NeurIPS 2024:清華、加州理工重磅研究:強化自訓練方法 ReST-MCTS*,讓大模型持續「升級」
文 | 學術頭條
大語言模型(LLM)的自訓練(self-training),是驗證 Scaling Law 能否繼續奏效的關鍵方法之一。
然而,由於「錯誤或無用的中間獎勵信號」,現有自訓練方法通常會產生低質量的微調訓練集(如不正確的規劃或中間推理),儘管這可能不會影響 LLM 在一些任務中的正確性,但卻會限制 LLM 微調複雜任務的最終性能。
解決方法之一是使用價值函數或者獎勵模型來驗證推理路徑的正確性,然後作為自訓練的學習信號。然而,訓練一個可靠的獎勵模型來驗證推理路徑中的每一步,通常依賴於密集的人類標註(每個推理步驟),並不能很好地擴展。
如今,來自清華大學知識工程研究室(KEG)和加州理工學院的聯合研究團隊解決了這一難題。他們開發的強化自訓練方法 ReST-MCTS*,通過樹搜索 MCTS* 指導過程獎勵,既可以自動獲取可靠的推理路徑,也能有效地利用獎勵信號進行驗證和 LLM 自訓練。

論文鏈接:
https://arxiv.org/abs/2406.03816
GitHub 地址:
https://github.com/THUDM/ReST-MCTS項目地址:https://rest-mcts.github.io/
具體來說,ReST-MCTS* 通過基於樹搜索的強化學習規避了用於訓練過程獎勵的每步人工標註:在給定 Oracle 最終正確答案的情況下,ReST-MCTS* 能夠通過估算每一步有助於得出正確答案的概率,推斷出正確的過程獎勵。這些推斷出的獎勵既是進一步完善過程獎勵模型的價值目標,也有助於為策略模型的自訓練選擇高質量的軌跡。
