研究實錘:別讓大模型「想」太多,OpenAI o1準確率竟下降36.3%
文 | 學術頭條
思維鏈(CoT)已被證明可以在許多任務(如多步驟推理)上顯著提升大模型的性能。然而,在哪些情況下,CoT 會系統性地降低大模型的性能,這仍然是一個有待進一步討論的問題。
如今,來自普林斯頓大學和紐約大學的研究團隊,參照思考對「人類性能」的影響,提出了新的見解。
他們認為,雖然模型的認知過程與人類的認知過程並不完全相同,但可以參照思考對人類「性能」產生負面影響的情況,假定思考會對模型產生負面影響的環境。
他們從心理學中選擇了 6 項已被充分研究的任務類型來探討 CoT 對 LLM 性能的影響,並驗證了 CoT 在一些任務中甚至可能導致模型準確率下降。
這一發現不僅為未來優化 LLM 的提示策略提供了新思路,還為理解人類與模型在推理過程中的相似性與差異性帶來了新見解。

論文鏈接:
https://arxiv.org/abs/2410.21333
研究表明,CoT 並非在所有任務中都能提高模型性能,在隱性統計學習、面部識別、含例外模式的數據分類三種情況下,各種 SOTA 模型的性能都會明顯下降。此外,研究本身進一步揭示了通過人類心理學研究大模型的可行性。
研究方法
為分析 CoT 對大語言模型(LLM)與多模態大模型(LMM)性能的影響,該研究的方法框架基於以下兩個關鍵條件:
(1)言語思考或深思熟慮會損害人類「性能」的情況。
(2)將製約人類「性能」的因素推廣到語言模型的情況。
之後,為驗證「CoT 在一些任務中會導致模型表現下降」的假設,研究團隊在上述兩個條件的指導下基於人類心理學設計了以下 6 種任務場景:
-
