大模型壓縮KV緩存新突破,中科大提出自適應預算分配,工業界已落地vLLM框架
中科大博士馮源 投稿
量子位 | 公眾號 QbitAI
改進KV緩存壓縮,大模型推理顯存瓶頸迎來新突破——
中科大研究團隊提出Ada-KV,通過自適應預算分配算法來優化KV緩存的驅逐過程,以提高推理效率。
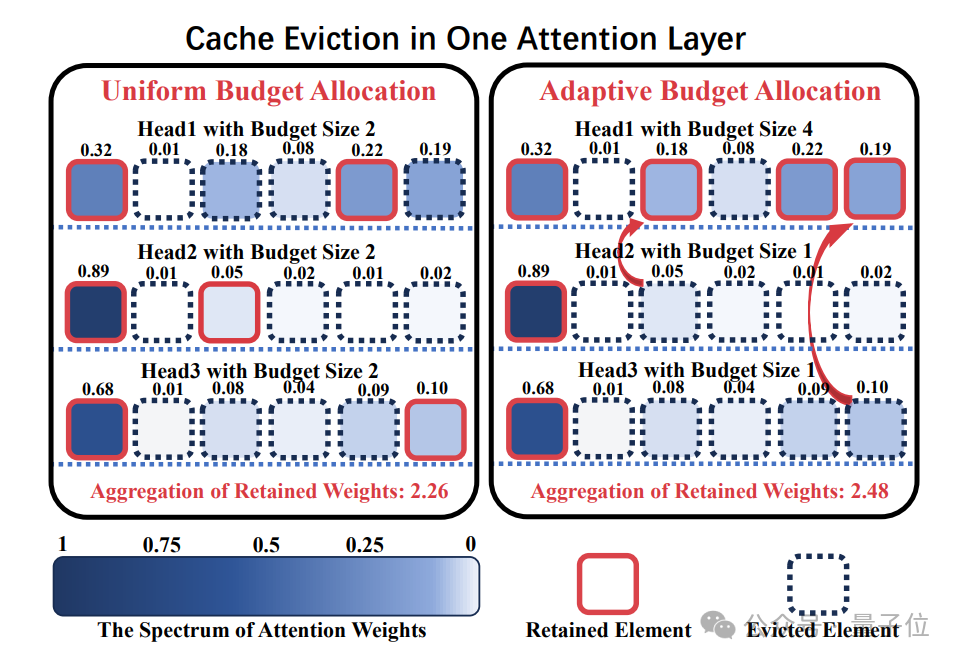
打破KV Cache壓縮將所有注意力頭分配相同壓縮預算的常規做法,針對不同的注意力頭進行適配性壓縮預算分配

展開來說,由於大模型在自回歸生成過程中,每生成一個新token都需要將對應的KV矩陣存儲下來,這導致緩存隨著生成序列長度的增加而急劇膨脹,引發內存和I/O延遲問題,尤其在長序列推理中尤為突出。
因此,KV緩存壓縮成為了一項必要的優化。
不過令人頭禿的是,現有壓縮方法往往在各個注意力頭之間平均分配預算,未能考慮其特性差異。
而中科大團隊在注意到——不同注意力頭關注度存在差異後,對其進行適配性壓縮預算分配,通過精細化運作帶來更高的壓縮質量。
相關研究不僅在學術界引起討論,更實現了工業界開源落地。
例如,Cloudflare workers AI團隊進一步將其改進落地於工業部署常用的vLLM框架中,並發佈技術報告,開源全部代碼。

KV緩存壓縮從均勻性預算分配→適配性預算分配
一開始,Ada-KV團隊首先思考:
注意力頭間的適配性壓縮預算分配是必要的嗎?
通過從經驗性和理論性兩個角度進行分析後,團隊的回答是:yes!
