π0:通用機器人策略模型 讓機器人具備在人類環境中自主執行多種複雜任務的能力
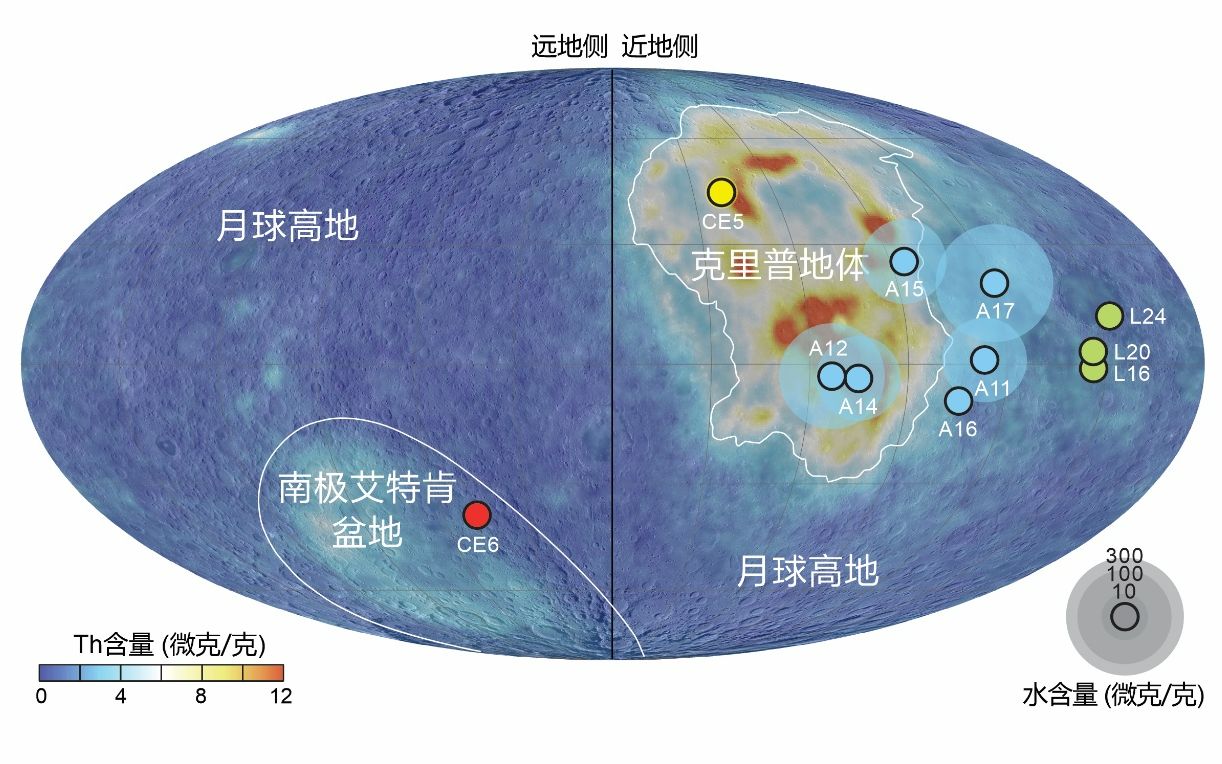
Physical Intelligence 公司推出了 π0(pi-zero),這是一個通用的機器人策略模型,專為實現機器人的「物理智能」而設計。即讓機器人具備在人類環境中自主執行多種複雜任務的能力。
它是一種「通用機器人策略模型」(Generalist Policy),能夠跨多種機器人和任務進行操作,實現從物體分類到動態操控的多種能力。這一模型的出現標誌著機器人從特定任務的「專家」向多任務的「通才」發展的重要一步。
該模型借助圖像、文本和動作數據進行訓練,旨在讓機器人具備靈活、適應性強的物理操作能力。
與當前僅能執行單一任務的傳統機器人不同,π0 讓機器人能夠執行多種複雜任務,如疊衣服、收拾桌子、組裝盒子等。
π0 的主要功能與特點
-
多任務處理能力
- π0 模型可以執行廣泛的任務,如疊衣服、收拾桌面、組裝盒子等。這些任務通常需要複雜的手部操作, π0 通過訓練多種機器人完成這些操作任務,使其具備極高的適應性和操作靈活性。
- 通過整合視覺、語言和動作數據,π0 能夠將多個機器人和不同任務的經驗融會貫通,實現多任務處理。
-
零樣本執行與任務微調
- π0 可以通過「零樣本」方式執行任務,即無需特定任務的樣本數據即可完成指令,適合在動態環境中直接應用。同時,它也支持「微調」功能,可以根據具體應用場景進行數據增強訓練,從而提高複雜任務的執行效果。
-
視覺-語言-動作模型架構