實驗結果表明,在相同的搜索預算下,ReST-MCTS* 中的樹搜索策略比 LLM 推理基線(如 CoT + Best-of-N 和 Tree-of-Thought)實現了更高的準確率;另外,將這種樹搜索策略搜索到的軌跡作為訓練數據,可以在多次迭代中持續增強 LLM,優於 Self-Rewarding LM 等其他自訓練算法。
研究方法
為了提高模型自動獲取可靠推理路徑的能力,該研究旨在探索基於模型自動獲取高質量推理路徑以優化獎勵信號和模型自訓練性能過程中的關鍵難點與挑戰。
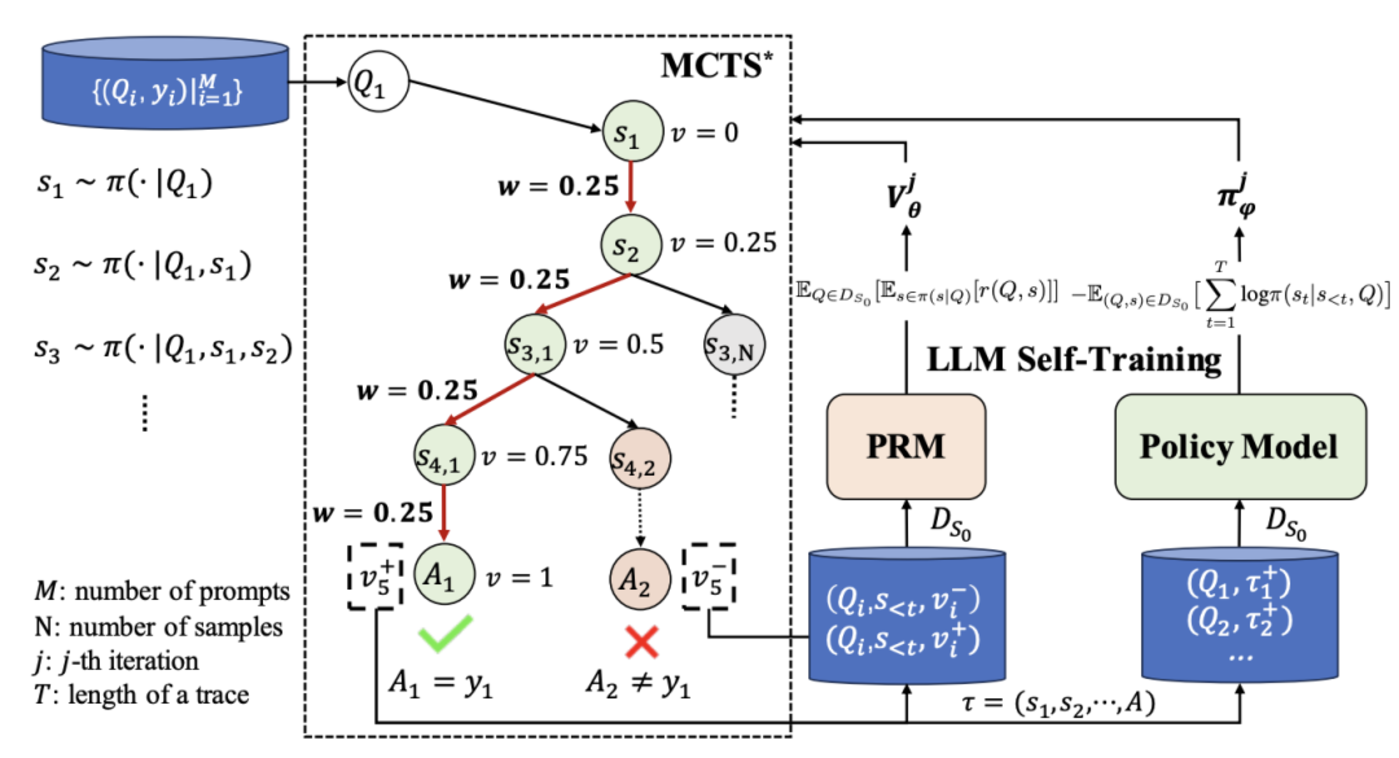
圖|推斷過程獎勵的過程以及如何進行過程獎勵引導樹搜索(左),過程獎勵模型(PRM)和策略模型(Policy Model)的自訓練(右)。
該研究的四個核心組件是:
首先,針對現有方法的局限性,研究團隊建立了一個全新的搜索算法 MCTS*,該算法是蒙特卡羅樹搜索(MCTS)的一個變體,使用每個推理步驟的質量值作為一個訓練好的基於 LLM 的過程獎勵模型的價值目標,並為 MCTS 提供指導,能夠通過足夠的部署次數自動標註每個中間節點的過程獎勵。
此外,他們還提出了一個過程獎勵模型(PRM),該模型能夠準確地計算每個推理步驟的獎勵值。該研究將研究過程獎勵引導與樹搜索相結合,以探索有效的解空間併合成高質量的軌跡。該研究首先計算對於每個樹節點在每棵樹中得到正確答案所需的最小推理步驟數,至少有一條推理路徑(包括根)。