經驗性分析
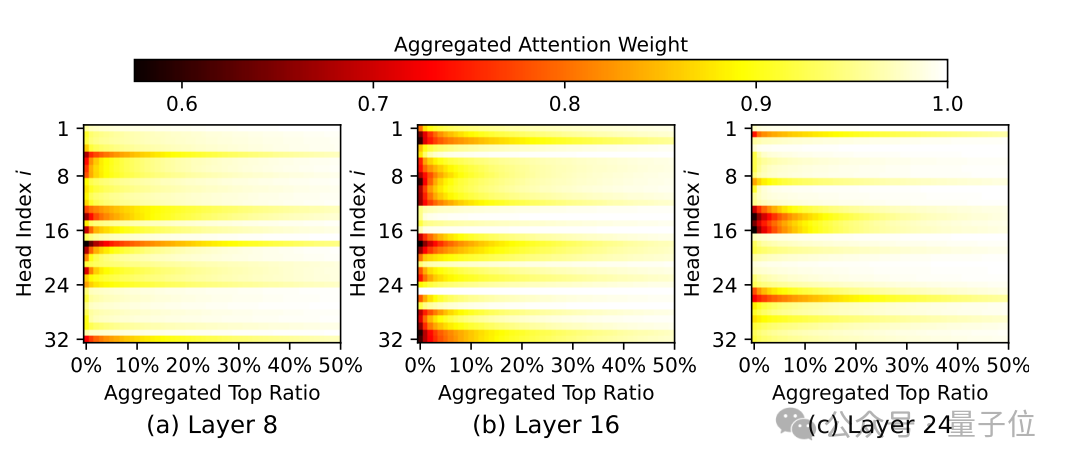
Ada-KV團隊發現,在大模型中注意力頭之間存在著顯著不同的關注集中度差異:
大部分注意力頭關注度集中在少量KV cache上,只需很少的KV cache(例如,1%)就可以幾乎收集接近0.9的注意力權重;
而少數注意力頭則傾向於分散注意力,往往需要接近50%的KV Cache才能夠將注意力權重聚集到0.9。
考慮到如此巨大的關注度集中度的差異,注意力頭間的適配性壓縮預算分配對於壓縮質量的提升有著巨大潛力。
理論性分析
Ada-KV研究團隊進一步從壓縮輸出損失的角度出發,形式化了在不同分配策略下KV Cache壓縮對注意力輸出的損失影響:
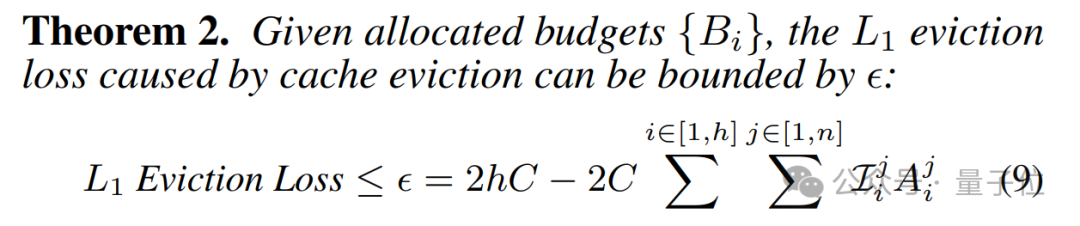
他們基於這一理論提出了一種以注意力權重為基礎的自適應分配方案,併發現這種跨注意力頭的預算分配策略始終能夠降低損失上界。
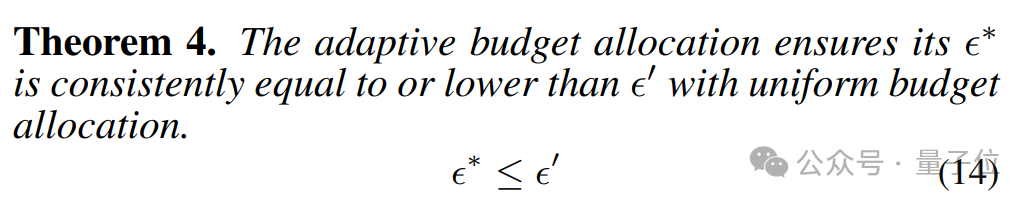
此外,這一理論上的更低損失上界在實際實驗中也展現出更低的注意力輸出損失:
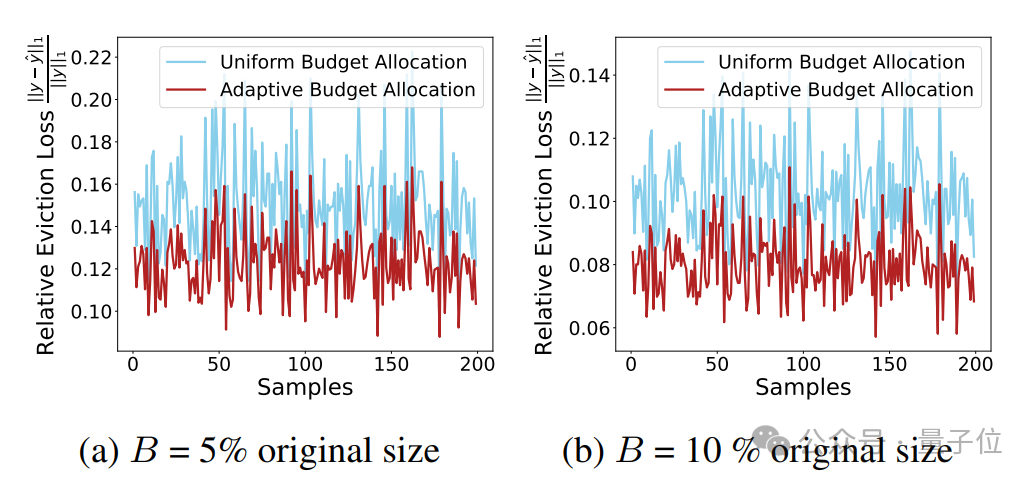
