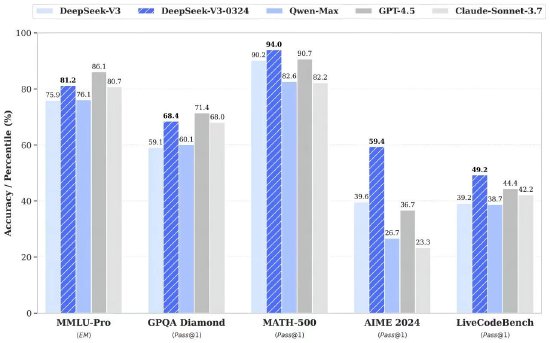
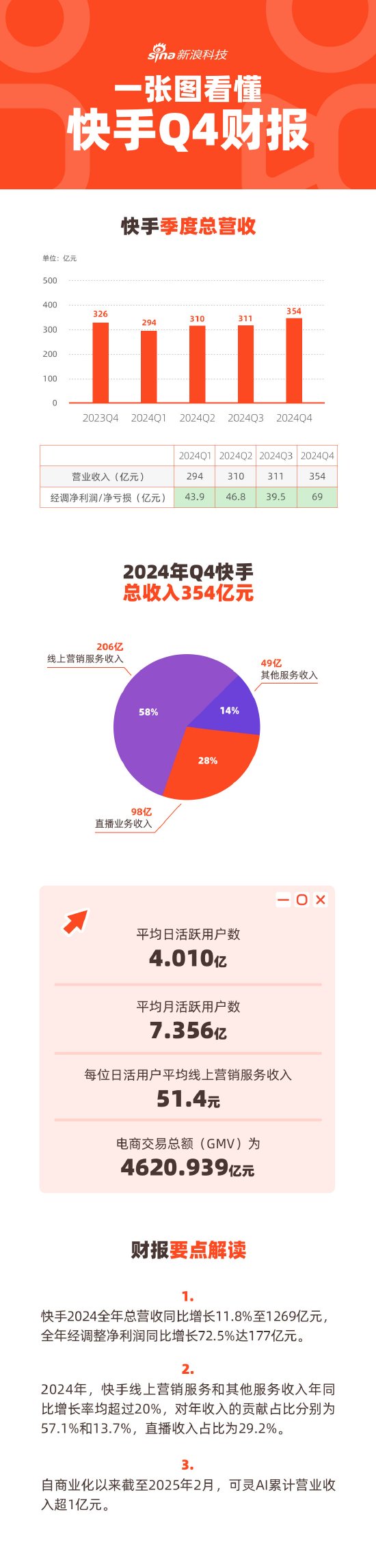
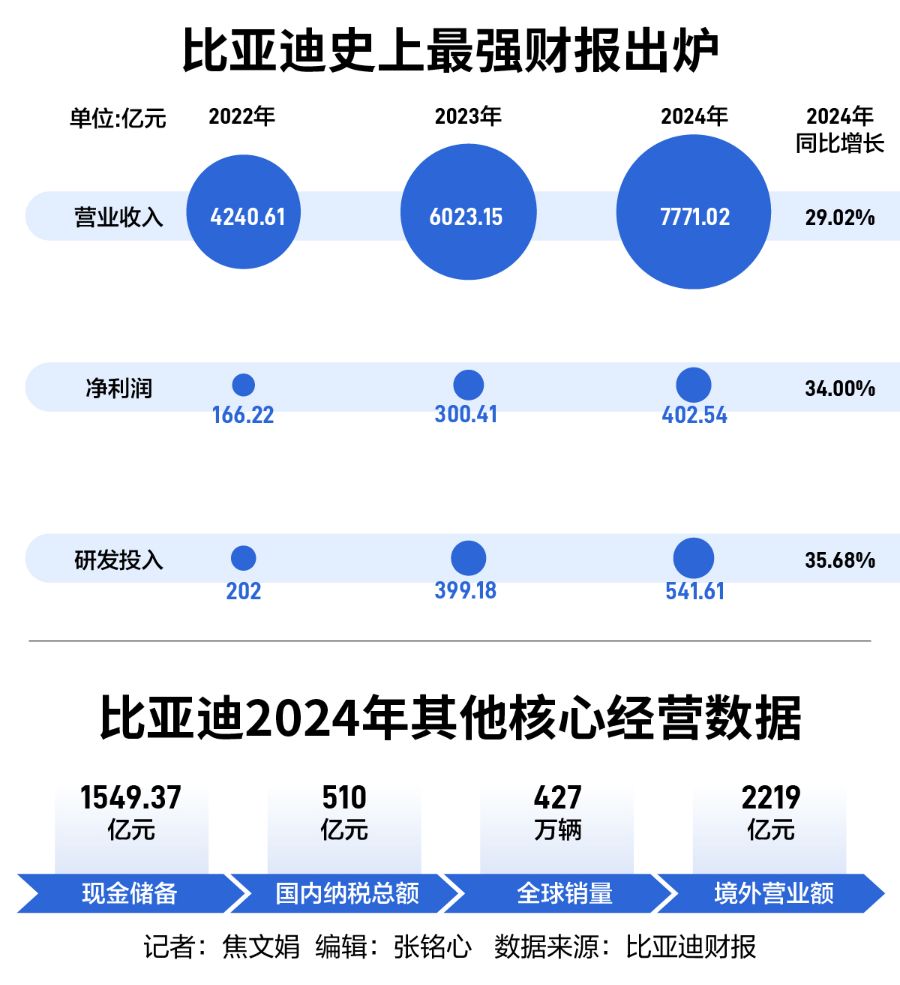
「注意力實際上是對數的」?七年前的Transformer還有新發現,Karpathy點讚
選自 supaiku.com
作者:Spike Doanz
機器之心編譯
「注意力實際上是對數的」?今天,一篇博客再次掀起了AI社區對注意力機制的討論。
作者認為,Transformers 中實現的注意力機制,在計算複雜度上應該被視為對數級別的。
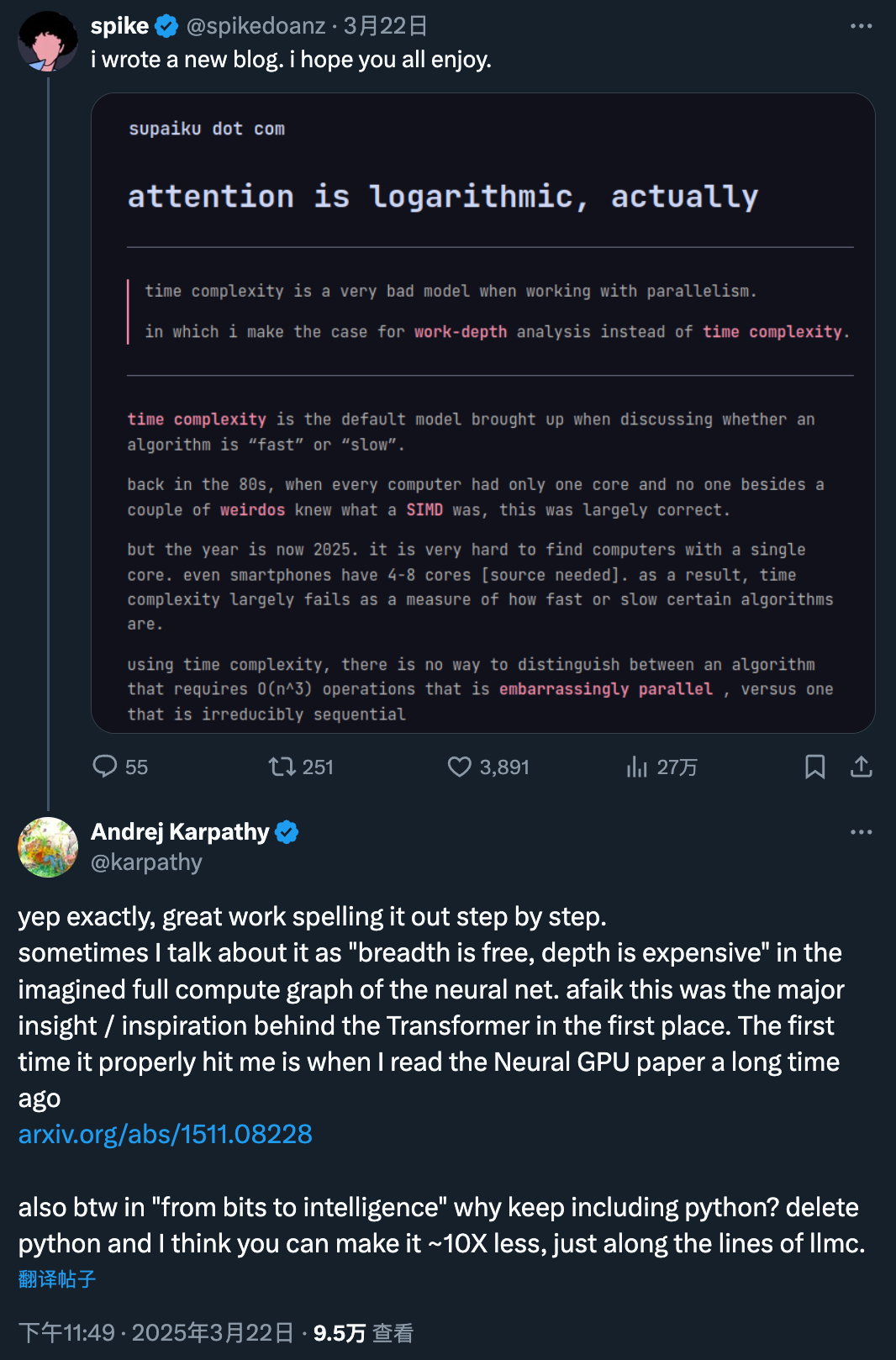
這篇博客,還得到了 Karpathy 的高度肯定:
有時我會在想像中的神經網絡完整計算圖中將其描述為「廣度是免費的,深度是昂貴的」。
據我所知,這首先是 Transformer 背後的主要見解 / 靈感。我第一次真正受到它的震撼是在很久以前我讀到 Neural GPU 論文的時候(https://arxiv.org/abs/1511.08228)。
另外,在「從比特到智能」中為什麼還要包含 python?刪除 python,我認為你可以將其減少約 10 倍,就像 llmc 一樣。
我們知道,標準的注意力機制(如 Transformer 中的自注意力)計算步驟如下:
