AI造芯Nature論文遭圍攻,Google發文硬剛學術抹黑,Jeff Dean怒懟:你們連模型都沒訓
登上了Nature的「超人」芯片設計系統AlphaChip,卻多次遭到質疑。
而且不是簡單說說而已,做實驗、寫論文,還有一篇作為invited paper發在ISPD 2023。
AlphaFold都拿諾獎了,AlphaChip還擱這闢謠呢?
怎麼辦?Google首席科學家Jeff Dean表示:我也寫篇論文!

EDA社區一直對我們的AlphaChip方法是否像Nature論文中聲稱的那樣有效持懷疑態度。annadgoldie、Azaliamirh和我寫了個論文,來回應這些問題:
 論文地址:https://arxiv.org/pdf/2411.10053
論文地址:https://arxiv.org/pdf/2411.10053Jeff Dean認為,這種毫無根據的懷疑,在很大程度上是由下面這篇文章(「一篇存在嚴重缺陷的未經同行評審的論文」)導致的:
 論文地址:https://arxiv.org/pdf/2302.11014
論文地址:https://arxiv.org/pdf/2302.11014該論文聲稱複製了我們的方法,但未能在主要方面遵循:
作者沒有進行預訓練(儘管在我們的Nature文章中提到了37次預訓練 ),剝奪了基於學習的方法從其他芯片設計中學習的能力;
減少了20倍的計算量,並且沒有進行收斂訓練。
這就像評估一個以前從未見過圍棋的AlphaGo,然後得出結論,AlphaGo不太擅長圍棋。
Jeff Dean等人還回應了Igor Markov(Synopsys的傑出架構師)在 CACM 2024年11月刊上發表的分析文章。