理論與實際結果一致驗證了這一結論:注意力頭間的適配性預算分配能夠顯著提升KV緩存壓縮的效果。
通過適配性頭間預算分配增強KV Cache壓縮質量
作者將Ada-KV這一適配性預算分配策略結合到現有的兩個領先的Cache壓縮方案:SnapKV和PyramidKV中,分別得到兩種適配性壓縮方案:Ada-SnapKV和Ada-Pyramid。
他們進一步在廣泛使用的長序列開源大模型Mistral-7B-Instruct-32K和LWM-Text-Chat-1M和長文本任務評估基準LongBench上的16個數據集上進行了充分的評估。
實驗結果顯示,所有適配性預算分配增強的壓縮方法(Ada-SnapKV和Ada-Pyramid)全部優於原有的均勻預算分配壓縮方法(SnapKV和Pyramid)。
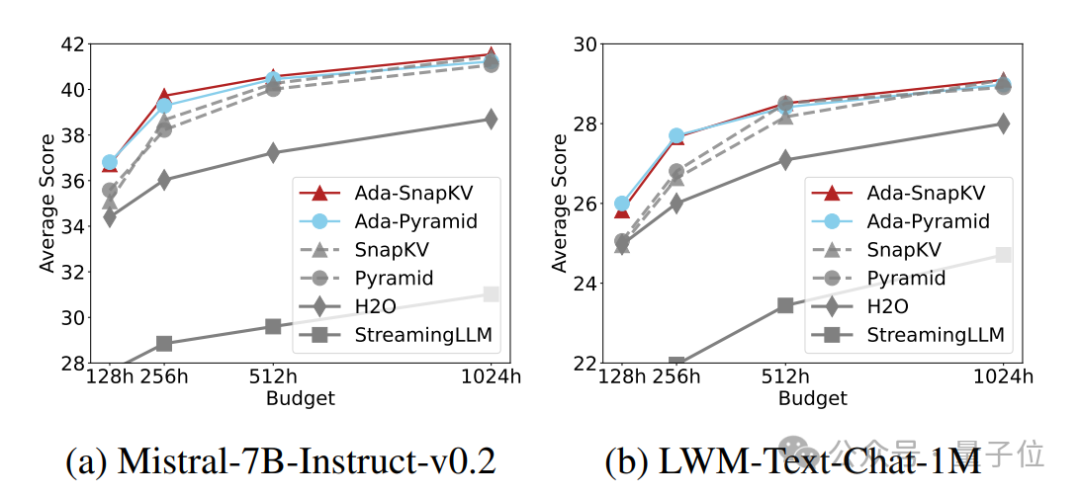
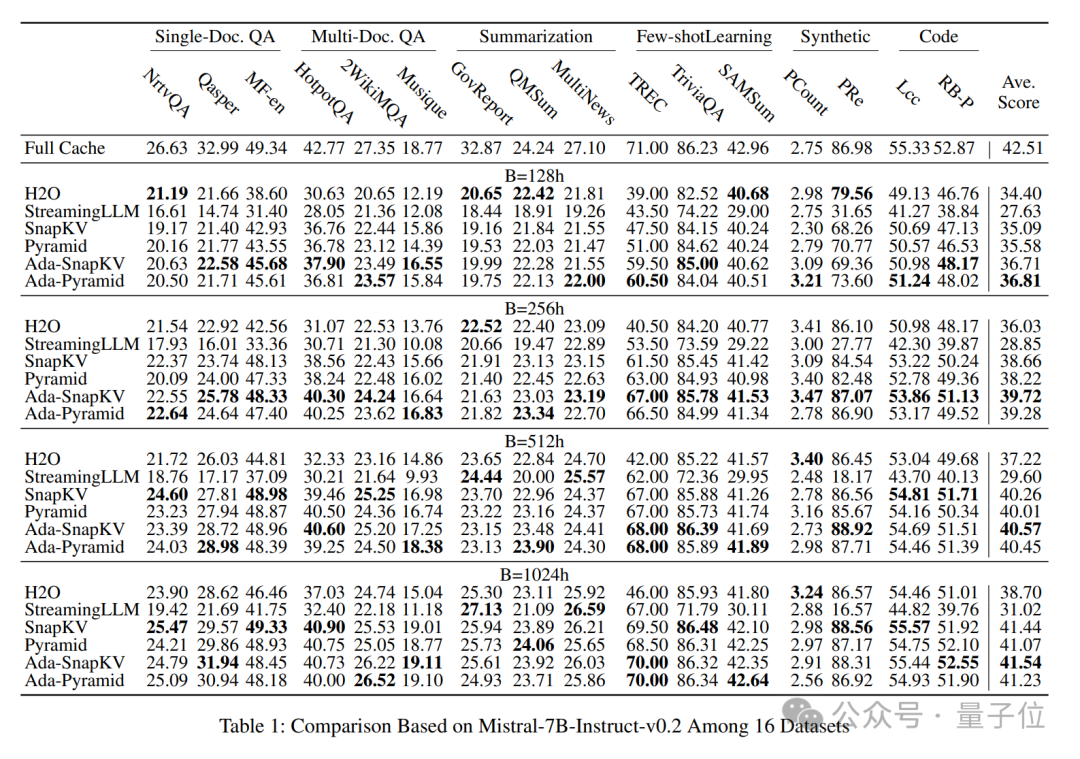
Ada-KV團隊在算法實現的同時,也考慮到了執行效率的優化。
他們開發了一種展平的KV Cache管理佈局,並定製了CUDA kernel,以實現高效的Cache更新管理。