- π0 使用了一種「視覺-語言-動作」模型架構,不僅處理視覺和語言輸入,還生成連續的動作指令,能以每秒 50 次的頻率進行實時控制。這種高頻控制確保機器人在動態任務中具備靈活的運動調整能力。
-
廣泛的數據集支持
- 該模型的訓練數據包含來自 8 種不同機器人的交互數據,以及開放的圖像和文本數據集,使模型具備跨平台和跨任務的遷移學習能力。
- 數據集涵蓋了豐富的任務,包括複雜的物體操控和實時互動,例如:將碗疊放在一起,精準放置物品,甚至處理混雜的物體。
-
面向未來的機器人應用
- π0 的設計目的是為機器人提供普遍的物理智能,為未來的家庭和商業機器人應用奠定基礎。Physical Intelligence 表示,未來的研發將專注於讓機器人實現更高的自主性、長遠規劃和動態適應性,使其能夠在複雜環境中可靠地工作。
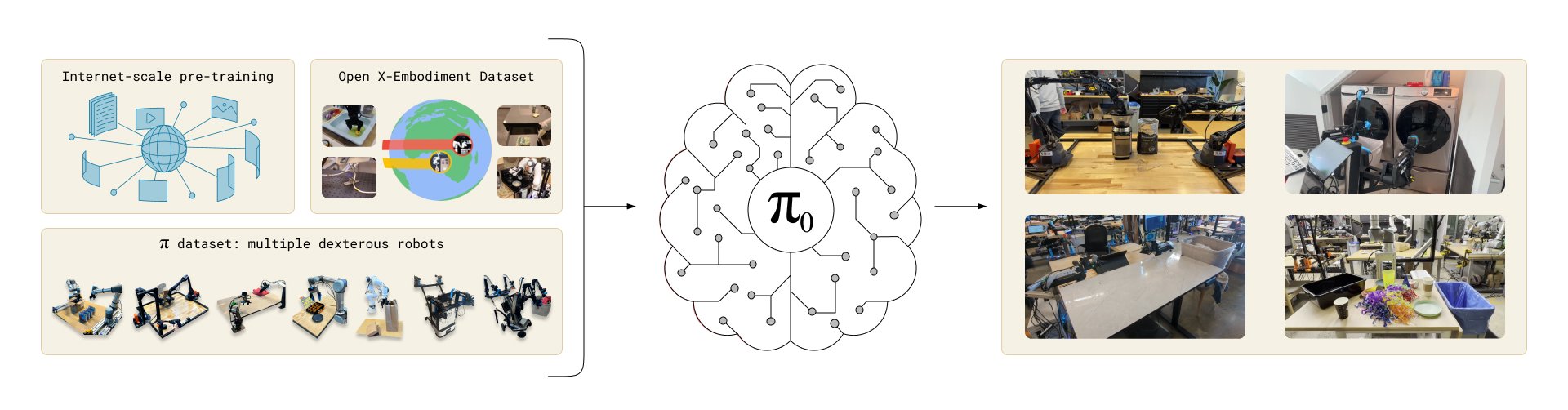
π0 的模型架構與技術特點
π0 是一種多模態、通用的機器人策略模型,結合了視覺、語言和動作數據,以實現複雜的物理任務操作。它在架構和技術方法上採用了獨特的設計,使其能夠適應多任務、多機器人的操作場景。
1. 視覺-語言-動作模型架構
- 視覺-語言模型(VLM):π0 以預訓練的視覺-語言模型(如 GPT-4V 或 Gemini)為基礎,這些模型在大量互聯網數據上進行訓練,能夠有效處理語義信息並理解文本和視覺內容。
- 動作輸出模塊:為了讓 VLM 適應連續的物理控制任務,π0 增加了一個動作輸出模塊,可以根據視覺和語言輸入生成動作指令。該模塊通過「流匹配」機制,能夠以高達每秒 50 次的頻率輸出低級運動指令,確保機器人在動態環境中能進行精確操控。