論文地址:https://cacm.acm.org/research/reevaluating-googles-reinforcement-learning-for-ic-macro-placement/

Jeff Dean表示,Markov發論文時妹說自己是Synopsys的高級員工,——Synopsys是商業EDA軟件,而AlphaChip是開源的。
Markov的論文分析中還引用了另一篇沒發表的匿名PDF:

https://statmodeling.stat.columbia.edu/wp-content/uploads/2022/05/MLcontra.pdf
這實際上也是Markov寫的。
Markov的文章提出了隱晦的指控,所有這些都是完全沒有根據的,而且已經被Nature證明過了。
我很驚訝Synopsys想與此扯上關係,我很驚訝CACMmag認為有必要在沒有證據的情況下發表這類指控,
除了兩篇有缺陷的、未經同行評審的文章之外,沒有任何技術數據。
Google的回擊
話說在arxiv上吃瓜,小編還是第一次。
在Introduction部分,Google拉了個時間表:
2020年4月:發佈Nature論文的arXiv預印本。
2020年8月:TPU v5e中流片了10個AlphaChip佈局。
2021年6月:發表了Nature文章。
2021年9月:在TPU v5p中流片了15個AlphaChip佈局。
2022年1月 – 2022年7月:開源了AlphaChip,Google的另一個團隊獨立複製了Nature論文中的結果。
2022年2月:Google內部獨立委員會拒絕發表Markov等人的觀點,因為數據不支持其主張和結論。
2022年10月:在Trillium(最新的公共TPU)中流片了25個AlphaChip佈局。
