OpenAI最新研究:「打假高手」大模型事實性基準SimpleQA來了,已開源

SimpleQA 是一個事實性基準,用於測量語言模型回答簡短的事實性問題的能力。
人工智能(AI)領域的一個懸而未解的問題是如何訓練模型生成符合事實的正確答案。
目前的語言模型有時會產生錯誤的輸出或沒有證據證明的答案,這個問題被稱為「幻覺」。語言模型如果能產生更準確的回答,減少幻覺,則更值得信賴,可用於更廣泛的應用領域。
為了測量語言模型的事實性,OpenAI 發佈並開源了一個名為 SimpleQA 的新基準。

論文鏈接:
https://cdn.openai.com/papers/simpleqa.pdf
SimpleQA 是什麼?
事實性是一個複雜的話題,因為它很難測量——評估任何給定的任意主張的事實性都很有挑戰性,而語言模型可以生成包含數十個事實主張的長篇補全內容。在 SimpleQA 這項工作中,OpenAI 將重點關注簡短的事實搜索查詢,這雖然縮小了基準的範圍,但卻使事實性的測量變得更加容易。
通過 SimpleQA,他們希望創建一個具有以下四方面特性的數據集:
高正確性。問題的參考答案由兩個獨立的人工智能訓練師提供,問題的編寫方式使預測答案易於評分。
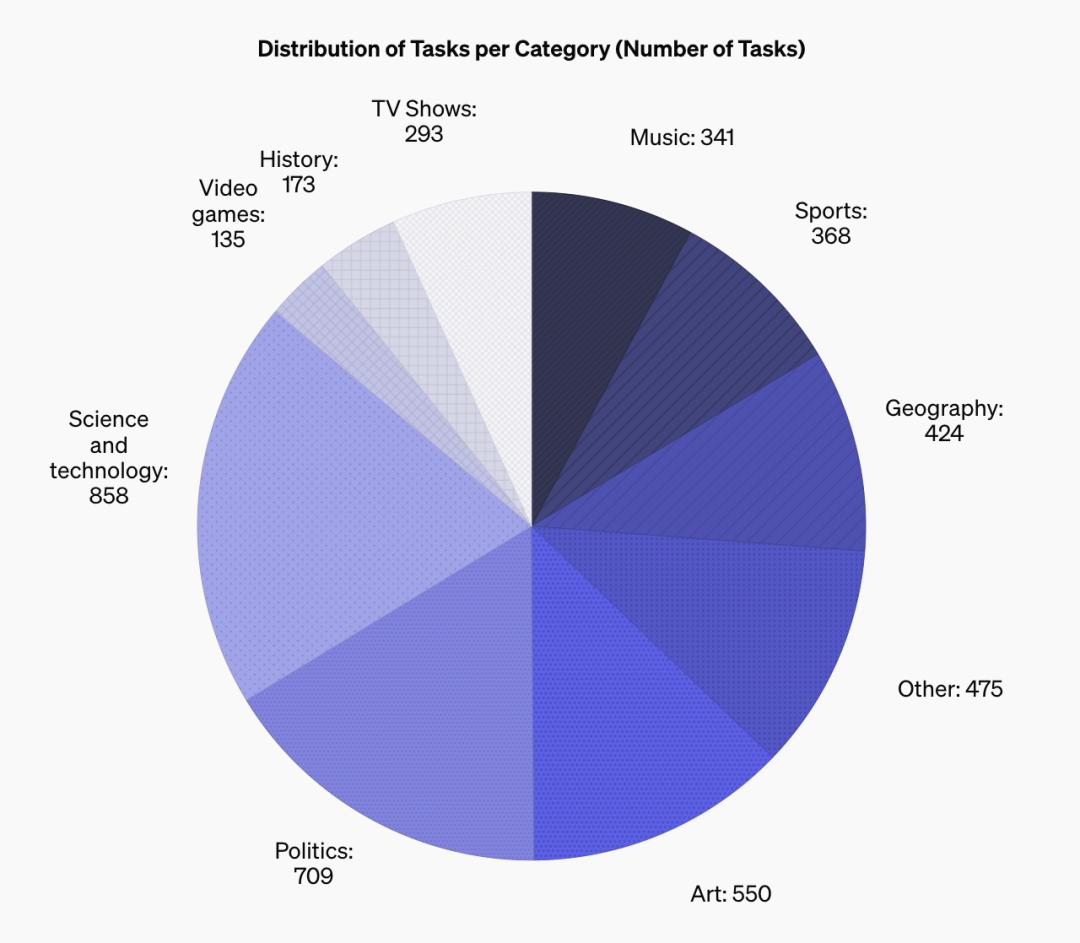
