Nature論文成果:研究人員發現AI模型越大,可靠性下降越多
在過去幾年,大模型面臨著不可靠性演變的局限性和挑戰。隨著這些模型的擴展(使用更多的計算資源)以及後期塑造(使用人類反饋),大模型與人類用戶在交互中的可靠性卻沒有受到全面分析。
其中一個原因是學術界一直沒有重視在評測中利用任務難度去提高對通用人工智能系統評估的穩健性與全面性。
 為了填補先前研究中的空白,改善人工智能評測的穩健型與全面性,以及加深人們對大模型可靠性的理解,近日來自西班牙華倫西亞理工大學團隊於 Nature 發表了《更大且更易於指導的語言模型變得不那麼可靠了》(Larger and more instructable language models become less reliable)[1]。
為了填補先前研究中的空白,改善人工智能評測的穩健型與全面性,以及加深人們對大模型可靠性的理解,近日來自西班牙華倫西亞理工大學團隊於 Nature 發表了《更大且更易於指導的語言模型變得不那麼可靠了》(Larger and more instructable language models become less reliable)[1]。華倫西亞理工大學本科畢業生周樂鑫是第一作者,荷西-靴南迪斯-奧拉羅(Jose Hernandez-Orallo)教授擔任通訊作者。
圖|相關論文(來源:Nature)
該研究或是世界上首次對通用人工智能系統的穩健評估,歸功於其在 0-100 的連續範圍內納入了對人類對任務難度的預期考量。
在這次研究中,該團隊從三個維度探討了大模型的可靠性和演變,其一是人類對任務難度的預期與大模型性能之間的不一致性現象。
他們的分析發現,雖然更大且更遵循指令的大模型在人類認為超高難度的許多任務中表現不錯,但是它們在許多同一領域超低難度的任務中仍然會失敗,而人類則不認為它們應當失敗。
因此,目前大模型沒有一個「安全區」可以讓人類確信大模型可以完美地運行,哪怕只是針對非常低難度的任務區域。
實際上,較新的大模型只在高難度任務上有明顯進步,這加劇了人類難度預期與大模型性能之間的不一致,導致人類更難通過任務困難度去預判模型的錯誤輸出。
這一點對於需要級高可靠性的應用場景非常重要,因為其在使用大模型期間需要識別具有近乎為零錯誤率的「安全操作區域」。
這與人們的預期相悖,即隨著模型變得越來越大,其遵循指令的可靠性應當越來越強。
人們會理所當然地認為,新模型在完成簡單任務時的表現會更加可靠,從而用戶可以利用任務困難度去更好的預測的大模型的錯誤分佈。
接著,該團隊針對大模型的「任務迴避行為」分析了大模型不可靠性的第二個維度。該課題組介紹了大模型如何通過回覆「我不知道」,或偏離原問題來避免回答問題。
研究結果表明,早期的模型傾向於迴避問題,從而暴露了大模型的局限性。
但是,新的模型相對於較早期的大模型(如 GPT-4 與 GPT-3), 錯誤率大幅上升,因為現在的模型很少規避回答超出其能力範圍的任務或問題。
在某些基準測試中,研究人員甚至發現錯誤率的上升比正確率的提高更快。
這種從「迴避」到「自信地給出錯誤回覆」的轉變,增加了用戶誤判的風險,從而可能導致用戶一開始過度依賴大模型來完成其並不擅長的任務,不過從長遠來看,他們可能會失望。
除了這一結果之外,該團隊還評估了大模型是否會像人類一樣,隨著任務難度的增加而更頻繁地迴避任務。不過測試情況並非如此:任務難度與迴避任務之間的相關性基本為 0。
這種異於人類的自大行為模式,以及先前提到的模型錯誤不可預測性,導致了人類必須仔細審查模型的輸出,以便發現並糾正錯誤。
但正如課題組在另一項人類研究「人類監督和監督限制」中所展示的那樣,人類並不擅長這種工作。
該研究分析了大模型可靠性的第三個維度——「模型性能對同一問題的微小表述變化的敏感度」。
目前對於如何提高模型對同一問題的不同提示語的魯棒性,人們對此知之甚少。研究人員觀察到,提示語的穩定性隨著擴展和成型而提高。
然而,這種改進似乎在逐漸減少,而且提示詞靈敏度仍然會導致最新模型出現不可靠的問題,暗示著當前的科技範式很難使用戶在未來擺脫指令敏感度這個問題。
更令人吃驚的是,研究團隊發現,一些平均表現最好的提示詞格式實際上會因任務難度的不同而表現得更差。
例如,用戶可能誤以為某些提示詞效果出色,因為它們在處理複雜任務中表現良好,但其應對在簡單任務時卻表現不佳。
這一趨勢令人擔憂,因為這些結果表明,人類很難預測模型何時會犯錯,以判斷整個交互過程的可靠性。
這可能會引發額外的成本,以及無法滿足對高可靠性有嚴格要求的用戶需求。
