的關鍵點位置,將其關節配置映射成工作空間坐標。
2. 擬合 SMPL 模型以匹配人形機器人的運動學,做法是優化 SMPL 參數以與正向運動學計算得到的關鍵點對齊。
3. 使用梯度下降來匹配已經擬合的 SMPL 模型和人形機器人之間的對應關鍵點,重定向 AMASS 數據集。
-
狀態空間設計
他們訓練了一個 oracle 運動模擬器

其中 p_t 是人形機器人剛體位置 、θ_t 是方向、p_t 是線速度、 ω_t 是角速度、a_{t−1} 是前一個動作。本體感覺定義為

目標狀態的定義是

其中包含參考姿態以及人形機器人所有剛體的參考狀態與當前狀態之間的一幀差異。他們使用的策略網絡結構為層尺寸為 [512, 256, 128] 的三層 MLP。
-
獎勵設計和域隨機化
這裏,獎勵 r_t 是三個份量之和:1) 懲罰、2) 正則化和 3) 任務獎勵,詳見表 2。域隨機化是將模擬環境和人形機器人的物理參數隨機化,以實現模擬到現實成功遷移。

通過蒸餾實現多模式多功能控製器
-
本體感受
對於從 oracle 教師 π^oracle 中蒸餾得到的學生策略 π^student,本體感受定義為

其中q是關節位置,

是關節速度,ω^base 是基準角速度,g 是重力向量,a 是動作歷史。
他們將最新的 25 個步驟的這些項堆疊起來作為學生的本體感受輸入。

-
命令掩碼

模式掩碼 M_mode 會為上半身和下半身份別選擇特定的任務命令模式。例如,上半身可以跟蹤運動位置,而下半身則專注於關節角度和根部跟蹤,如圖 2 所示。在模式特定的掩碼之後,應用稀疏掩碼 M_sparsity。
例如,在某些情況下,上半身可能只跟蹤手的運動位置,而下半身只跟蹤軀幹的關節角度。模式和稀疏二元掩碼的每一比特都來自伯努利分佈 𝔅(0.5)。模式和稀疏掩碼在事件情節(episode)開始時是隨機的,並保持固定,直到該情節結束。
-
策略蒸餾
該團隊執行策略蒸餾的框架是 DAgger。對於每個事件情節,都先在模擬中 roll out 學生策略

,從而得到
的軌跡。
另外在每個時間步驟還會計算相應的 oracle 狀態

以獲得參考動作
然後通過最小化損失函數來更新學生策略 π^student。
實驗
研究團隊針對以下問題,在 IsaacGym 和 Unitree H1 機器人上開展了廣泛的實驗:
-
Q1: HOVER 這個通用策略能比那些只針對特定指令訓練的策略表現得更好嗎?
-
Q2: HOVER 能比其他訓練方法更有效地訓練多模態仿人機器人控製器嗎?
-
Q3: HOVER 能否在真實世界的硬件上實現多功能多模態控制?
與專家策略的對比
該團隊在不同控制模式下比較了 HOVER 和相應專家策略的表現。以 ExBody 模式為例,研究團隊加入了固定的掩碼,讓 HOVER 和整個數據集 Q 中的 ExBody 模式可比。

如表 III 和圖 3 所示,HOVER 展現出了優越的泛化能力。在每一種指令模式中,HOVER 在至少 7 個指標上超越了之前的專家控製器(表 III 中用粗體值突出顯示)。同時,這也意味著即使只關注單一控制模式,從專家策略中提取的策略也比通過強化學習訓練出的專家更強。