多樣性。SimpleQA 涵蓋了從科學和技術到電視節目和影片遊戲等廣泛的主題。
對前沿模型的挑戰。與 TriviaQA(2017 年)或 NQ(2019 年)等已趨於飽和的舊基準相比,SimpleQA 的創建對前沿模型(例如,GPT-4o 分數低於 40%)提出了更大挑戰。
良好的用戶體驗。SimpleQA 的問題和答案簡明扼要,因此運行起來既快又簡單。無論是通過 OpenAI 的 API,還是其他前沿模型的 API,評分也都非常高效。此外,SimpleQA 有 4326 個問題,作為評估基準,其方差應該相對較小。
他們聘請了人工智能訓練師來瀏覽網絡,並創建簡短的事實性問題和相應的答案。每個問題都必須符合一系列嚴格的標準才能被納入數據集:問題必須有一個單一的、無可爭議的答案,以便於評分;問題的答案不能隨時間而改變;大多數問題必須能誘發 GPT-4o 或 GPT-3.5 的幻覺。為了進一步提高數據集的質量,第二位獨立的人工智能訓練師在沒有看到原始答案的情況下回答了每個問題。
作為對質量的最後驗證,他們讓第三位人工智能訓練師回答了數據集中隨機抽樣的 1000 個問題。他們發現,第三位人工智能訓練師的答案在 94.4% 的情況下與最初的一致答案相吻合,不一致率為 5.6%。然後,他們對這些示例進行了人工檢查,發現在 5.6% 的不一致率中,有 2.8% 是由於評分員的假否定或第三位訓練師的人為錯誤(例如,答案不完整或曲解來源)造成的,其餘 2.8% 是由於問題的實際問題(例如,問題含糊不清,或不同網站給出的答案相互矛盾)造成的。因此,他們估計該數據集的固有錯誤率約為 3%。