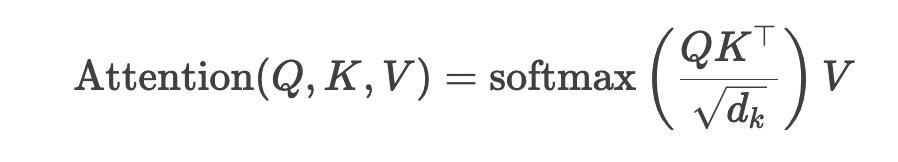
其複雜度主要來源於:
-
點積計算:QK^⊤ 的矩陣乘法,複雜度為 O (n^2d),其中 n 是序列長度,d 是特徵維度。
-
Softmax 歸一化:對每個位置的注意力權重進行歸一化,複雜度為 O (n^2)。
一般來說,研究者認為總複雜度隨著序列長度 n 呈平方增長,這也是標準 Transformer 難以處理長序列的核心瓶頸。
而這篇博客,卻提出了另外一個全新的視角。
關於如何理解這一觀點,我們看看博客內容便知。
-
博客鏈接:https://supaiku.com/attention-is-logarithmic
以下是博客內容:
時間複雜度是衡量算法快慢最常用的標準。在 20 世紀 80 年代,那時候計算機大多隻有一個核心,大家還不知道什麼是單指令多數據(SIMD)技術,所以用時間複雜度來評估算法基本是合理的。
但現在是 2025 年,單核計算機已經很少見了,就連智能手機都有 4 到 8 個核心。在這種情況下,只用時間複雜度來衡量算法的快慢就不夠全面了。
舉個例子來說,一個時間複雜度為 O (n³) 但能夠並行的算法,和一個必須按順序執行的算法,單從時間複雜度上看不出來它們的區別。而且,有些算法天生就是並行的,比如線性代數,但人們還在用時間複雜度來描述它們,這其實是很荒謬的。