- 多模態融合:通過將視覺、語言和動作整合,π0 能夠在接收到用戶指令後,生成相應的物理動作,使其適應複雜任務的要求。
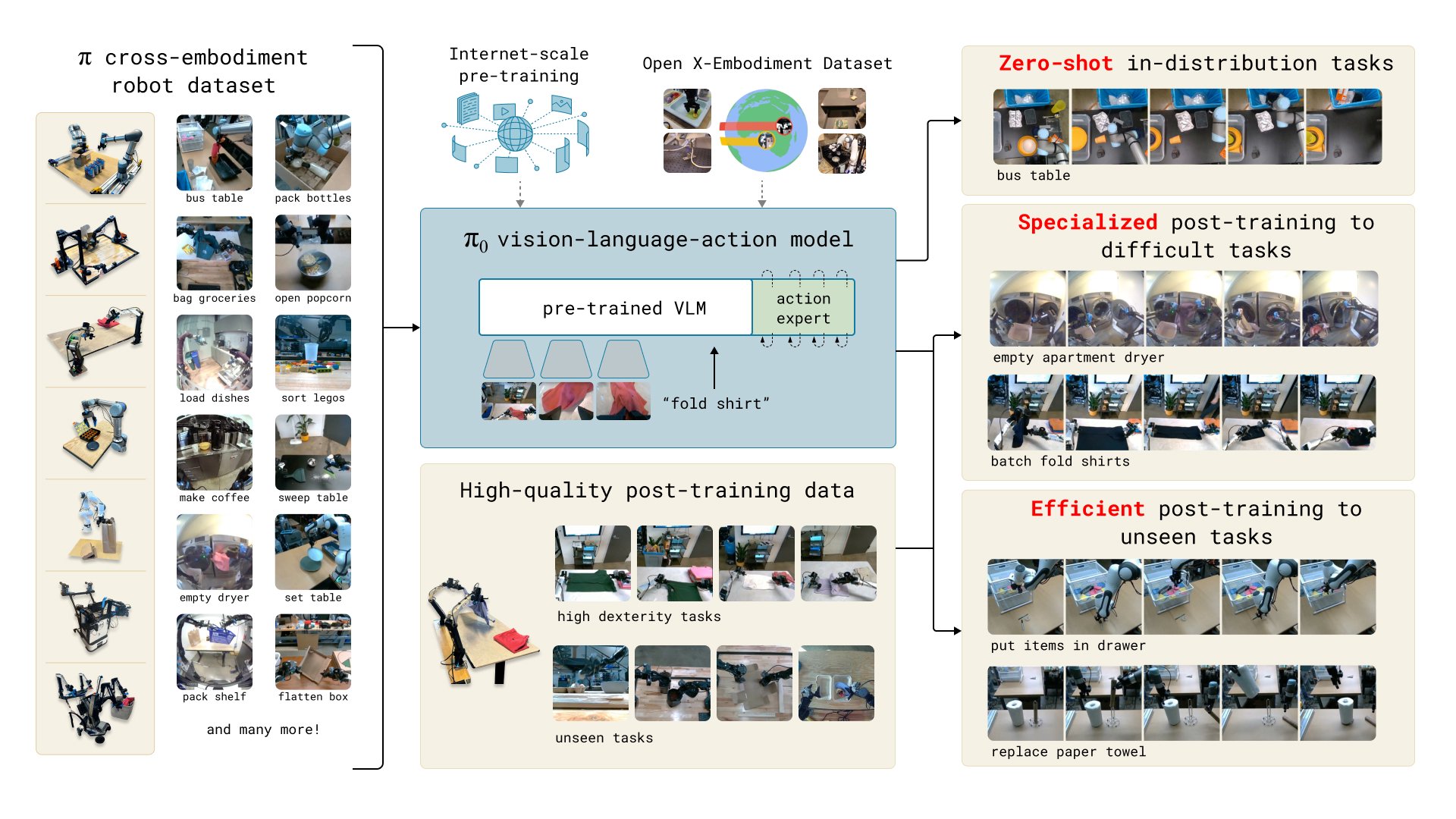
2. 流匹配方法(Flow Matching)
- 流匹配機制:π0 使用了一種基於擴散模型變體的「流匹配」方法。這種方法通過對連續的運動指令建模,實現了高頻率的動作控制。這與傳統的離散指令控制不同,流匹配可以輸出連續的動作,適合高精度的手部操控任務。
- 實時控制:流匹配方法通過連續的流輸出,不僅提高了操作的流暢性,還減少了因動作不連續造成的誤差,使 π0 能夠完成如疊衣服、裝箱等需要高度細膩的操作。
3. 跨機器人和多任務訓練
- 多機器人數據集:π0 的訓練數據來源於 8 種不同類型的機器人,涵蓋了廣泛的物體操控任務,例如收納物品、清理桌面、摺疊衣物等。通過多樣化的數據集訓練,π0 能夠在不同任務和機器人平台上遷移並適應操作。
- 任務多樣性:訓練數據中包含各種操作場景,每個任務的動作複雜性不一,從簡單的物品分類到涉及多個步驟的複雜任務。這種多樣化訓練讓模型獲得了更廣泛的操作經驗,具備應對實際複雜場景的能力。
4. 零樣本學習和微調能力
- 零樣本任務執行:π0 能夠在未接受特定任務訓練的情況下,直接在新任務上進行操作(即「零樣本」學習)。這種能力使得 π0 適合動態環境,無需重新訓練即可適應不同任務。
- 微調機制:對於需要精確操作的複雜任務,π0 還支持微調。通過在少量高質量數據上進行微調,模型能夠優化特定任務的表現,例如整理桌面、裝配物品等。這種方法類似於大語言模型的後期訓練,通過微調實現對特定任務的適應性。