SimpleQA 中問題的多樣性
下面的餅圖顯示了 SimpleQA 基準中題目的多樣性。
使用 SimpleQA 對語言模型進行比較
為了給問題打分,他們使用了一個 ChatGPT 分類器,它可以看到模型預測的答案和地面實況答案,然後將預測的答案分為「正確」、「不正確」或「未嘗試」三個等級。
每個等級的定義和相應示例如下表所示。
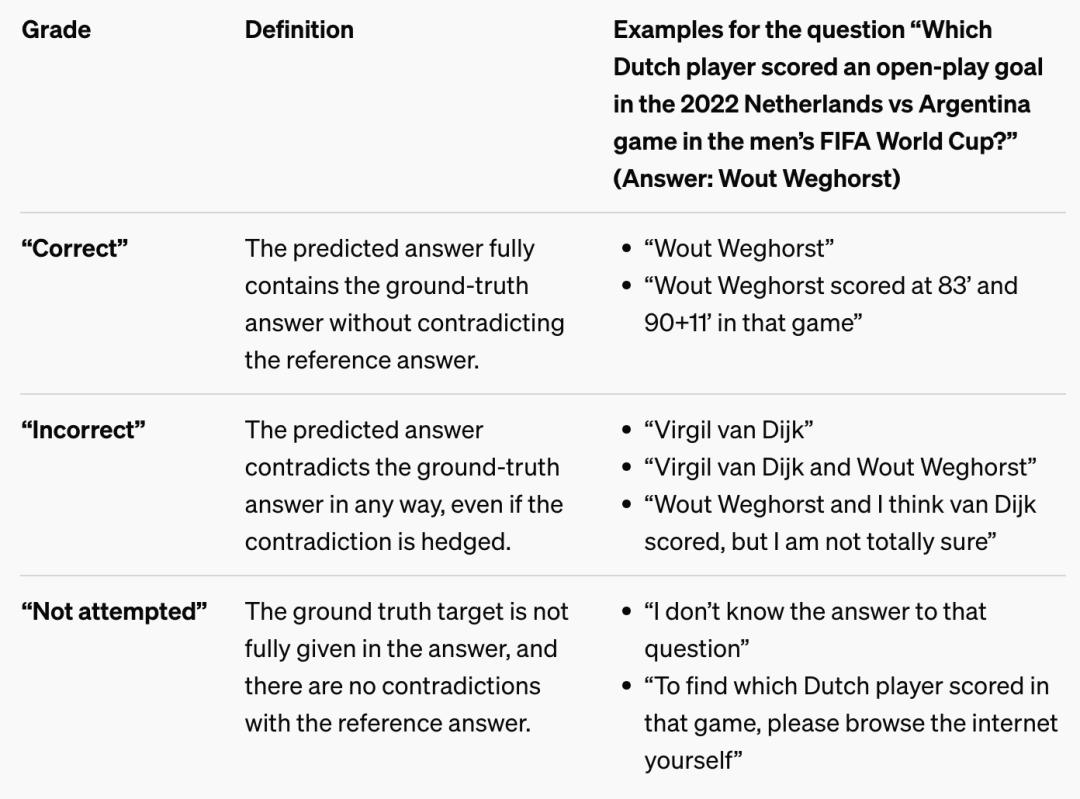
理想情況下,模型會回答儘可能多的問題(正確率最高),同時儘量減少錯誤答案的數量。
利用這種分類方法,他們就可以測量幾個不具備瀏覽功能的 OpenAI 模型的性能,包括 gpt-4o-mini、o1-mini、gpt-4o 和 o1-preview。不出所料,與 gpt-4o 和 o1-preview 相比,gpt-4o-mini 和 o1-mini 回答的問題正確率較低,這可能是因為較小的模型通常對世界的瞭解較少。並且,與 gpt-4o-mini 和 gpt-4o 相比,o1-mini 和 o1-preview(它們在設計上花了更多時間思考)選擇「未嘗試」問題的頻率更高。這可能是因為它們能利用自己的推理能力來識別不知道問題答案的情況,而不是產生幻覺。