隱性統計學習(Implicit Statistical Learning):考察模型在隱含語法結構的分類任務中使用 CoT 是否會降低表現。基於心理學中的實驗結果,該研究假設人類在進行語言推理時往往表現較差,因此 CoT 在該場景下應有類似的效果。
-
面部識別(Facial Recognition):在該任務中,模型需要識別圖像中的人臉。基於人類在口頭描述面部特徵後識別率下降的現象,研究假設 CoT 會影響模型的面部識別準確性。
-
含例外模式的數據分類(Classifying Data with Patterns that Contain Exceptions):該任務模擬模型在含有異常標籤的數據中學習的表現。研究假設 CoT 會導致模型在遇到例外情況時增加學習輪次,因為人類通常會傾向於建立簡單規則,從而忽視個別特例。
-
解釋邏輯不一致(Explaining a logical inconsistency):在邏輯一致性判斷任務中,模型需要識別出兩句話之間的邏輯衝突,該任務通常會引發人類的語言推理困難。
-
空間直覺(Spatial Intuitions):模型需要推斷液體在傾斜容器中的位置。該任務依賴空間和運動直覺,心理學研究表明人類在使用語言推理時效果不佳,該研究假設模型也會遇到類似問題。
-
特徵聚合決策(Aggregating Features for a Decision):模型在多維度決策情境中聚合信息並做出決策。由於信息過載通常會導致人類在 CoT 模式下表現不佳,因此研究假設在該任務中,CoT 將不會提高模型性能。
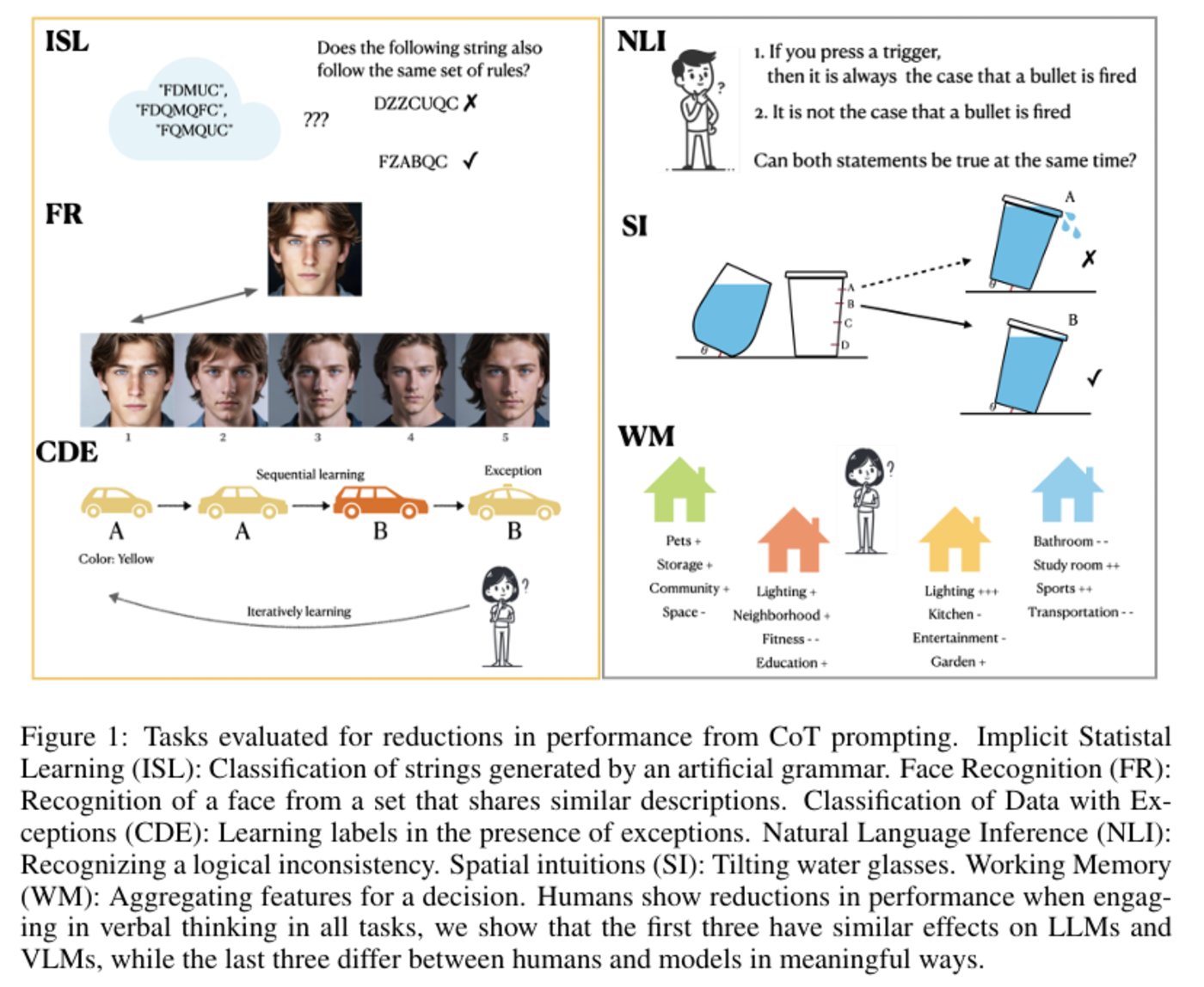 圖|對 6 項任務進行評估,以確定 CoT 提示是否會降低任務的績效。(來源:該論文)