我們需要一種更好的方式來衡量算法的複雜度。「work-depth 模型」分析提供了一個很好的思路。它不僅關注輸入大小對應的操作數量,還能從理論下限的角度思考算法的複雜度。
我們不僅要考慮算法執行的原始操作數量(即「work」),更要關注計算圖相對於輸入大小的「depth」,也就是不可並行的順序操作的最小數量。因為這些順序操作是不可避免的,無論你的計算機有多少個核心,它們都會造成阻塞。
我主要研究機器學習系統的性能工程,所以接下來我會重點討論適用於張量的算法。「work-depth 模型」雖然不完美,但很有用。
在此,我先拋出一個問題:逐個元素相乘的時間複雜度是多少?從這個問題出發,我會進一步闡述我的觀點:Transformers 中實現的注意力機制,在計算複雜度上應該被視為對數級別的。
案例 1:逐個元素相乘
給定兩個長度相同的向量 a 和 b,逐個元素相乘是將 a 中的每個元素與 b 中對應索引位置的元素相乘,並將結果存儲在新向量 c 中(或者直接在原位置修改)。
代碼如下:
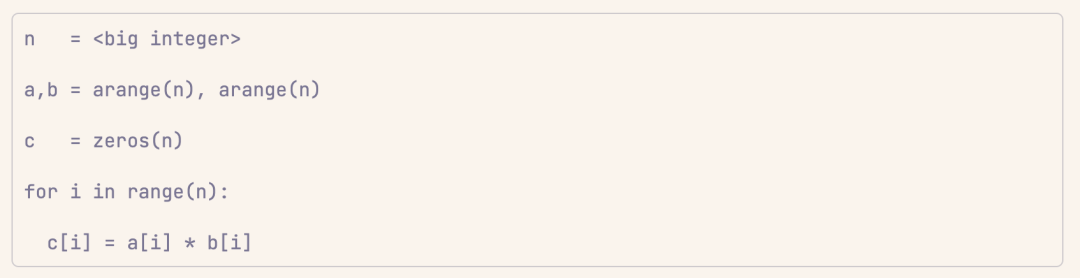
從時間複雜度的角度看,這好像是線性的。如果用單線程來跑,那確實就是線性的。
然而,如果仔細觀察,你會發現在這個問題的計算圖中,range (n) 中的各個步驟之間沒有依賴關係。它們完全獨立。那麼為什麼不併行執行它們呢?
這正是每個線性代數 / 張量庫在底層所做的事情。
你很快會發現,逐個元素相乘實際上根本不是線性時間的!它實際上看起來像是常數時間,直到達到一個神秘的臨界點。