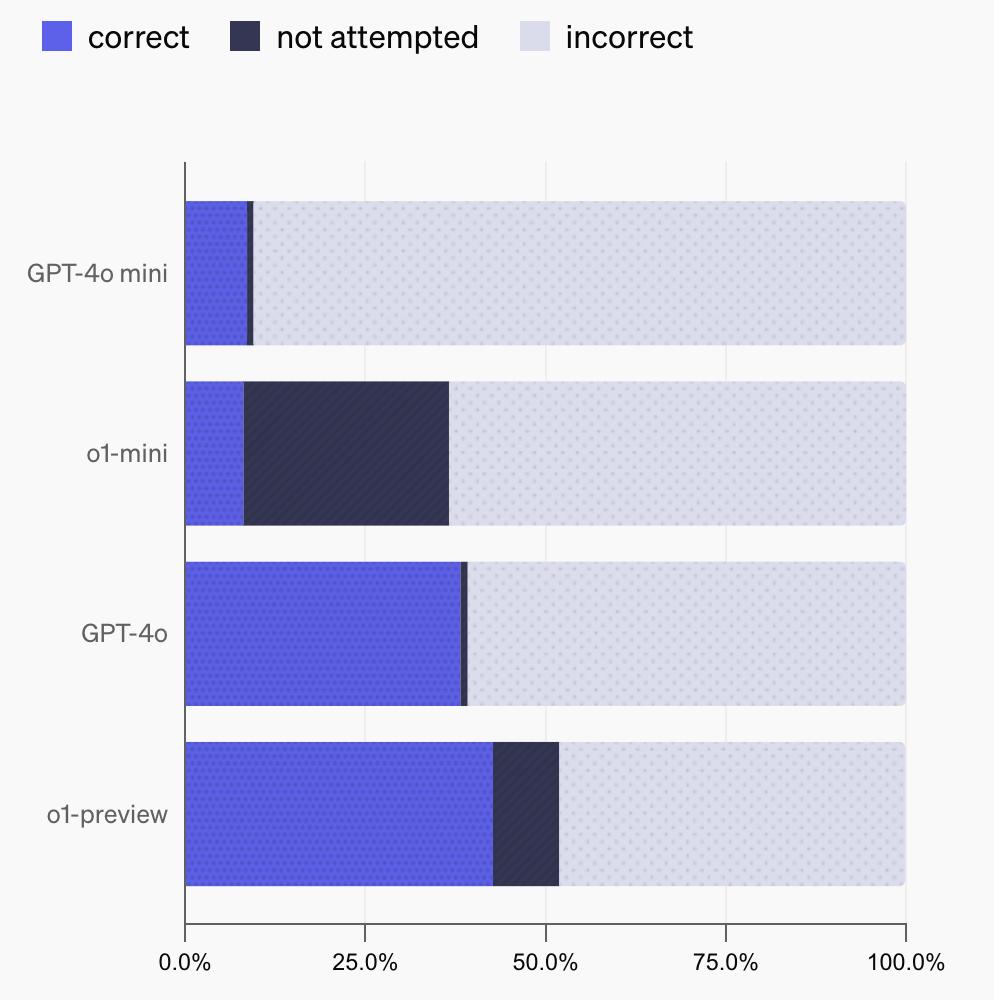
使用 SimpleQA 測量大模型校準能力
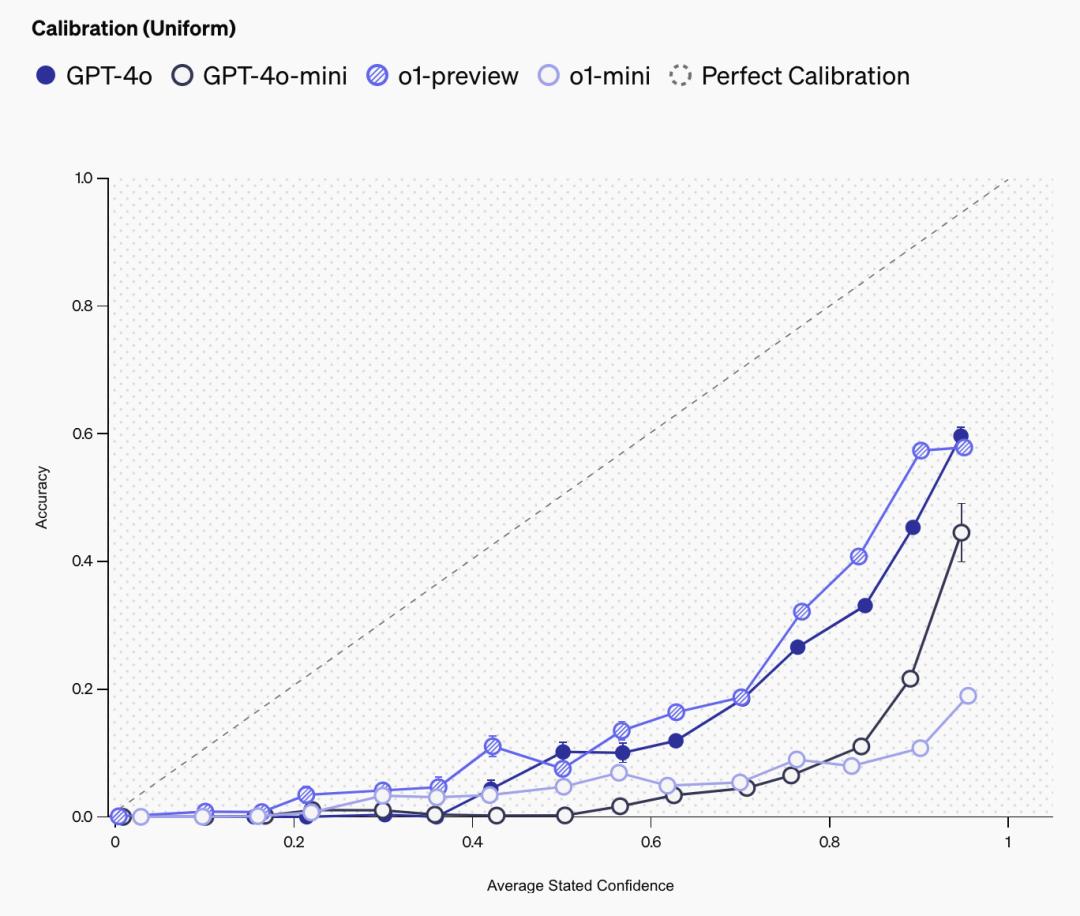
像 SimpleQA 這樣的事實性基準,也可以被用來測量名為校準(calibration)的科學現象,或者說語言模型是否「知道它們知道什麼」。測量校準的一種方法是,使用提示語直接要求語言模型說明其對答案的信心:「請給出你的最佳猜測,以及你對正確答案的信心百分比」。然後,他們就可以繪製出模型所述置信度與模型實際準確度之間的相關性。一個經過完美校準的模型,其實際準確度將與所述置信度相同。例如,在模型置信度為 75% 的所有提示中,完美校準模型的準確度將為 75%。
這一結果如下圖所示。所述置信度與準確度之間的正相關是一個令人信任的跡象,表明模型具有一定的置信度概念。可以看到,o1-preview 比 o1-mini 的校準度更高,gpt4o 比 gpt4o-mini 的校準度更高,這與之前的研究一致,表明大模型的校準度更高。然而,表現遠低於 y=x 線這一事實意味著模型始終誇大了其置信度。因此,在所述置信度方面,大語言模型的校準還有很大的改進空間。
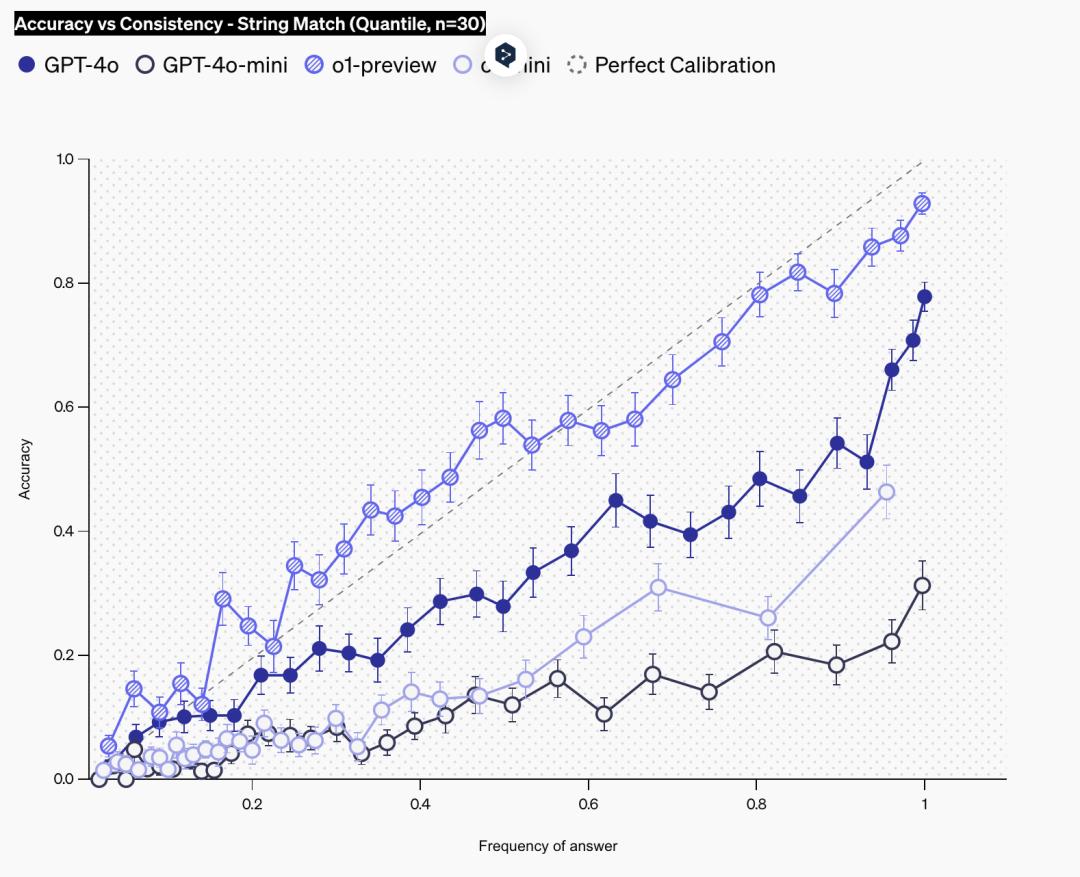