然後,該研究使用過程值的硬估計方法計算獎勵值,這意味著一個推理步驟如果能得到每棵樹中正確的答案,就被認為是正確的。使用最小推理距離和獎勵值,該研究能夠推導出在一個正確推理路徑上或附近的每個節點的部分解的值。對於每個節點,將至少有一個正確的路徑和相關的前進步驟。當推理距離設置為相同的上一步推理距離時,該研究可以使用部分解答過程的質量值的計算過程推導出質量值和加權獎勵。該研究從根節點開始更新所有獎勵和值,並且收集它們形成成對的新數據集。該數據集用於在下一個迭代中訓練過程獎勵模型。注意,在上述過程中搜索樹會被修剪並且驗證推理軌跡。
在此基礎上,他們結合了監督學習的微調技術,構建了一個新的自訓練方法,旨在生成樹搜索的過程獎勵和高質量的多步推理路徑,用於實現過程獎勵模型和語言模型相輔相成的自訓練。具體而言,在初始化策略模型和過程獎勵模型之後,該研究迭代地使用它們,並且利用過程中生成的搜索樹為特定的科學或數學問題生成高質量的解決方案,並進行一個自我提升過程。
實驗結果
研究團隊從以下三方面驗證了 ReST-MCTS* 的有效性。
首先,研究團隊使用生成樣本並進行多次迭代評估的自訓練方法,如 ReST^EM 和 Self-Rewarding,在三個 LLM backbone 下的分佈內和分佈外基準上進行了評估。結果顯示,ReST-MCTS* 在每次迭代中都優於現有方法,且能夠通過自身生成的數據不斷自我完善,如下表。
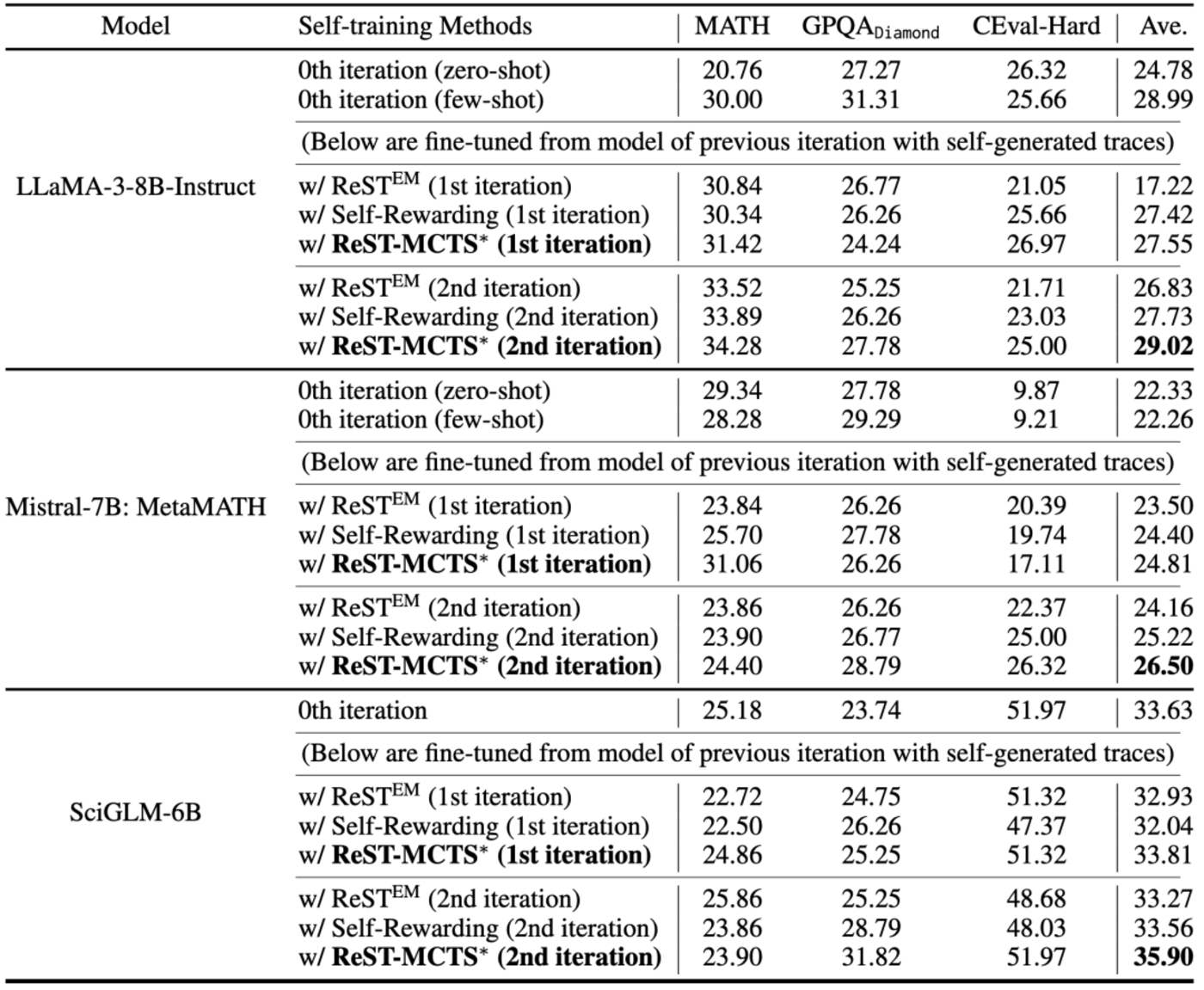
表|通過對策略和價值模型進行多次迭代訓練得出的初步結果。對於每個 backbone,都分別採用不同的自訓練方法。這意味著每種方法都有自身生成的訓練數據和相應的獎勵(價值)模型。