具體來說,我們可以分析逐個元素相乘時的「work」和「depth」:

算法里的每一步操作,比如加載數據、做乘法、存儲,這些操作本身都不複雜,理論上只需要常數時間就能完成。只要你的計算機有足夠的並行計算能力,直到某個臨界點,這些操作的時間複雜度都是常數時間。
案例 2:向量求和
向量求和比相乘更複雜一些。在這裏,我們可以清楚地看到兩個步驟之間存在依賴關係(因為累加需要調用 c 的狀態)。這無法完全並行執行。
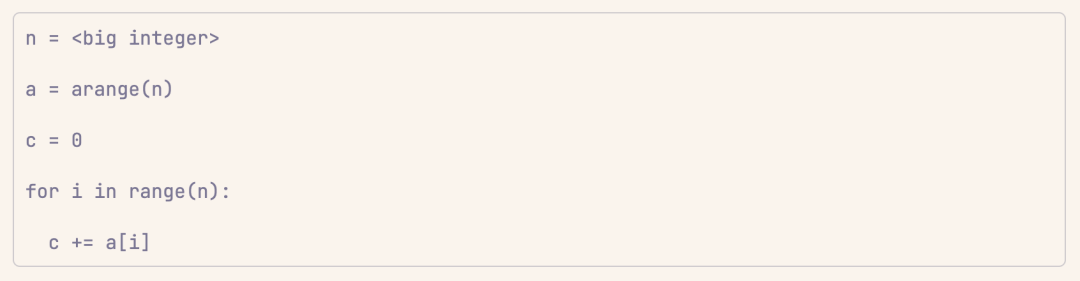
不過,向量求和看起來好像每一步都得依賴前一步,但仔細想想,不難發現它只是每兩個步驟(或者說每對元素)之間有點關聯。
實際上,這個操作仍然可以並行化,方法是不在一個步驟中並行執行每個操作,而是在一個步驟中對每隊執行操作。
舉個例子,假設你有一個長度為 n 的列表,向量加法是這樣的:
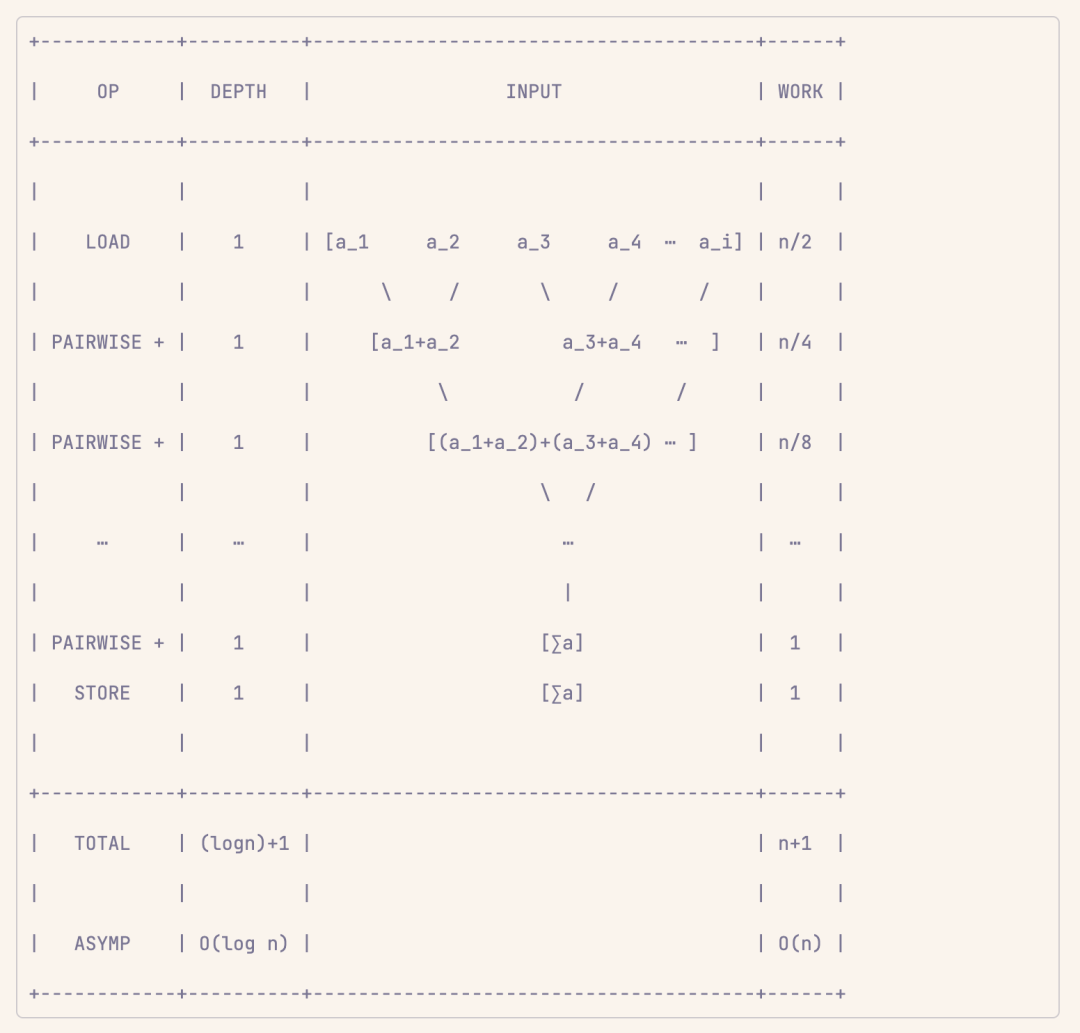
1. 先把列表裡每一對相鄰的數字(比如第 1 個和第 2 個、第 3 個和第 4 個……)加起來。因為一共有 n 個數字,所以會有 n/2 對。把每對的結果存到其中一個位置(比如偶數位置或者奇數位置)。
2. 再把上一步得到的每一對結果(現在每對是之前兩對的和)再加起來。這次會有 n/4 對。