5. 基於視覺-語言的語義理解與增強
- 預訓練模型的語義繼承:π0 利用預訓練視覺-語言模型的語義理解能力,從互聯網規模的數據中繼承豐富的語義知識。通過這些模型,π0 可以理解用戶指令的語義,並將其轉化為物理動作。
- 語義增強的動作生成:在接收到任務指令後,π0 通過其多模態理解架構,將語言和視覺內容轉化為動作輸出,實現了複雜的任務分解和逐步執行。例如在整理物品任務中,π0 可以根據物品位置和指令,逐步將物品放置到指定位置。
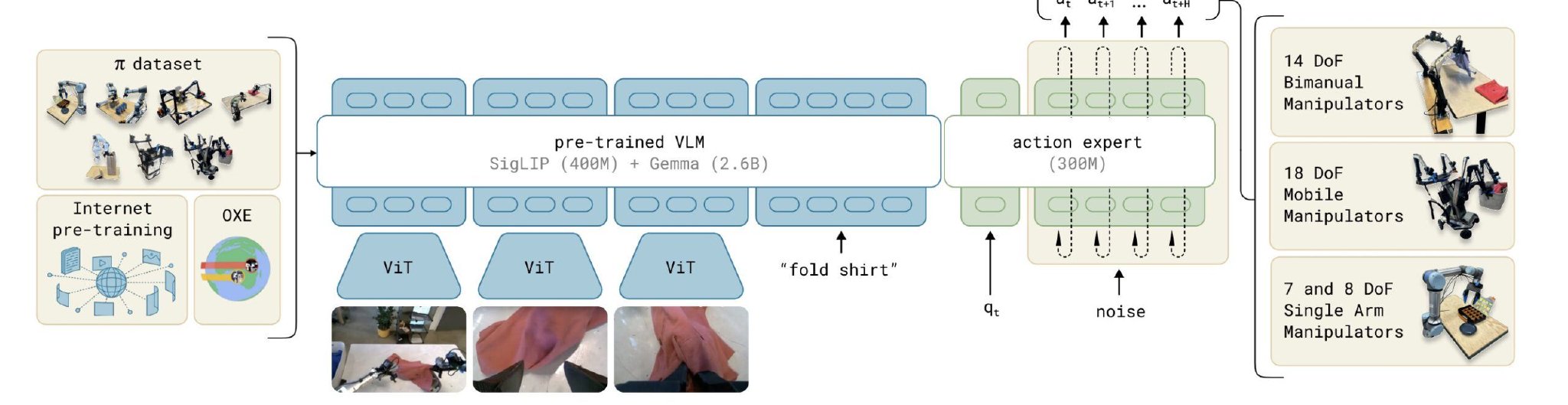
6.多機器人兼容性:
- π0模型能夠處理多種不同類型的機器人配置,包括單臂機器人、雙臂機器人和移動機械臂。它的架構設計允許模型適應不同的動作空間和配置,確保在多種硬件平台上實現通用性。
- 通過跨機器人數據的訓練,π0能夠在一個通用模型中整合多種機器人動作表達,使其在任務和設備間具有更強的適應性。
7.分階段訓練策略(預訓練和微調):
- π0採用分階段訓練策略。首先進行大規模的預訓練,模型在多樣化的任務數據上學習通用的視覺、語言和基本的動作控制能力。
- 在預訓練的基礎上,進行後續微調,使模型能夠更精準地執行複雜的特定任務。這種策略確保模型既有通用性,又具備執行特定任務的精細化能力。
8.動作專家模塊:
- π0在VLM的基礎上增加了動作專家模塊,專門用於處理機器人動作。這一模塊將視覺和語言輸入轉化為具體的動作輸出,利用單獨的參數和流匹配技術生成連續的動作序列。