2023年2月:Cheng等人在arXiv上發帖,聲稱對我們的方法進行了「大規模重新實現」。
2023年6月:Markov發佈了他的「meta-analysis」。
2023年9月:Nature啟動了第二次同行評審。
2024年3月:Google Axion處理器(基於ARM的CPU)採用了7個AlphaChip佈局。
2024年4月:Nature完成了調查和出版後審查,發現完全對我們有利。
2024年9月:MediaTek高級副總裁宣佈擴展AlphaChip以加速其最先進芯片的開發。
2024年11月:Markov重新發表了他的「meta-analysis」。
簡單來說,我AlphaChip已經在自家服役這麼長時間了,聯發科也用了,Nature也調查過了,無懈可擊。
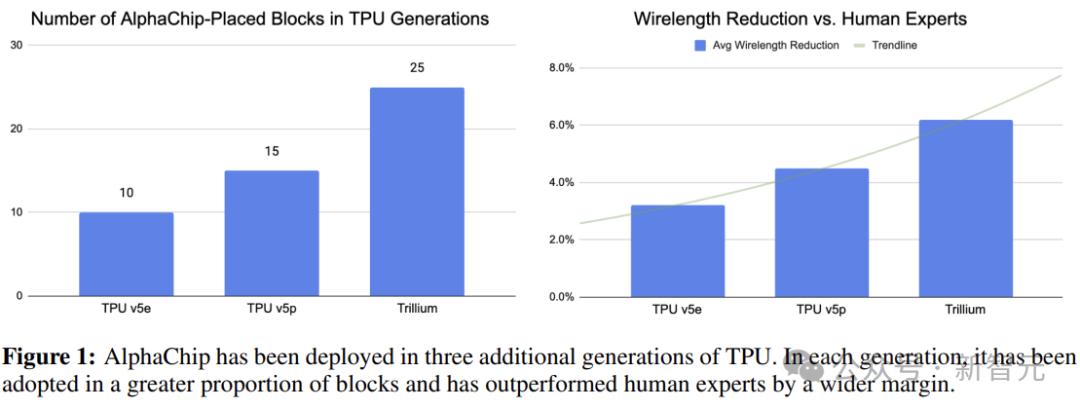
而且作為不同的部門,TPU團隊需要足夠的信任才會使用AlphaChip(優於人類專家、高效且可靠),他們不能承擔不必要的風險。
對於反方的Markov,論文評價道:「Markov的大部分批評都是這種形式:在他看來,我們的方法不應該奏效,因此它一定不起作用,任何表明相反的證據都是欺詐。」
說到欺詐這件事,正反方都談到了內部舉報人(whistle-
blower),在Markov的文章中是這樣記載的:
論文的兩位主要作者抱怨他們的研究中不斷出現欺詐指控。2022 年,Google解僱了內部舉報人,並拒絕批準出版Google研究人員撰寫的一篇批評Mirhoseini等人的論文,舉報人起訴Google不當解僱(根據加州舉報人保護法)。
而本文表示:這位舉報人向Google調查員承認,他懷疑這項研究是欺詐性的,但沒有證據。