3. 每次都是把上一步的結果兩兩相加,直到最後只剩下一個數字。這個數字就是整個列表所有數字的總和。
這樣一來,每次操作的步驟數量都會減半。比如,第一次是 n/2 對,第二次是 n/4 對,以此類推,總共只需要 log₂(n) 步就能把所有數字加起來。
案例 3:張量積

張量積是一個基本操作。它獲取兩個張量的所有索引,並對所有請求的索引(其中一些可能是共享的)逐個相乘。
比如,求兩個矩陣的張量積並且共享一個軸的時候,結果會是一個三維的張量。不過,這個操作其實並不複雜,因為它只需要做並行的加載、存儲、逐個相乘,所以它的「depth」是固定的,不會隨著數據量變大而增加。
但要注意,這種情況只有在張量(或者張量的一部分)能夠完整地裝進緩存的時候才成立。如果張量太大,裝不下緩存,那就會出現瓶頸,因為緩存不夠用的時候,計算機就不得不按順序處理數據,這時候「depth」就會增加。
張量積在機器學習里其實不太常被提到,但置換、求和、矩陣乘法、哈達瑪積、直積、各種批處理操作等等,所有這些操作都可以看成是某種形式的張量積,再加上某種形式的歸約(把多餘的維度去掉或者合併)。
這樣一來,能讓複雜的張量操作變得更加系統、更有數學美感,尤其是在高性能計算和分佈式系統里,用起來特別方便。
案例 4:矩陣乘法
矩陣乘法(MATMUL)就是這樣一種張量運算,它通過張量積的收縮得到了優雅的描述。