然後,他們在 GSM8K 和 MATH500 上對比了 MATH-SHEPHERD(MS)和 SC + MS 等 SOTA 過程獎勵模型。結果表明,ReST-MCTS* 學習到了一個很好的過程獎勵模型,他們的獎勵模型實現了更高的準確率,如下表。

表|不同驗證器在 GSM8K 測試集和 MATH500 上的準確率。SC: Self-Consistency,MS: MATH-SHEPHERD。驗證基於 256 個輸出。
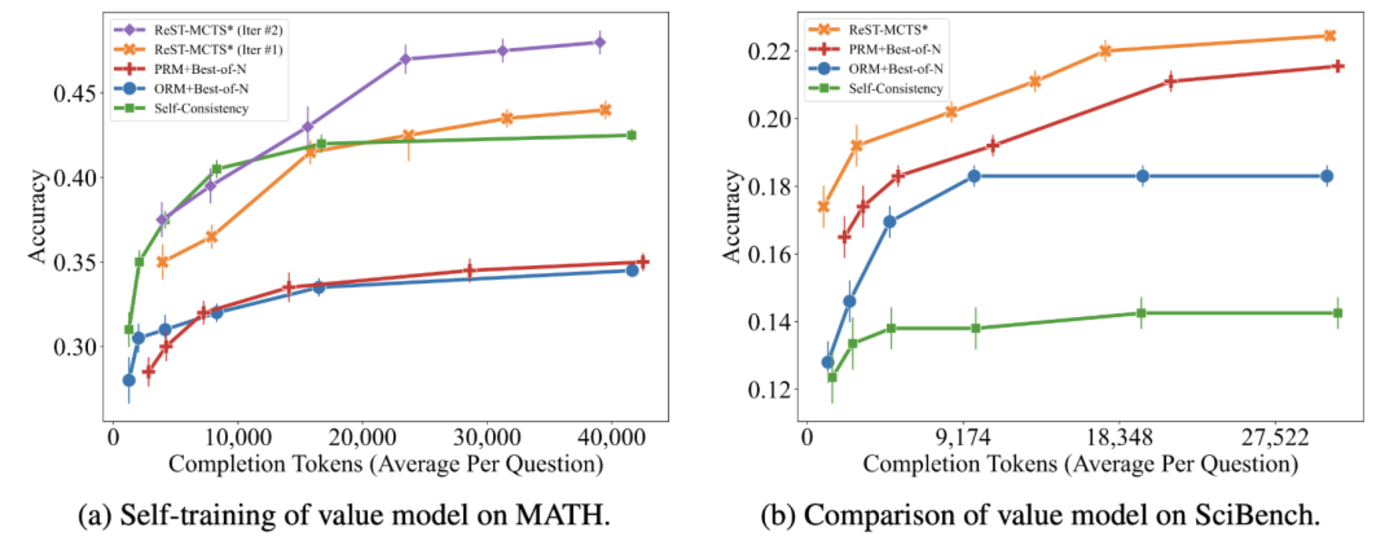
他們還在 MATH 和 SciBench 上進行了相同搜索預算的評估。結果表明,儘管預算不足,ReST-MCTS* 仍明顯優於其他基線。
最後,他們基於 ReST-MCTS*、CoT 和 ToT 樹搜索策略分別對比了三個 LLM 在大學水平科學推理基準上的表現,如下表。
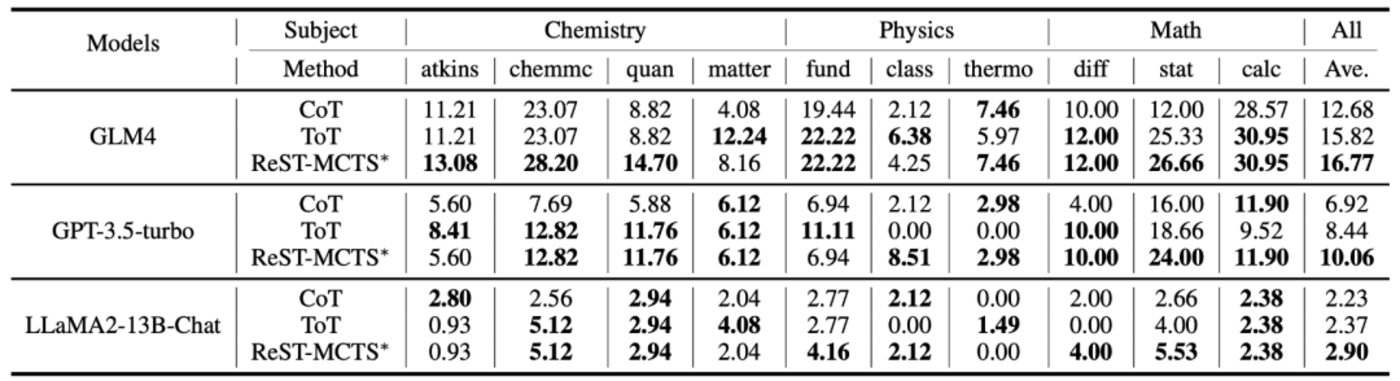
表|代表性模型在 SciBench 評測集上的總體性能比較。
不足與展望
當然,這項研究也存在一定的局限性。
例如,研究團隊還需要證明 ReST-MCTS* 可以推廣到數學以外(如編碼、agent 等)的其他推理任務,以及沒有 ground-truth(如對話、SWE-Bench 等)的任務。另外,他們還需要擴展所提出的價值模型,並進一步改進數據過濾技術。一個潛在的想法是結合在線 RL 算法,幫助價值模型和策略模型進行更好的自訓練。具體如下:
1.泛化性有待驗證