對錯誤論文的逐條回應
沒有預先訓練RL方法
與以前的方法不同,AlphaChip是一種基於學習的方法,這意味著它會隨著解決更多的芯片放置問題而變得更好、更快。
這是通過預訓練實現的,如下圖2所示,訓練數據集越大,放置新區塊的方法就越好。
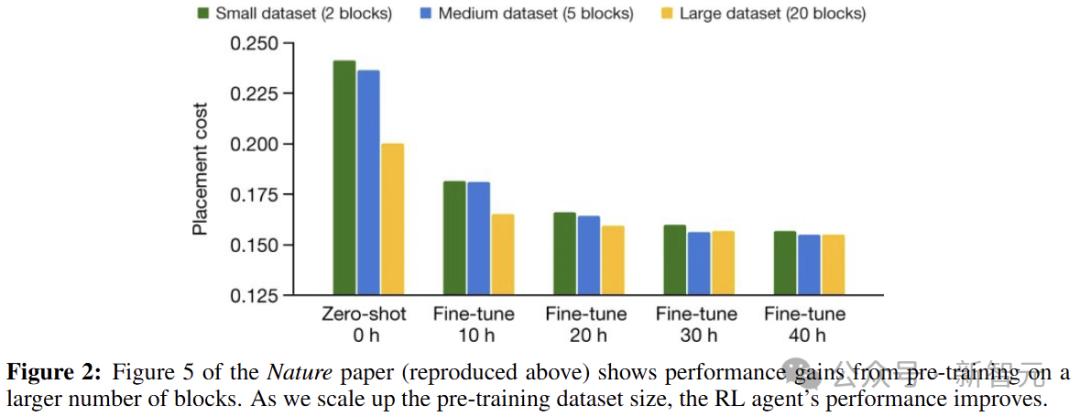
相反,Cheng等人根本沒有進行預訓練(沒有訓練數據),這意味著模型以前從未見過芯片,必須學習如何從頭開始為每個測試用例執行佈局。
作者在Nature論文中詳細討論了預訓練的重要性,並實證證明了它的影響。例如下圖3表明,預訓練可以提高放置質量和收斂速度。
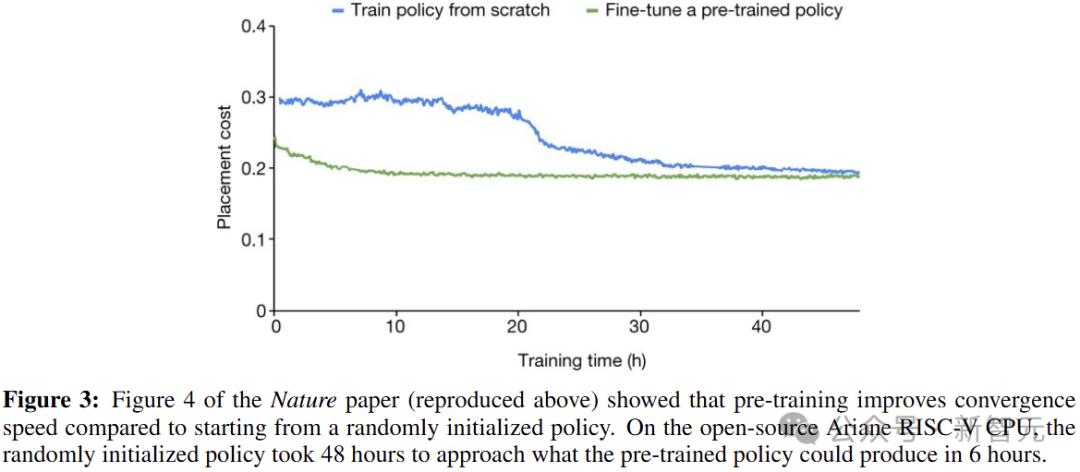
在開源的Ariane RISC-V CPU上,非預訓練的RL需要48小時,才能接近預先訓練模型在6小時內可以產生的值。
在Nature論文中,作者針對主數據表中的結果進行了48小時的預訓練,而Cheng等人預訓練了 0 小時。
「Cheng試圖通過暗示我們的開源存儲庫不支持預訓練,來為他們缺乏預訓練找藉口,但這是不正確的,預訓練就是在多個樣本上運行方法。」
使用的計算資源減少了一個數量級
在Cheng等人的論文中,RL方法提供的RL體驗收集器減少了20倍(26個對比512個),GPU數量減少了一半(8個對比16個)。
使用較少的計算可能會損害性能,或者需要運行相當長的時間才能實現相同的性能。
如下圖4所示,在大量GPU上進行訓練可以加快收斂速度並產生更好的最終質量。
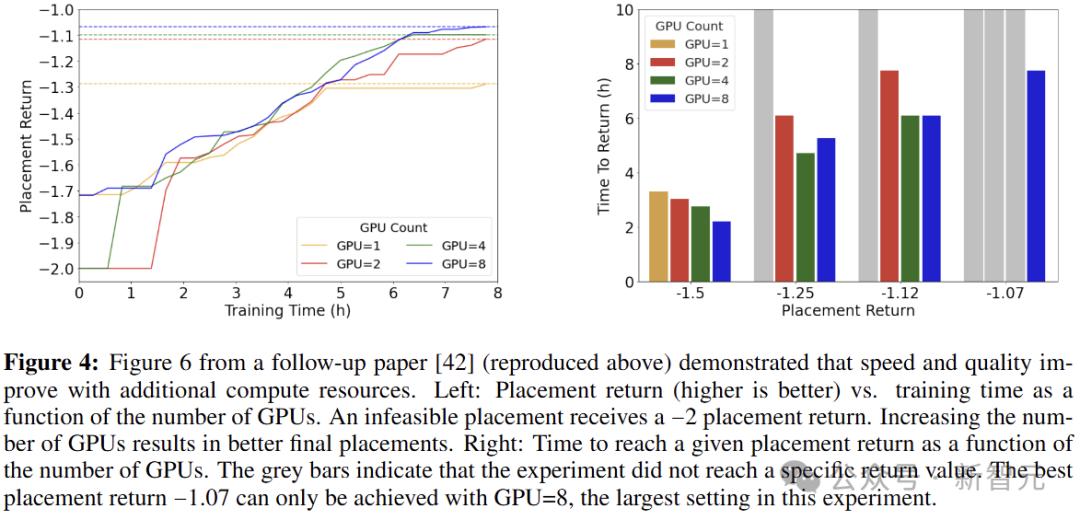
RL方法未訓練到收斂
隨著機器學習模型的訓練,損失通常會減少,然後趨於平穩,這代表「收斂」——模型已經瞭解了它正在執行的任務。