結合Flash Attention技術,該方案在適應性預算分配的情況下,實現了高效推理,並在相同預算下保持了與先前Cache壓縮方案一致的計算效率。
目前,代碼已在GitHub上完全開源,助力推動注意力頭間適應性壓縮預算分配的研究。
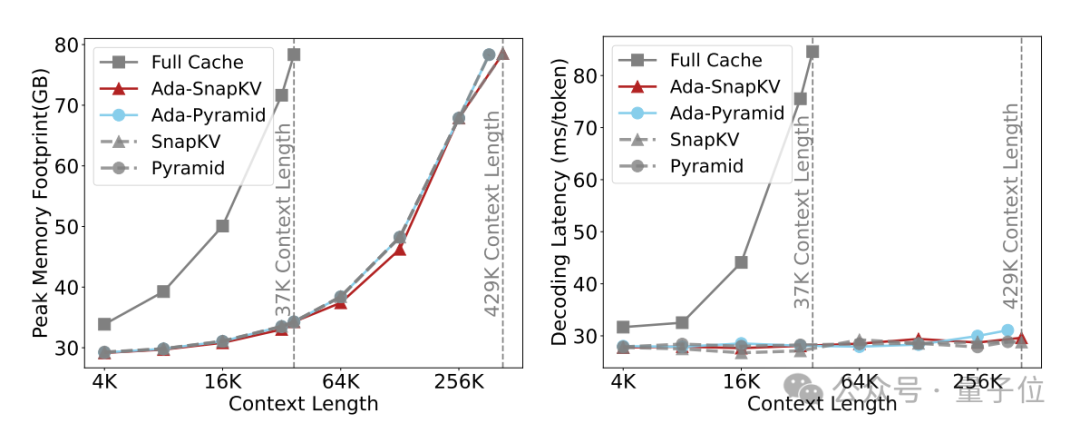
Cloudflare推動Ada-KV於工業界部署落地
Cloudflare公司旗下的Workers AI團隊針對實際併發服務場景中存在的內存碎片問題,基於Paged Attention重新實現了Ada-KV算法,並將其落地於實際部署使用的推理框架vLLM中。
他們發佈了技術報告,對該方案進行了詳細評估,同時開源了相關代碼,助力Ada-KV在工業界的快速應用和落地。
Ada-KV Paper:
https://arxiv.org/abs/2407.11550
Ada-KV Code:
https://github.com/FFY0/AdaKV
Cloudflare Technical Report:
https://arxiv.org/abs/2410.00161
Cloudflare Code:
https://github.com/IsaacRe/vllm-kvcompress