- 動作專家模塊的設計類似於混合專家模型(Mixture of Experts),將視覺、語言處理和動作生成進行分離並優化,使得模型能夠同時處理多模態輸入和複雜動作輸出。
9.多模態融合與動態任務指令:
- π0能夠處理多模態的任務指令,包括自然語言和視覺信息。在處理複雜任務時,π0可以接受動態的指令調整,通過將視覺和語言信息融合,確保機器人在任務中更靈活地應對多變的場景。
π0 模型的評估結果
在測試 π0 的物理操作能力時,Physical Intelligence 公司對其在多任務和不同機器人的應用場景中進行了嚴格評估。以下是 π0 相對於其他模型的表現評估結果。
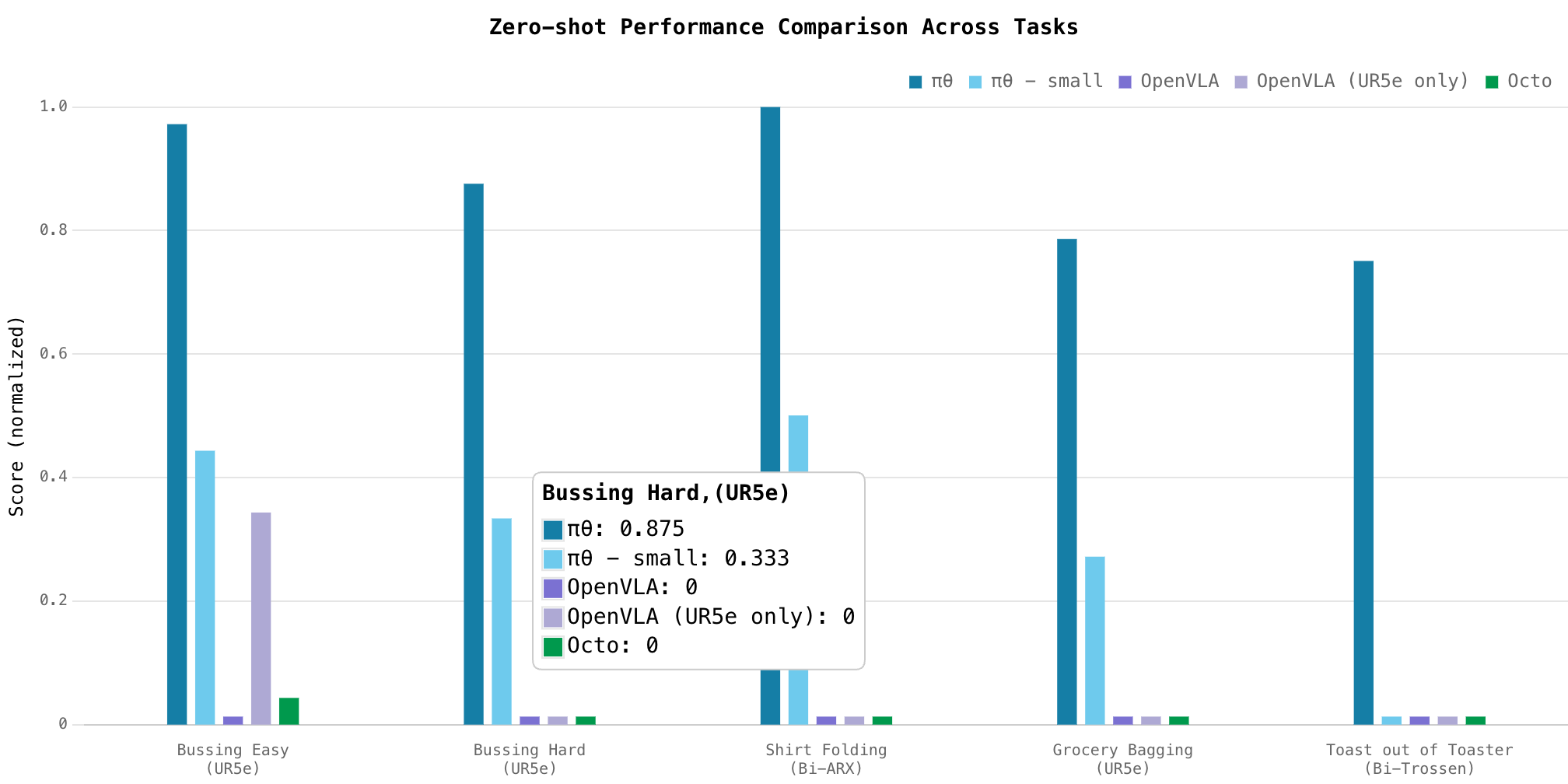
1. 評估任務和標準
- 任務範圍:π0 被測試在多個複雜任務上,包括疊衣物、收拾餐具、組裝盒子等,這些任務要求機器人具備高度的靈活性和適應性。
- 評分標準:評估採用分級評分體系,成功完成任務可得 1.0 分,部分成功的任務按比例得分(例如,完成一半任務可得 0.5 分)。評估結果以平均分來衡量模型在各項任務上的綜合表現。
2. 與其他模型的對比
- 對比模型:π0 的表現與其他機器人策略模型進行了對比,包括 OpenVLA(7B 參數,離散動作控制)和 Octo(93M 參數,擴散模型輸出)。
- 零樣本測試結果:π0 在所有測試任務中表現出色,尤其在更複雜的任務(如分類與疊放物品)中展現了出色的適應性和靈活性。