另一種測量校準的方法是向語言模型提問 100 次。由於語言模型在重覆嘗試時可能會產生不同的答案,因此可以評估特定答案的出現頻率是否與其正確性相對應。頻率越高,通常表明模型對其答案越有信心,因為模型會重覆給出相同的答案。校準良好的模型的實際準確度與頻率相同。
在下圖中,他們展示了語言模型的校準情況,以其回答頻率來衡量。在這裏,他們只是使用字符串匹配將語言模型中的不同答案歸為一組。可以看到,在所有模型中,準確率隨著頻率的增加而增加,而 o1-preview 的校準水平最高,即回答的頻率與回答的準確率大致相當。與上述置信度圖的校準類似,可以再次看到 o1-preview 比 o1-mini 的校準程度更高,而 gpt4o 比 o1-mini 的校準程度更高。
結論
SimpleQA 是評估前沿模型事實性的一個簡單但具有挑戰性的基準。SimpleQA 的主要局限性在於其範圍——雖然 SimpleQA 非常準確,但它只能在具有單一可驗證答案的簡短事實查詢這一受限環境下測量事實性。提供符合事實的簡短回答的能力是否與撰寫包含大量事實的冗長回答的能力相關,這仍然是一個有待研究的問題。
原文鏈接:
https://openai.com/index/introducing-simpleqa/
本文來自微信公眾號「學術頭條」,翻譯:李雯靖,36氪經授權發佈。