給定兩個張量分別為(i j)和(j k)的張量 A、B,張量乘法構造出一個張量 C,其元素 C [i,j,k] = A [i,j] * B [j,k],然後沿 j 維相加(收縮)成一個形狀為(i k)的矩陣 D。(為了提高效率,C 通常不會完全實體化,而是在張量積的碎片之間進行收縮融合)。
只需忽略外軸,就可以對矩陣進行批處理 / 廣播。

底層內容的偽代碼:

注意,這隻是將 TENSOR 順序組合成 CONTRACT,其深度複雜度分別為 O (1) 和 O (logn):

案例 5:softmax
softmax 一點也不特別。先按元素應用 e^x,然後收縮,最後按元素除法。
下面照例進行深度複雜性分析:
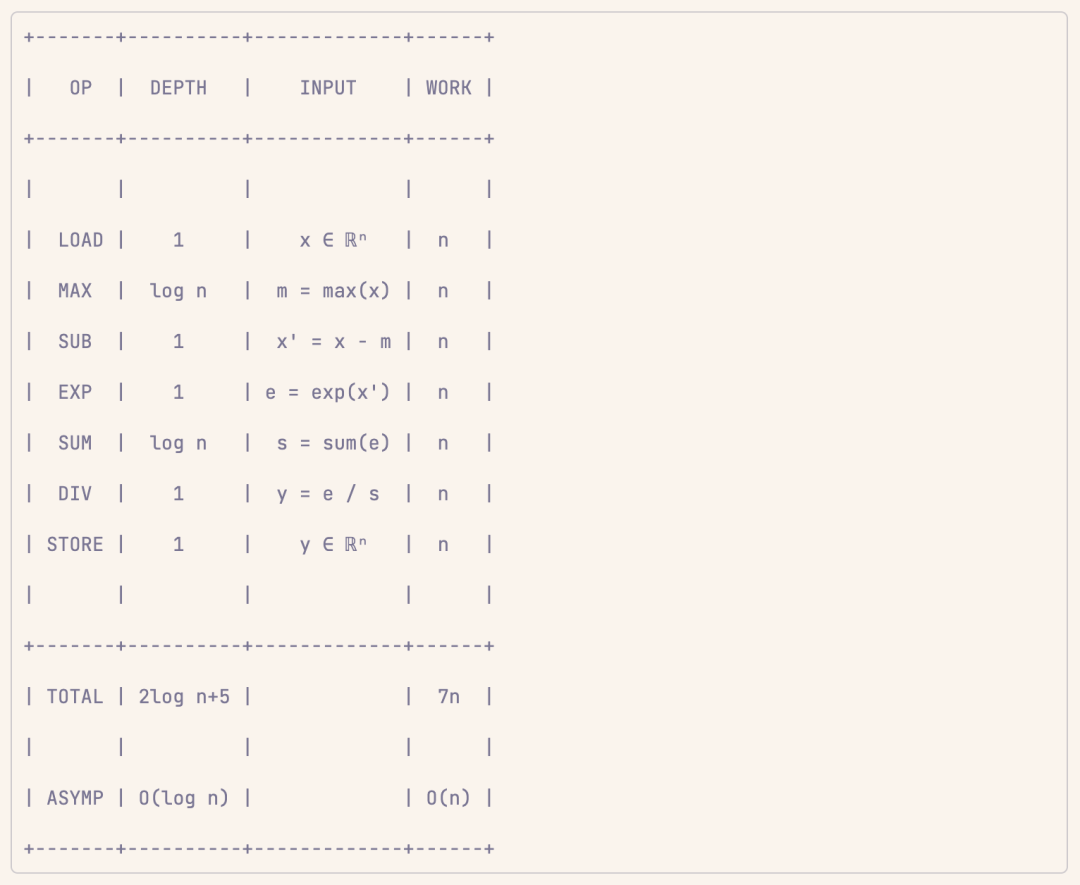
案例 6:注意力
注意力就不用多說了。以下是深度分析:

可以看到,通過整數個 matmuls 收縮和一系列元素單義操作的順序組合,注意力的漸近深度複雜度僅為 O(logn + logd),其中 n 和 d 分別為序列長度和嵌入維數。
實際上,這通常意味著 O(log sequence_length),因為 sequence_length 通常遠大於 embedding_dim。
局限性
然而,深度分析並不完美,當考慮到內存訪問模式和高速緩存的友好性時,問題立即顯現出來。
特別是,當出現以下情況時,該模型就會失效:
-
樹的最大寬度 >> 計算單元(不管是什麼內核)。
-
內存訪問模式不連續 / 不可矢量化?
-
物化變量與內存層次結構不匹配。