眾所周知,訓練到收斂是機器學習的標準做法。
但如下圖所示,Cheng等人沒有為任何一個進行收斂訓練,
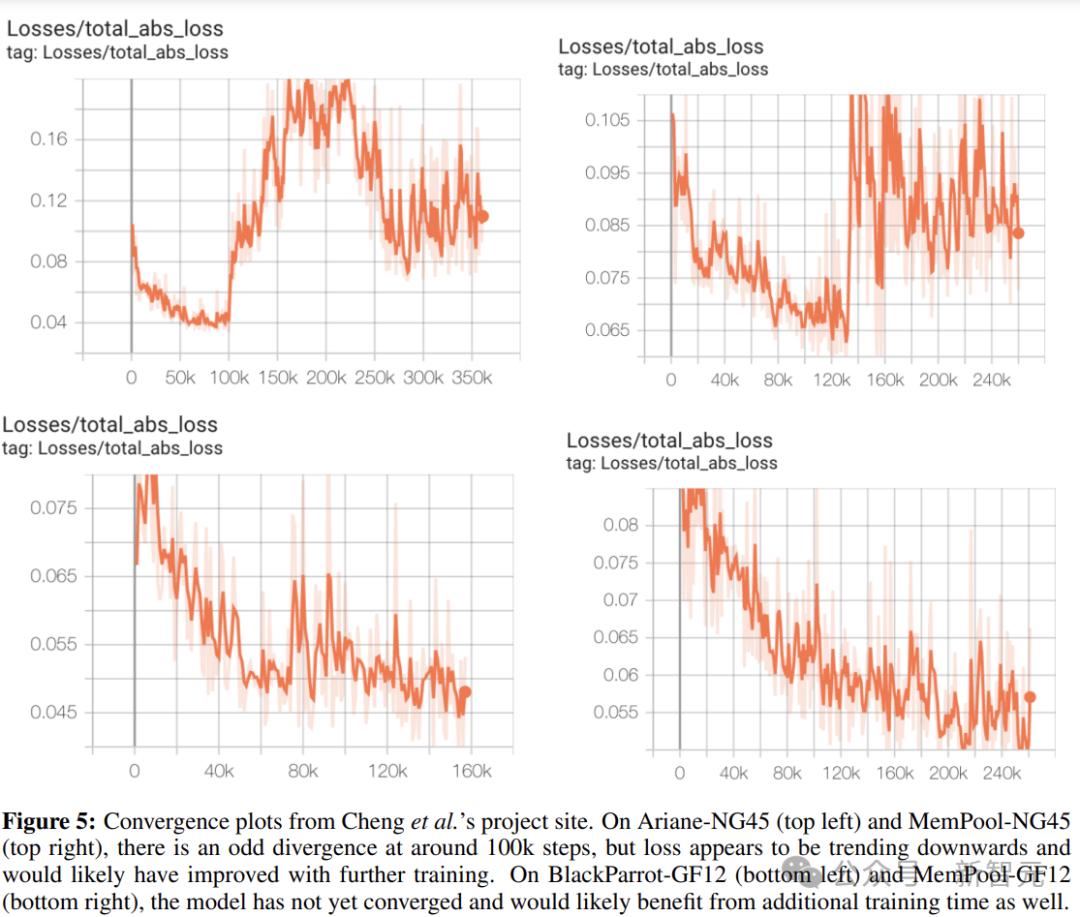
下表總結了詳細信息。除了沒有提供圖的BlackParrotNG45和Ariane-NG45,其他四個具有收斂圖的塊(Ariane-GF12、MemPool-NG45、BlackParrot-GF12 和 MemPool-GF12),訓練在相對較低的步數(分別為 350k、250k、160k 和 250k 步)處截止。
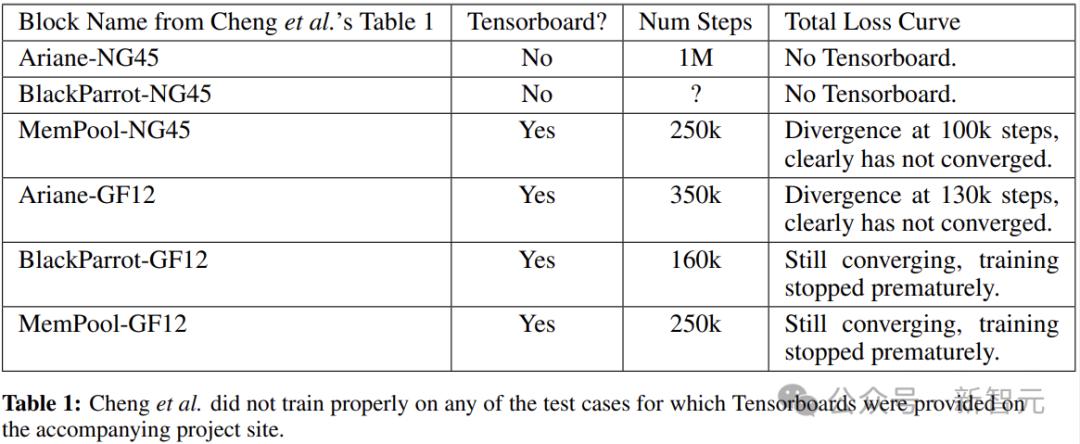
如果遵循標準的機器學習實踐,可能會提高這些測試用例的性能。
不具代表性、不可重現
在Nature論文中,作者報告的張量處理單元(TPU)塊的結果來自低於7nm的技術節點,這是現代芯片的標準製程。
相比之下,Cheng等人採用了舊技術節點尺寸45nm和12nm)的結果,這從物理設計的角度來看有很大不同。
例如,在低於10nm時,通常使用multiple patterning,導致在較低密度下出現布線擁塞問題。因此,對於較舊的技術節點大小,AlphaChip可能會受益於調整其獎勵函數的擁塞或密度份量。
AlphaChip的所有工作都是在7nm、5nm和更新的工藝上進行的,作者沒有專注於將其應用於舊工藝製程的設計。
此外,Cheng等人也無法或不願意分享在其主數據表中複製結果所需的綜合網表。
參考資料:
https://x.com/JeffDean/status/1858540085794451906
本文來自微信公眾號「新智元」,作者:新智元,編輯:alan,36氪經授權發佈。