該課題組還發現,在實驗完成後發佈的其他新模型也在這三個維度當中存在類似的不可靠性問題,包括:OpenAI o1 preview、o1 mini、LLaMA 3.1 405B Instruct 和 Claude 3.5 Sonnet[2]。
在分析完了三個模型不可靠性的維度之後,可以得出目前大模型和其演變的趨勢並不樂觀的結論。
因此,研究人員很想根據觀察結果,來瞭解人類監督是否可作為緩解不可靠問題的解決方案。但是,在一項廣泛的人類研究中,他們發現情況其實有所不同。
實際上,人類不善於發現模型的錯誤,而且令人驚訝的是,人們經常將不正確的模型輸出誤判為正確。
這表明人類沒有足夠的能力成為這些模型的可靠監督者,從而使大模型在高風險領域的應用變得更加複雜。
為此,該研究論文引入了一個新的評估框架,可以根據人類對任務難度的預期來更全面且穩健地評估大模型的能力和風險。
雖然上面的這部分內容在該論文中沒有太多的討論,但實際上在人工智能評估領域做出了重大貢獻。
這是因為評估人工智能系統的標準方法一直在使用側重於總分(如準確率)的基準。
然而,由於這些基準通常擁有模糊且隨機的任務難度分佈,它們無法穩健或全面地描述人工智能系統的能力和局限性,也無法提供更多關於被評估模型在未來新任務中將如何表現的見解。
後者至關重要,因為它是人工智能評估的首要目標之一。畢竟,人們想知道並預測何時何地可以安全地部署這些模型。
研究人員的方法通過描述大模型之於人類難度的能力,避開基準測試中信息量小且對任務難度分佈極為敏感的總分指標(例如正確率),從而對人工智能進行更穩健的評估。
例如,當所包含的任務實例太容易或太困難時,人工智能可以在衡量數學推理能力的基準測試中分別獲得 100% 或 0% 的分數。
這項工作始於他們在 GPT-4 紅隊的工作期間。研究團隊的目標是根據任務難度,對 GPT-4 及其前身的性能和不穩定性如何演變進行穩健地評估,分析 GPT 系列過去三年的發展趨勢。
為了確保該團隊的結果也適用於其他語言模型系列,研究人員還將 LLaMA 和 BLOOM 模型系列也納入了分析範圍。
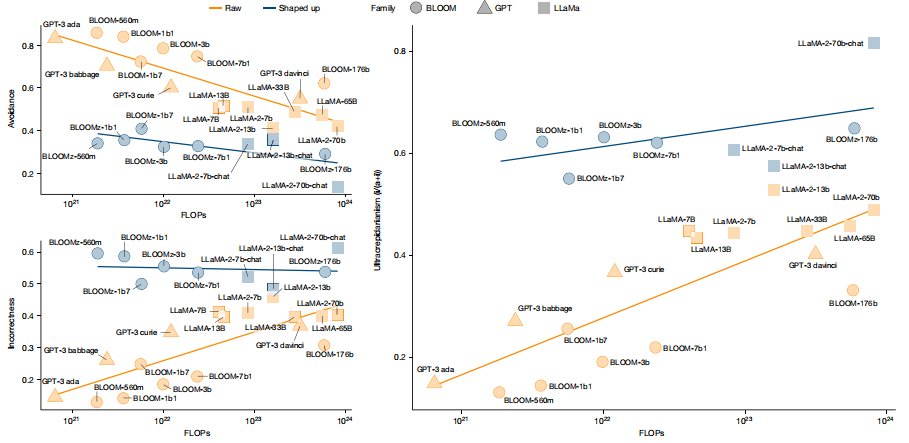 圖| LLaMA 和 BLOOM 系列以及非指導 GPT 模型的擴展分析(來源:Nature)
圖| LLaMA 和 BLOOM 系列以及非指導 GPT 模型的擴展分析(來源:Nature)隨著模型越來越大、可指導性越來越強,研究團隊對瞭解人類對任務難度的預期與大模型性能之間的差異的演變過程產生了興趣。
儘管 OpenAI 前聯合創始人兼首席科學家伊爾亞·蘇茨克維(Ilya Sutskever)曾預測這種差異會隨著時間的推移而減少,但該團隊發現事實並非如此。
正如之前他們在「新的評估框架」中提到的,加入對人類難度的考量比只關注挑戰性越來越高的任務(如基準測試所做的)更穩健、更全面,從而為瞭解模型的能力和風險提供新的視角。
儘管這項研究並沒有直接解決大模型的可靠性問題,但是通過揭示現有的「擴大模型規模和提高模型的可指導性」的方法並未能有效解決大模型可靠性和安全性的根本問題,來重新審視這個問題。
它挑戰了之前的假設,即更強大的模型自然會導致更可預測和更可靠的行為。
這表明,他們需要從根本上改變大模型的設計和評估方式,特別是對於需要高可靠性和安全性的應用。
論文具體也分析了導致模型不可靠性的若干潛在原因以及可能的解決方法:
在擴大模型方面,近年來的基準測試逐漸趨向於包含更多難度較高的示例,或者賦予所謂「權威」來源更大的權重,這使得研究人員更注重優化模型在複雜任務上的表現,從而在整體難度一致性上逐步惡化。
而在提高模型可指導性方面,有證據證明在後期塑造的方法(如強化學習與人類反饋,RLHF)中,受僱人員傾向於對迴避任務的回答給予懲罰,使得模型在面對難以解決的難題時更傾向於「編造」答案。
針對如何解決這些不可靠性,論文提出了一些可能的策略,比如可以借助人類對任務難度的預期來更有效地訓練或微調模型,或者利用任務難度和模型的自信度,引導模型在遇到超出自身能力範圍的問題時更加謹慎地應對。
參考資料:
1. Zhou, L., Schellaert, W., Martínez-Plumed, F. et al. Larger and more instructable language models become less reliable.Nature 634, 61–68 (2024). https://doi.org/10.1038/s41586-024-07930-y
2. https://x.com/lexin_zhou/status/1838961179936293098.
運營/排版:何晨龍