在實踐中,這主要意味著物化張量的大小必須保持在 L2- 左右的緩存範圍內,深度複雜度邊界才能成立。
那麼為什麼注意力不是對數的呢?
事實上,由於注意力至少需要將 QK^T 部分實體化(通常是非常大的整數,非常大的整數),這幾乎肯定會溢出二級緩存(這要麼迫使你在內存中計算的速度慢於 OOM,要麼迫使你通過將 QK^T 矩陣分片為部分關聯塊並傳入 softmax 來將其轉化為順序問題)。
這就意味著,對於普通計算機而言,注意力的深度複雜度更像是 O (n log n)。雖然這絕不是一個不可還原的問題,但我在下一節中會提出一些推測性的解決方案。
對未來計算的猜測?
那麼,這對目前的芯片和未來的芯片意味著什麼?
我認為這意味著很多,前提是一個關鍵事實,即訓練範式在很大程度上仍然是非併發的(即看起來像循環上的前向→後向傳遞,或 dualpipe 之類的混合),為什麼?
因為如果是這種情況,那麼神經網絡的權重(在 nn 次循環中佔運動操作量的大部分)在很大程度上就是靜態的,而且計算單元的局部性會越來越強。
我們已經看到這種情況的發生。權重曾經被卸載到磁盤或保存到內存中,只有在專門的內核中才會啟動到 GPU。
後來,每個人和他們的祖母都開始完全使用設備內存(VRAM 或 HBM)進行訓練。
現在,芯片製造商已經意識到,通過將權重轉移到更快的內存(如 L2)上,他們可以獲得另一個 OOM(在深度複雜性分析失敗的地方有效地砍掉整個部分)。