- 得分表現:π0 在所有測試任務中的平均分遠超其他模型,表現優異。其簡化版本 π0-small 雖未使用預訓練的視覺-語言模型,但仍優於 OpenVLA 和 Octo,且π0 完整版的性能比 π0-small 高出 2 倍以上。
3. 關鍵任務結果
- 疊衣物:π0 在此任務中表現極佳,能夠完全自主地將衣物從烘乾機中取出、放置到桌面上並摺疊整齊。與其他模型不同,π0 具備識別和調整的能力,即便在任務中受到干擾,也能重新恢復並完成任務。
- 收拾桌面:π0 在桌面清理任務中表現出色,不僅能將餐具和垃圾區分開,還會根據物體的不同屬性,使用不同的操作策略。例如,將多個盤子疊在一起搬運到指定位置,或在將盤子放入收納籃之前先抖落掉上面的殘渣。
- 組裝盒子:在這個任務中,π0 能夠從扁平的紙板開始,將其摺疊成盒子結構,並完成各個卡扣的固定。此任務要求機器人能夠根據實時的任務進度進行調整,而π0 能夠在任務失敗或卡住時自我調整以繼續完成。
一些案例:
以下是 π0 在一些複雜任務中的具體應用案例,這些任務展示了該模型在多任務環境中的靈活性和適應性:
1. 疊衣服
- 任務描述:機器人需要從烘乾機中取出衣物,放在桌面上並將其疊成整齊的衣物堆。
- 任務挑戰:該任務不僅需要精準的手部控制,還要求機器人在應對不同衣物形狀和厚度時能夠靈活調整動作。傳統機器人在遇到衣物纏繞或變形時可能難以操作。
- π0 的表現:π0 能夠識別並處理不同衣物的形態,適時調整其抓取力度和摺疊手法。即便在任務過程中受到干擾(如有人故意打亂衣物堆),它也能重新規劃操作順序,順利完成疊衣物的任務。
當有人嘗試以各種不同方式進行干預時,機器人能夠恢復重新執行任務。
2. 收拾餐桌