與許多其他自訓練研究相似,ReST-MCTS* 也依賴於監督數據集中的 ground-truth oracle 標籤來過濾響應;未來,研究團隊需要證明 ReST-MCTS* 可以泛化到數學以外(如編碼、智能體、對話等)的其他推理任務,以及沒有 ground-truth(如對話、SWE-Bench 等)的任務。
此外,對於那些需要多步規劃和推理的非常複雜的任務(如實施整個軟件,如 SWE-Agent 等),沒有 ground-truth 答案,還需要一種更好的方法來收集獎勵反饋(來自少數人類標籤和符號執行或求解器),並訓練一個可通用的獎勵模型,使其能夠在更廣泛的任務中發揮作用並提供幫助。
2.價值模型的規模和多樣性仍需擴展
雖然研究團隊基於 Mistral7B: MetaMATH 訓練出的價值模型比 SOTA 價值模型 MATH-SHEPHERD 性能更好,但要更好地進行過程獎勵模型訓練,仍然需要更大規模的價值模型 backbone。此外,訓練過程獎勵模型的初始訓練集是由 SciGLM 生成的,該模型側重於數學和科學推理任務,但仍然缺乏通用性。雖然目前的過程獎勵模型在 MATH 和 SciBench 等多個數學和科學推理任務上取得了 SOTA,但仍然值得探索更多樣化的訓練集,以便將來擴展到代碼生成和智能體規劃等多個領域。
3.進一步改進自訓練數據過濾
推理軌跡的質量影響著自訓練的效果,而生成高質量的訓練集起著重要作用。因此,研究團隊通過訓練迭代過程獎勵模型來引導樹搜索方向,從而獲得高質量的軌跡。另一方面,由於價值模型可以幫助篩選出過程值最高的 top-k 生成軌跡,因此他們也希望將更強、更大的 LLM 模型作為價值模型的 backbone。