圖|對 6 項任務進行評估,以確定 CoT 提示是否會降低任務的績效。(來源:該論文)針對每個任務場景,研究團隊分別構建了零樣本(zero-shot)和 CoT 提示條件,並在多個主流 LLM 和 LMM 上進行測試,包括 GPT-4o、Claude 3.5、Llama 等,通過對比不同條件下模型的準確率,量化 CoT 提示的效果,從而驗證他們的假設。
實驗結果
研究團隊首先對滿足上述兩個關鍵條件的 3 類任務場景進行實驗驗證。
隱性統計學習
針對該情境,該研究考察了模型在分類基於特定語法結構的序列時的表現。任務包含 4400 個分類問題,基於 100 種有限狀態語法(FSG)結構,每個測試提供 15 個樣例,再要求模型對新序列進行分類。
實驗結果顯示,使用 CoT 提示的模型表現顯著下降,尤其是 OpenAI o1-preview 模型的準確率下降了 36.3%。這表明當模型過度依賴逐步推理時,CoT 可能會抑制其對隱性統計模式的學習能力。
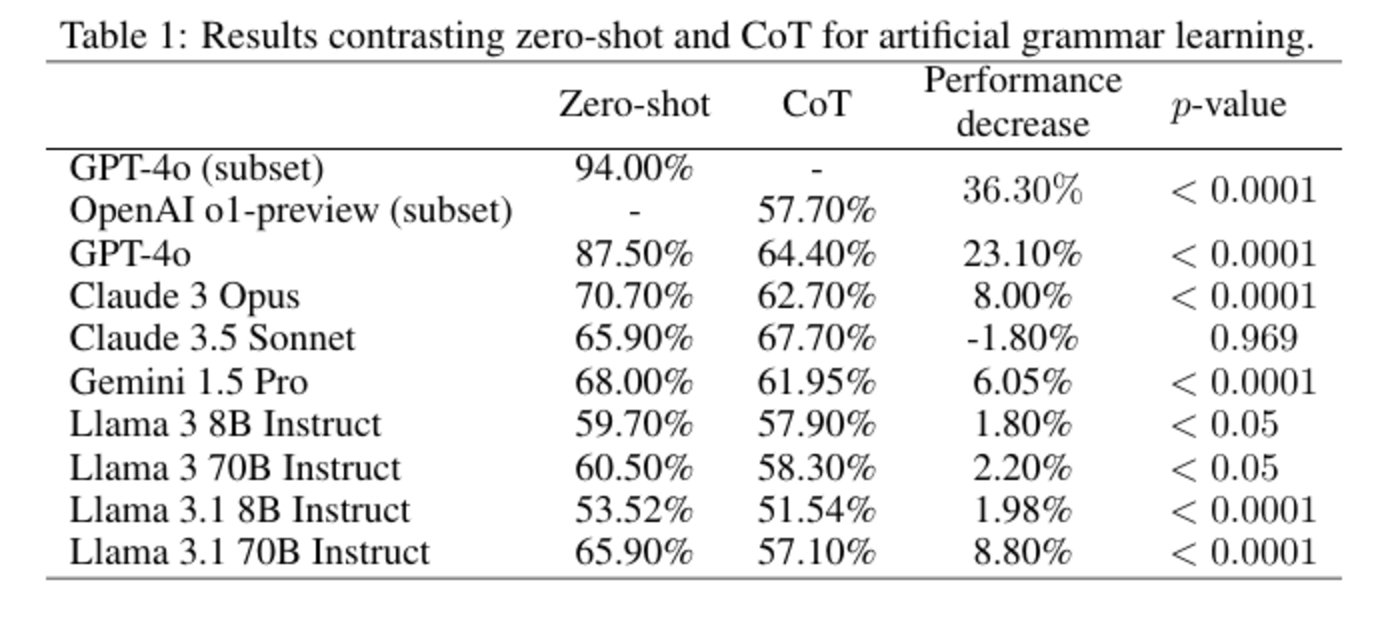 圖 | 人工語法學習中 zero-shot 和 CoT 對比結果。(來源:該論文)
圖 | 人工語法學習中 zero-shot 和 CoT 對比結果。(來源:該論文)面部識別
在該任務情境中,該研究測試了 CoT 是否會影響模型的面部識別能力,這是基於心理學中「語詞遮蔽」現象進行的任務情境設計。模型需要在 500 項任務中從 5 個候選中匹配初始人臉。
結果表明,當被要求執行 CoT 時,每個被測試的 LMM 都顯示出性能下降,與假設一致。