- 任務描述:機器人需要將桌面上的餐具和垃圾分別放入指定的收納籃和垃圾桶中。
- 任務挑戰:餐桌上的物品種類繁多,且大小、形狀、材質各異,這要求機器人具備高度的分類能力和靈活的操作策略。
- π0 的表現:π0 展示了智能的分類能力,可以通過視覺和語義理解,將餐具(如盤子、刀叉)堆疊在一起搬到收納籃中,並將垃圾分離後投入垃圾桶。此外,π0 能夠在操作中採用更為高效的策略,例如一次性抓取多個物體,或在放入前抖落盤子上的殘渣。
3. 組裝盒子
- 任務描述:從一塊扁平的紙板開始,將其摺疊成盒子,並完成每個摺疊邊的固定。
- 任務挑戰:盒子組裝需要對每一步的摺疊和固定位置準確無誤,且在摺疊過程中需使用雙臂或借助桌面以避免結構鬆散。
- π0 的表現:π0 通過視覺-動作模型的精準控制,能夠在摺疊過程中自我調整,即便遇到摺疊失敗或紙板滑動等情況,也能快速調整位置繼續組裝。該模型甚至能靈活使用桌面作為支撐,確保盒子在摺疊和固定過程中不會鬆散。
4. 整理桌面雜物
- 任務描述:整理桌面上的多種雜物,包括筆、文件夾、小物件等,將它們分門別類地放置在不同區域。
- 任務挑戰:不同物品可能形狀各異、材質多樣,且需要合理的擺放和歸類。傳統機器人需要預先設置動作程序,難以在複雜的環境中靈活調整。
- π0 的表現:π0 能夠根據物品的外觀和屬性,將物品按照類別整理,例如將書本和文件整齊堆放在一起,將筆類物品放入筆筒,垃圾則直接投入垃圾桶。π0 的操作展現出人類般的思維邏輯,使桌面整理更為高效且直觀。
詳細介紹:https://www.physicalintelligence.company/blog/pi0
論文:π0.pdf