大規模、動態「語音增強/分離」新基準!清華發佈移動音源仿真平台SonicSim,含950+小時訓練數據

新智元報導
編輯:LRST
【新智元導讀】清華大學推出的SonicSim平台和SonicSet數據集針對動態聲源的語音處理研究提供了強有力的工具和數據支持,有效降低了數據採集成本,實驗證明這些工具能有效提升模型在真實環境中的性能。
隨著語音技術的快速發展,現有的語音分離和增強方法在靜態環境下已經取得了顯著的進展。然而,在動態環境中,這些方法的性能仍然存在很大的不確定性。
目前,用於研究動態聲源的數據集極為稀少,主要原因是錄製成本高昂,難以大規模應用,極大地阻礙了動態環境下語音分離與增強技術的發展和應用。
為了應對這一挑戰,清華大學研究團隊開發了SonicSim仿真平台和SonicSet數據集:
SonicSim是一個高度可定製的數據生成工具,能夠模擬各種複雜的動態聲源場景;
SonicSet則是基於SonicSim生成的大規模動態聲源數據集,為語音分離和增強研究提供了豐富的訓練和測試數據,這一創新性的解決方案不僅大幅降低了數據採集成本,還為動態語音處理技術的發展提供了強有力的支持。

論文地址:https://arxiv.org/abs/2410.01481
項目主頁:https://cslikai.cn/SonicSim/
代碼地址:https://github.com/JusperLee/SonicSim
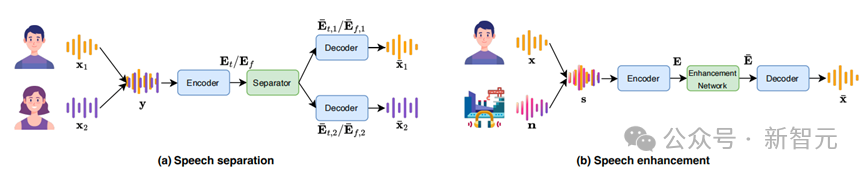
SonicSim仿真平台
SonicSim是一個基於Habitat-sim的可定製數據生成工具,專為語音任務設計。它利用Habitat-sim的高度真實的音頻渲染器和高性能3D模擬器,生成適用於各種聲學環境的高質量音頻數據。

SonicSim的主要功能包括:
3D場景導入
通過Habitat-sim,SonicSim可以導入各種由模擬或掃瞄生成的真實3D資產,如Matterport3D數據集。這使得生成複雜且真實的聲學環境變得更加高效和可擴展。
聲學環境模擬
SonicSim利用Habitat-sim模擬3D環境中的各種聲學特徵:
1. 使用室內聲學建模和雙向路徑追蹤算法準確模擬房間幾何形狀內的聲音反射;
2. 將3D場景的語義標籤映射到材料屬性,設置不同表面的聲學特徵;
3. 基於聲源路徑合成移動聲源數據;
馬克風類型
SonicSim支持多種音頻格式,如單聲道、雙耳和環繞聲。此外,還集成了常見的線性和圓形馬克風陣列,並允許用戶自定義馬克風陣列的形狀。
聲源和馬克風位置
SonicSim允許用戶自定義或隨機設置聲源和馬克風的位置。除靜態定位外,還支持基於指定起點和終點生成移動聲源和馬克風的運動軌跡。
SonicSet數據集

SonicSet是一個基於SonicSim構建的大規模動態聲源數據集,專為研究移動語音分離和增強任務而設計。
該數據集的主要特點包括:
1. 多樣性:SonicSet利用Matterport3D數據集中的90個建築級場景,涵蓋了廣泛的真實環境,如家庭、辦公室和教堂等。訓練集包含62個場景,驗證集19個場景,測試集9個場景。
2. 大規模:SonicSet整合了來自LibriSpeech數據集的360小時語音音頻,結合來自FSD50K的環境噪聲和FMA數據集的音樂噪聲,提供了豐富多樣的音頻素材。
3. 高質量:通過模擬不同材料的聲音反射和衍射,SonicSet生成的合成音頻的房間衝激響應更接近真實環境,從而產生更高質量的混響音頻。
4. 可定製性:SonicSet包含57596個語音移動軌跡,覆蓋了室內場景中大多數可能的位置。數據集提供約952小時的訓練數據,4小時的驗證數據和4小時的測試數據。