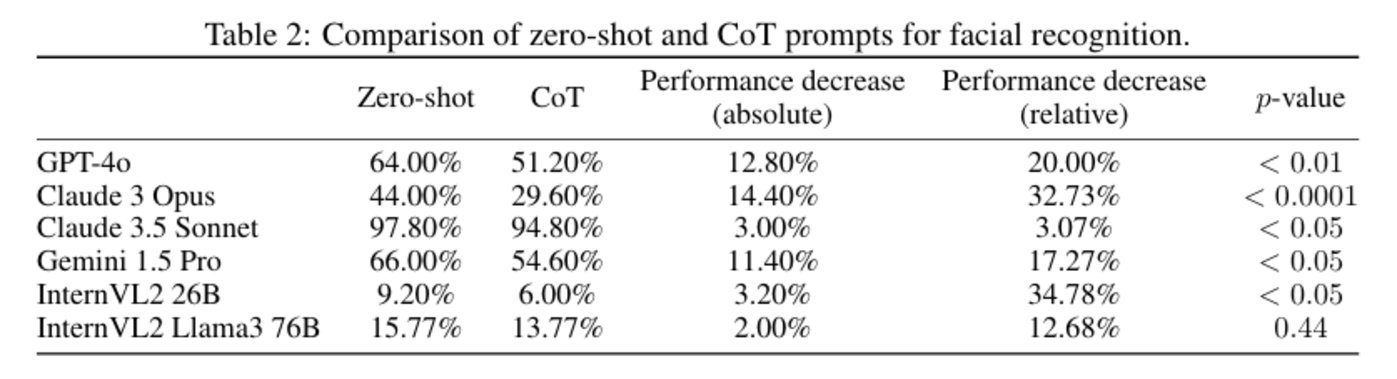 圖|面部識別中 zero-shot 和 CoT 提示的對比。(來源:該論文)
圖|面部識別中 zero-shot 和 CoT 提示的對比。(來源:該論文)含例外模式的數據分類
該任務通過包含多個主次特徵的分類任務來測試模型在處理含例外情況時的表現,任務要求模型在多次分類中逐步學習,目標是儘可能減少迭代次數。
實驗在 GPT-4o、Claude 3.5 Sonnet 和 Claude 3 Opus 上進行,結果表明,CoT 顯著增加了學習輪次。平均來看,GPT-4o 在 CoT 條件下完成正確分類所需的輪次為直接提示的四倍,而 Claude 3.5 Sonnet 和 Claude 3 Opus 的輪次需求也分別增加至直接提示的兩倍多。
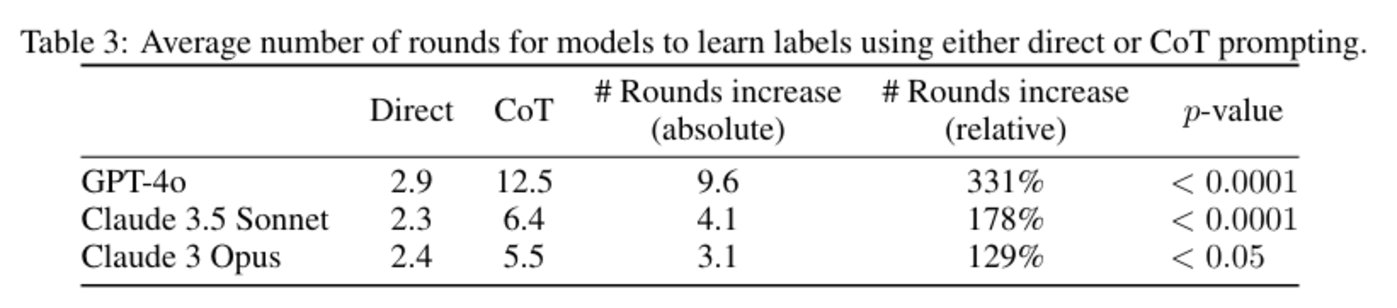 圖|使用直接或 CoT 提示,模型學習標籤的平均輪數。(來源:該論文)
圖|使用直接或 CoT 提示,模型學習標籤的平均輪數。(來源:該論文)在 GPT-4o 的進一步分析中發現,直接提示使模型在第二或第三輪就能達到完美分類,而使用 CoT 時模型在第四到第五輪僅能正確分類 8/10 的對象。這表明 CoT 提示會引導模型偏向基於規則的推理方式,而忽視了已知的正確答案,導致分類效率大幅下降。
之後,研究團隊又對滿足條件(1)但不滿足條件(2)的三類任務情境開展實驗。
解釋邏輯不一致
在該任務中,模型需要識別句子對中的邏輯矛盾性。該任務基於 SNLI 和 MNLI 數據集以及合成數據集。
