打破RLHF瓶頸,克服獎勵欺騙!Meta發佈全新後訓練方式CGPO,編程水平直升5%

新智元報導
編輯:LRST
【新智元導讀】CGPO框架通過混合評審機制和約束優化器,有效解決了RLHF在多任務學習中的獎勵欺騙和多目標優化問題,顯著提升了語言模型在多任務環境中的表現。CGPO的設計為未來多任務學習提供了新的優化路徑,有望進一步提升大型語言模型的效能和穩定性。
近年來,隨著大規模語言模型(LLMs)的發展,特別是通用大模型的應用場景愈發廣泛,RLHF逐漸成為調整和優化語言模型輸出的主流方法。
儘管RLHF在處理複雜任務時表現出色,但其在多任務學習(MTL)中的表現卻受限於「獎勵欺騙」以及多目標優化中的矛盾問題。
傳統的RLHF方法依賴於線性組合的獎勵模型,不僅需要人工調參,且容易導致模型被某一任務的獎勵優化「誤導」。
最近Meta GenAI和FAIR團隊提出了一個全新的後訓練範式——Constrained Generative Policy Optimization (CGPO),通過引入「混合評審機制」(Mixture of Judges, MoJ)與高效的約束優化器,全面提升了RLHF在多任務環境中的表現。
 論文鏈接:https://arxiv.org/pdf/2409.20370
論文鏈接:https://arxiv.org/pdf/2409.20370實驗結果表明,CGPO能夠根據任務的不同需求靈活調整優化策略,並通過多任務梯度累積來實現模型的更新,使其在處理不同任務時均能達到最佳表現。
CGPO框架:打破RLHF瓶頸的全新設計
CGPO的核心在於它突破了傳統RLHF對多任務學習的局限性,尤其是在獎勵優化與任務目標衝突之間找到了新的平衡。通過混合評審機制,CGPO能夠有效識別並消除「獎勵欺騙」行為,即模型在某些任務中過度優化特定的獎勵指標,進而導致其他任務的表現下降。
此外,CGPO的約束優化器具備自動化調節能力,使其可以在不依賴人工經驗的情況下,找到不同任務間的最優平衡點。
CGPO採用了基於規則和LLM的雙重評審機制。在規則評審中,預先定義的規則能夠有效檢測出模型生成結果是否符合任務需求,如解決數學問題的正確性、代碼生成的準確性等;而LLM評審則利用語言模型的內在判斷能力,檢測生成內容的事實性、響應的安全性等,這對於處理複雜對話和開放性問題尤為重要。

CGPO的核心貢獻
CGPO的設計從根本上解決了RLHF在多任務優化中的兩大難題:
1. 獎勵欺騙的防範
CGPO通過混合評審機制,在模型生成的過程中持續監控獎勵欺騙行為,保證模型不會過度優化某一任務的獎勵,而犧牲其他任務的表現。不同於傳統RLHF方法,CGPO能夠智能檢測出不合規的生成內容,並通過約束策略進行調整。
2. 極端多目標優化問題的解決
多任務學習通常涉及多個甚至衝突的目標,傳統的RLHF框架難以處理這些目標之間的平衡。而CGPO通過為每個任務單獨設定評審和優化器,確保各任務能夠獨立優化其目標,避免了不同任務目標之間的相互妥協。最終,CGPO為多任務學習提供了更優的帕累托前沿解。
技術亮點:三大優化器與多評審機制
CGPO引入了三種主要的RLHF約束優化器——Calibrated Regularized Policy Gradient(CRPG)、Constrained Regularized Reward Ranking Finetuning(CRRAFT)、Constrained Online DPO(CODPO),這些優化器不僅有效解決了RLHF中的多任務優化難題,還具備強大的擴展性,適用於各種規模的LLM訓練場景。
1. CRPG優化器:通過結合獎勵建模與約束調整,確保模型生成高質量響應,同時防止偏離既定約束。實驗中,CRPG在數學、編程等需要精確計算和邏輯推理的任務中表現尤為突出。
2. CRRAFT優化器:通過獎勵排名策略,只保留滿足所有約束條件的生成結果,同時提升獎勵值。該優化器在真相問答、指令跟隨等任務中表現出色。
3. CODPO優化器:通過直接偏好優化,使得高獎勵值且符合同束的生成結果得以保留,提升模型整體表現。
CGPO處理多任務場景
在多任務環境下,CGPO通過「獎勵模型 + 多任務判定器 (MoJs) + 優化器」的組合,為每個任務提供量身定製的對齊指導,從而更好地適應每個任務的獨特特性,增加實現最優對齊結果的可能性。CGPO 框架的核心包括兩個部分:多目標獎勵建模和多專家對齊。
1. 多目標獎勵建模
CGPO的多目標獎勵建模不同於傳統RLHF(在多目標場景中的方法。傳統方法通常為所有任務使用統一的線性組合獎勵模型,而CGPO則先將提示集 D按照性質分類為不同、不重疊的子集,即 D = {D1, D2,…, DL},每個子集 Di 對應一個特定任務,例如包含有害意圖的提示歸為「有害意圖」任務,而一般對話提示歸為「普通對話」任務。
然後,針對每個任務,選擇一個合適的獎勵模型進行訓練,以確保每個任務在優化過程中只關注自身的目標指標,避免其他任務目標的干擾。通過這種分類和獎勵模型定製,CGPO 能更好地排除不相關或相互矛盾的目標,從而提高在每個任務中達成最優結果的可能性。
2. 多專家對齊
多專家對齊是指為每個任務應用定製化的多任務判定器(MoJs)、獎勵模型和優化器設置。在每個任務生成樣本後,使用專門為該任務定製的判定器來篩選不符合標準的生成結果。判定器的選擇因任務而異,以反映各獎勵模型的具體缺點和對LLM的預期標準。
例如,在「普通對話」任務中,判定器會專注於評估回覆的真實性和拒答情況,從而提升模型的響應性和可靠性。