SonicSet的數據構建過程如下:
1. 從Matterport3D數據集中選擇3D場景並導入SonicSim初始化聲學環境。
2. 在場景中隨機選擇馬克風和聲源的放置位置。
3. 基於聲源的初始位置,在一定範圍內選擇聲源的終點位置,並使用SonicSim的軌跡功能生成移動路徑。
4. SonicSim計算路徑上不同位置對應的房間衝激響應,並與源音頻進行卷積。
5. 根據預先計算的索引和權重,從卷積輸出中提取對應每個部分起始和結束位置的音頻片段,並根據插值權重進行混合。
通過這一過程,SonicSet生成了時間上連貫的音頻信號,準確反映了聲源在空間環境中的移動。
實驗驗證
為了全面評估SonicSet數據集的有效性,研究團隊在兩種不同的背景噪聲場景(音樂和環境噪聲)下構建了Leaderboard,訓練並測試了11種語音分離方法和9種語音增強方法,並分析了不同方法的效率指標。
真實環境驗證
真實環境之間的聲學差距,研究團隊從SonicSet驗證集中隨機選擇了一些原始音頻,並在真實場景中進行錄製,構建了一個包含10個場景、總時長5小時的語音分離數據集。

此外,對於語音增強任務,研究團隊利用了RealMAN測試集,該測試集包含了來自真實環境的移動聲源錄音。

實驗結果表明,在SonicSet數據集上訓練的模型能夠很好地泛化到真實環境中,驗證了SonicSim在模擬真實聲學環境方面的有效性,同時也凸顯了SonicSet作為一個高質量合成數據集在語音研究中的潛力。
SonicSet語音分離基準分析
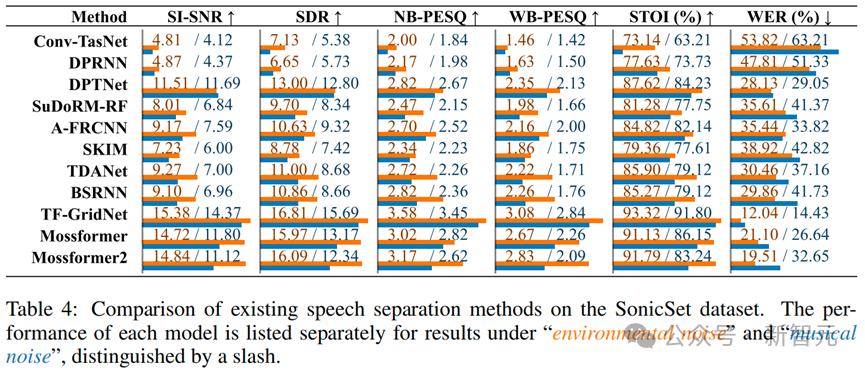
在嘈雜環境中,最新的模型相比之前的模型在各項指標上都有顯著提升。TF-GridNet在所有評估指標上表現最為突出,特別是在SI-SNR、SDR和WER上顯著優於其他模型。Mossformer系列模型也展示了強大的語音分離能力,但在WER上仍有提升空間。早期模型如Conv-TasNet和DPRNN在動態環境中的表現有限,更適合靜態或低噪聲環境下的應用。
SonicSet語音增強基準分析
在不同噪聲環境(嘈雜環境和音樂環境)中,各模型的表現存在顯著差異。在嘈雜環境中,Inter-SubNet表現最為優異,特別是在NB-PESQ、WB-PESQ和WER上顯著優於其他模型。在音樂環境中,FullSubNet在多數指標上表現出色,尤其是在WER上顯示了較強的魯棒性。

總結與展望
SonicSim和SonicSet的開發為動態環境下的語音分離和增強研究提供了強有力的工具和數據支持。
研究結果表明,在動態環境中提升語音處理模型的性能需要特別關注以下幾個方面:
1, 數據多樣性:SonicSet通過模擬不同場景中的動態聲源和噪聲源,為研究者提供了更真實、更豐富的訓練數據。未來可以通過引入更多的環境變量和多源數據,進一步擴展數據集的多樣性。
2. 模型適應性:實驗結果顯示,不同模型在動態環境中的表現存在顯著差異。未來的研究應著重提高模型在複雜動態環境下的魯棒性和適應性。
3. 真實環境遷移:雖然SonicSet在模擬真實環境方面表現出色,但進一步縮小合成數據與真實數據之間的差距仍然是一個重要的研究方向。
4. 新型應用場景:SonicSim的高度可定製性為探索新的應用場景提供了可能,如基於區域的語音增強和移動聲源說話人定位等。
SonicSim和SonicSet的發佈不僅為語音分離和增強研究提供了新的基準,也為未來的研究開闢了廣闊的空間,通過持續改進仿真工具和優化模型算法,相信未來能夠在複雜環境中部署更加高效、魯棒的語音處理系統。
此外,SonicSim的開源性質使得研究人員能夠使用更多的場景和數據來無限制地合成更多的移動聲源數據,這將有助於訓練更加魯棒的分離和增強模型。研究團隊也鼓勵社區貢獻新的場景和音頻數據,以進一步擴展SonicSet的規模和多樣性。
最後,SonicSim和SonicSet的成功開發也為其他相關領域的研究提供了啟發。例如,在多模態學習、聲學場景分類、聲源定位等領域,類似的仿真平台和大規模數據集可能會帶來突破性的進展。
參考資料:
https://arxiv.org/abs/2410.01481