研究發現,CoT 增加了模型忽視矛盾的可能性,模型在逐步推理時更傾向於關注複雜的邏輯結構,從而忽視了直接矛盾判定。這表明在需要精確邏輯驗證的任務中,CoT 提示存在局限性。
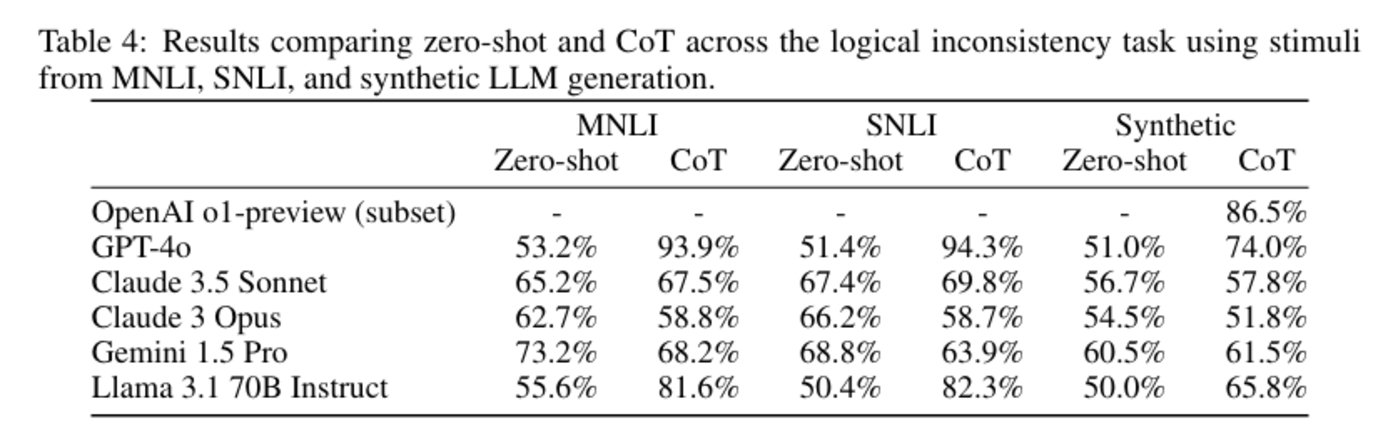 圖|邏輯不一致任務中比較 zero-shot 和 CoT 的結果。(來源:該論文)
圖|邏輯不一致任務中比較 zero-shot 和 CoT 的結果。(來源:該論文)空間直覺
在該情境中,模型需要通過「傾斜杯子」的問題來推斷水面的位置。這類任務依賴於人類的空間或運動直覺,而人類通常在非言語思維下表現更好。
模型接收了視覺提示和多項選擇答案,實驗結果顯示,使用 CoT 提示對模型表現無明顯影響。這說明在依賴空間或運動直覺的任務中,模型的推理方式與人類的直覺差異較大,因而 CoT 提示的負面影響較小。
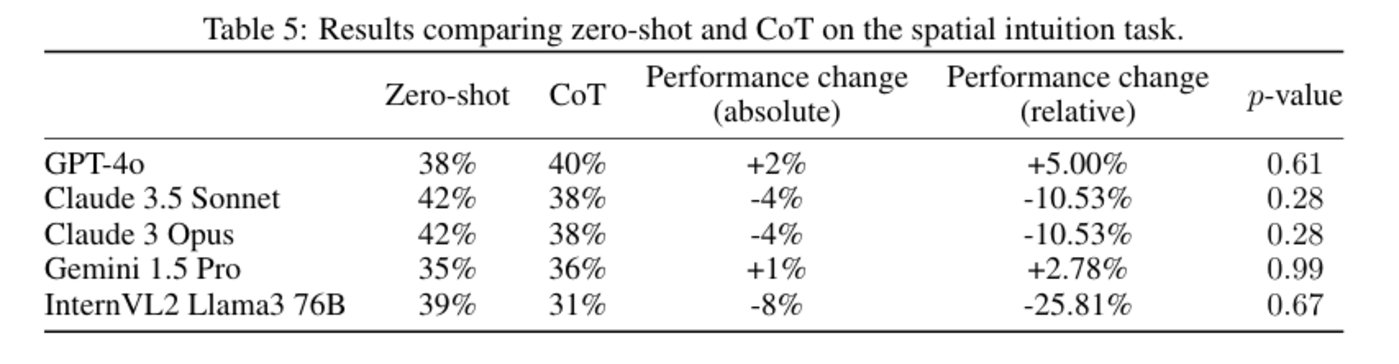 圖|空間直覺任務中 zero-shot 和 CoT 的比較結果。(來源:該論文)
圖|空間直覺任務中 zero-shot 和 CoT 的比較結果。(來源:該論文)特徵聚合決策
此任務模擬了基於多項特徵的決策過程(如選房),用於測試信息超載對決策的影響。人類在類似任務中由於記憶限制,往往在 CoT 模式下表現較差。相對地,模型保留了所有上下文信息,能夠無損地聚合和評估每項特徵。
結果顯示,CoT 提示在高上下文記憶任務中提高了模型表現,說明在信息保留至關重要的場景下,CoT 提示能夠發揮正向作用。
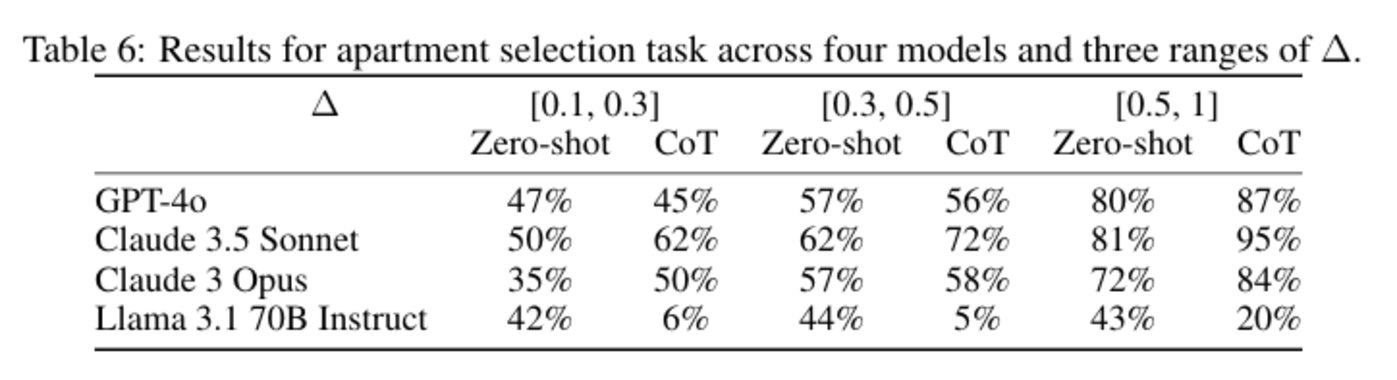 圖|四種模型和三種範圍內的公寓選擇任務結果。(來源:該論文)