與通用訓練方法的對比
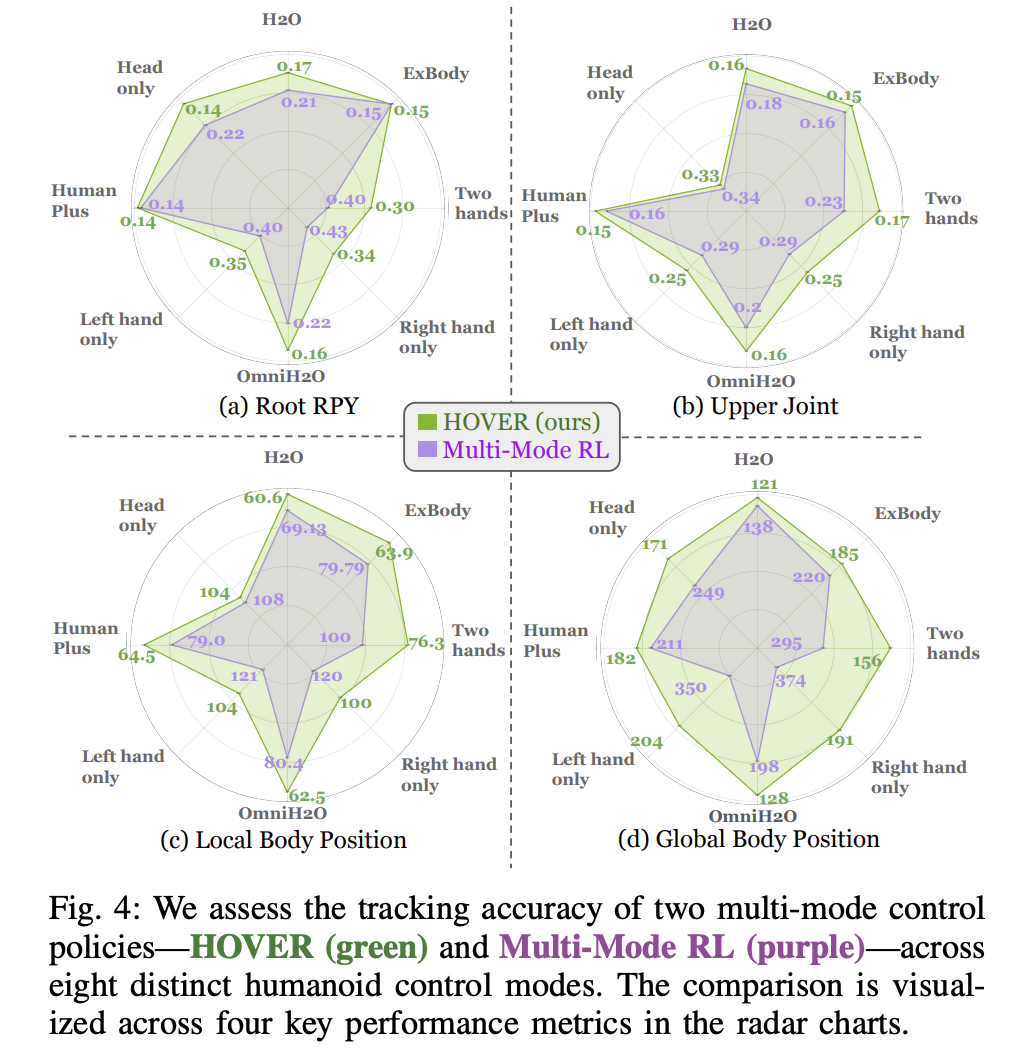
研究團隊在八種不同的模式下測量了 HOVER 在跟蹤局部和全身位置方面的表現。他們用最大誤差(Emax)減去當前誤差(E (.)),再除以最大誤差(Emax)和最小誤差(Emin)之間的差值來計算誤差。雷達網圖更大,代表模型的跟蹤性能更好。實驗結果顯示,HOVER 在所有 32 個指標和模式中的誤差都很低。
在真實世界中的測評
為了測試 HOVER 策略在真實世界中的表現,研究團隊設計了定量的跟蹤實驗和定性的多模態控制實驗。
-
站立時的動作評估
該團隊通過跟蹤 20 種不同的站立動作來評估 HOVER 的性能,表 V 中的定量指標顯示,HOVER 在 12 個指標中的 11 個上超越了專家策略。HOVER 成功跟蹤了關節俯仰運動與全身運動,特別是高度動態的跑步動作也能搞掂。

機器人的關節可以在 – 0.5 到 0.5 的俯仰角度之間變化

-
多模態評估
該團隊還模擬了真實的生活場景,測試了在突然切換命令時 HOVER 對運動的泛化能力。HOVER 成功地讓機器人從 ExBody 模式切換到 H2O 模式,同時在向前行走。

從 ExBody 切換到 H2O 模式
從 HumanPlus 模式切換到 OmniH2O 模式,機器人也能同時執行轉彎和向後行走。

從 HumanPlus 切換到 OmniH2O 模式
此外,他們還使用 Vision Pro 隨機掩蓋頭部和手部的位置,進行了遠程操作演示,可以看出,機器人的動作非常地絲滑流暢。
有時,它也會出錯,比如只追蹤了測試者的頭部位置,忽略了揮手的動作。

結果表明,HOVER 能夠平滑地在不同模式之間追蹤動作,展示了其在真實世界場景中的魯棒性。