GPT-4o加錢能變快,新功能7秒完成原先23秒的任務
OpenAI出了個新功能,直接讓ChatGPT輸出的速度原地起飛!
這個功能叫做「預測輸出」(Predicted Outputs),在它的加持之下,GPT-4o可以比原先快至多5倍。
以編程為例,來感受一下這個feel:

為什麼會這麼快?用一句話來總結就是:
跳過已知內容,不用從頭開始重新生成。
因此,「預測輸出」就特別適合下面這些任務:
在文檔中更新博客文章
迭代先前的響應
重寫現有文件中的代碼
而且與OpenAI合作開發這個功能的FactoryAI,也亮出了他們在編程任務上的數據:

從實驗結果來看,「預測輸出」加持下的GPT-4o響應時間比之前快了2-4倍,同時保持高精度。
並且官方還表示:
原先需要70秒完成的編程任務,現在只需要20秒。
值得注意的是,目前「預測輸出」功能僅支持GPT-4o和GPT-4o mini兩個模型,且是以API的形式。
對於開發者而言,這可以說是個利好消息了。
網民們在線實測
消息一出,眾多網民也是坐不住了,反手就是實測一波。
例如Firecrawl創始人Eric Ciarla就用「預測輸出」體驗了一把將博客文章轉為SEO(搜索引擎優化)的內容,然後他表示:
速度真的超級快。
它就像在API調用中添加一個預測參數一樣簡單。
另一位網民則是在已有的代碼之上,「喂」了一句Prompt:
change the details to be random pieces of text.將詳細信息更改為隨機文本片段。
來感受一下這個速度:

也有網民曬出了自己實測的數據:
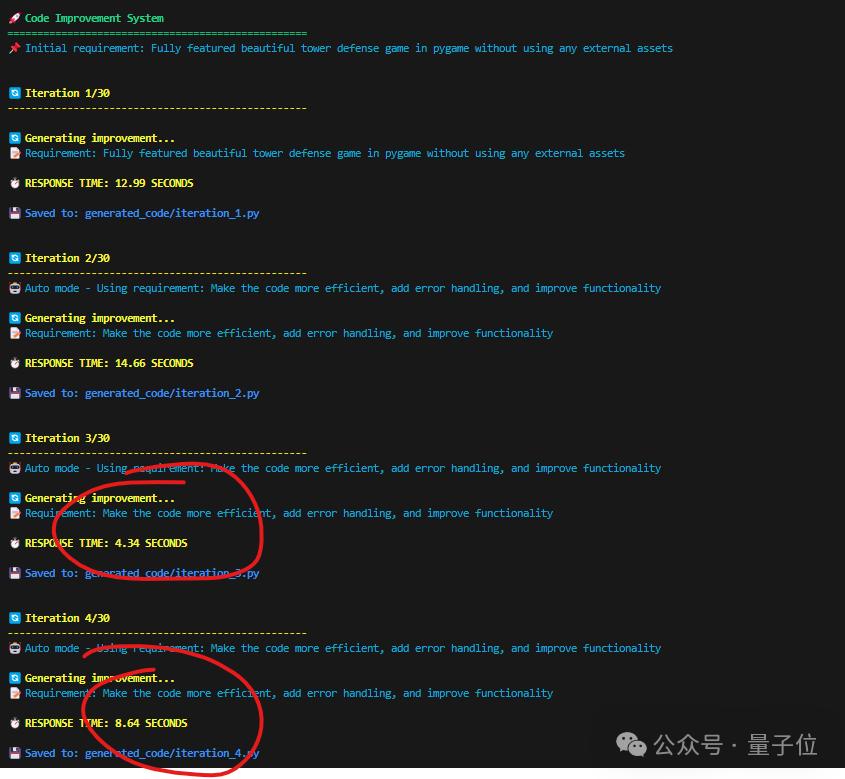
總而言之,快,是真的快。
怎麼做到的?
對於「預測輸出」的技術細節,OpenAI在官方文檔中也有所介紹。

OpenAI認為,在某些情況下,LLM的大部分輸出都是提前知道的。
如果你要求模型僅對某些文本或代碼進行細微修改,就可以通過「預測輸出」,將現有內容作為預測輸入,讓延遲明顯降低。
例如,假設你想重構一段 C# 代碼,將 Username 屬性更改為 Email :

你可以合理地假設文件的大部分內容將不會被修改(例如類的文檔字符串、一些現有的屬性等)。
通過將現有的類文件作為預測文本傳入,你可以更快地重新生成整個文件。


使用「預測輸出」生成tokens會大大降低這些類型請求的延遲。
不過對於「預測輸出」的使用,OpenAI官方也給出了幾點注意事項。
首先就是我們剛才提到的僅支持GPT-4o和GPT-4o-mini系列模型。
其次,以下API參數在使用預測輸出時是不受支持的:
n values greater than 1
logprobs
presence_penalty greater than 0
frequency_penalty greater than 0
audio options
modalities other than text
max_completion_tokens
tools – function calling is not supported
除此之外,在這份文檔中,OpenAI還總結了除「預測輸出」之外的幾個延遲優化的方法。
包括「加速處理token」、「生成更少的token」、「使用更少的輸入token」、「減少請求」、「並行化」等等。
文檔鏈接放在文末了,感興趣的小夥伴可以查閱哦~
One More Thing
雖然輸出的速度變快了,但OpenAI還有一個注意事項引發了網民們的討論:
When providing a prediction, any tokens provided that are not part of the final completion are charged at completion token rates.在提供預測時,所提供的任何非最終完成部分的tokens都按完成tokens費率收費。
有網民也曬出了他的測試結果:
未採用「預測輸出」:5.2秒,0.1555美分
採用了「預測輸出」:3.3秒,0.2675美分

嗯,快了,也貴了。
OpenAI官方文檔:https://platform.openai.com/docs/guides/latency-optimization#use-predicted-outputs
參考鏈接:
[1]https://x.com/OpenAIDevs/status/1853564730872607229
[2]https://x.com/romainhuet/status/1853586848641433834
[3]https://x.com/GregKamradt/status/1853620167655481411
本文來自微信公眾號「量子位」,作者:金磊,36氪經授權發佈。