圖|四種模型和三種範圍內的公寓選擇任務結果。(來源:該論文)不足與展望
當然,該研究也存在一些局限性,如下:
inference-time 推理的類型。自從 CoT 提示被提出以來,研究人員開發了多種特定於應用領域的提示方法,以及更複雜的多次前向傳遞的通用提示方法,如思維樹(tree-of thought)和自一致性(self-consistency)。他們在 GPT-4o 模型上測試了思維樹方法在隱式統計學習任務中的有效性,發現其確實提高了分類準確率(64.55% vs. 62.52%),但仍遠低於零樣本推理的 94.00% 準確率。未來的研究仍需探索此方法是否可以適用於其他任務領域和模型中激發語言思維的方法。
應用範圍。儘管這一研究基於心理學的啟髮式方法提供了一種識別 CoT 失敗案例的策略,但這無法涵蓋所有可能導致 CoT 表現下降的情況。現有的心理學研究基於多種理論和實際考量來研究人類,並不能提供涵蓋所有任務的詳盡或代表性樣本,且會遺漏一些僅在模型中具有研究價值的特殊案例。
關於 CoT 未能複製人類結果的替代解釋。對於 CoT 在後面三個任務中沒有觀察到表現下降,存在一種替代解釋——在 LLM 中實現這些任務的方式消除了表現下降的效果。雖然研究對後三個任務情境進行了多種變體的探索,但由於提示的變化幾乎是無窮無盡的,這些探索並不詳盡。
研究團隊表示,雖然該研究聚焦於 CoT 推理,但所提出的框架為利用人類心理學研究評估和改進模型表現提供了一種通用策略。
他們認為,未來還需要更多的跨學科合作,通過將自然語言處理方法、心理學見解與人類和模型表現比較的相關研究相結合,可以形成更全面的 AI 評估和改進策略。