而在「推理」任務中,則使用基於規則的數學/編程判定器,以確保輸出的準確性。在有約束要求且需要更廣泛探索的任務(如指令跟隨、數學和編程)中,CGPO 會採用較寬鬆的KL閾值,並允許每個提示生成更多的樣本;而在不需要廣泛探索的任務(如普通對話)中,則使用更嚴格的KL閾值,並減少生成樣本的數量。
CGPO 在每次迭代中處理各個任務,基於任務特定的提示集、獎勵模型、判定器來計算更新的梯度,然後將所有任務的梯度累加,並結合預定義的任務權重更新模型參數。通過這種方式CGPO 能在多任務、多約束的環境中高效地實現各任務之間的平衡與對齊,優化每個任務的獨特目標。
最終,CGPO 的設計使其能夠在多任務環境中更靈活地適應不同任務的需求,達成更高效的對齊和優化效果。
實驗驗證:CGPO的顯著性能提升
在多項任務的測試中,CGPO展現了顯著的性能優勢。具體來說,在通用聊天任務(AlpacaEval-2)、STEM問題解答任務(Arena-Hard)、指令跟隨(IFEval)、數學與推理(MATH和GSM8K)、編程任務(HumanEval)、以及知識問答(ARC Challenge)中,CGPO均大幅超越現有的RLHF算法如PPO和DPO。
實驗數據顯示,CGPO在AlpacaEval-2中相較PPO提升了7.4%,在Arena-Hard中提升了12.5%,而在數學推理任務(MATH和GSM8K)中,CGPO表現穩定,分別提升了2%,在人類評估(HumanEval)中的編程測試上則提升了5%
此外,PPO在編程任務中表現出獎勵欺騙行為,導致模型在訓練後期出現嚴重退化,而CGPO通過約束優化有效避免了這一問題,確保模型表現穩定。

在CGPO與PPO的性能對比中,CGPO結合CRPG和CRRAFT優化器在多個基準測試中持續提升,尤其在ARC Challenge、HumanEval、MBPP等任務上表現出色。
相比之下,PPO在編碼任務中出現顯著下滑,表明獎勵欺騙問題嚴重。雖然CODPO優化器表現稍弱,但總體上仍優於DPO和PPO,特別是在安全性任務中,CODPO取得了最佳結果,展示了其在多任務微調中的卓越效果。
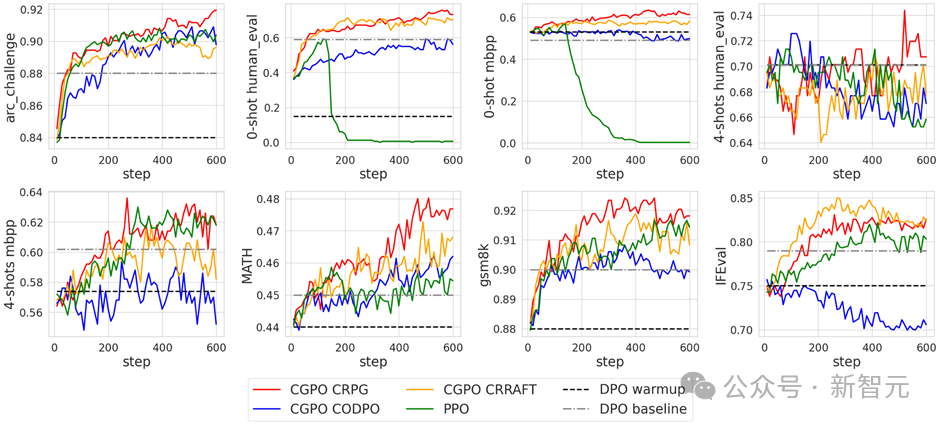
通過消融實驗可以發現MoJs不僅能防止在在編碼任務里的獎勵欺騙,還顯著提升了模型在MATH和GSM8K中的表現。

結論:CGPO為多任務學習的未來鋪路
CGPO框架的提出,為強化學習與人類反饋在多任務學習中的應用提供了革命性的新思路。
通過創新的混合評審機制與三大約束優化器,CGPO不僅有效解決了獎勵欺騙和極端多目標優化的難題,還為大型語言模型的後訓練提供了更穩定和高效的優化路徑。隨著研究的深入,未來我們有望看到更多基於CGPO的自動化優化方法,進一步提升多任務學習的表現。
參考資料:
https://arxiv.org/pdf/2409.20370











