Meta發佈最強開源Llama 4,超越DeepSeek V3
原生多模態Llama 4終於問世,開源王座一夜易主!首批共有兩款模型Scout和Maverick,前者業界首款支持1000萬上下文單H100可跑,後者更是一舉擊敗了DeepSeek V3。目前,2萬億參數巨獸還在訓練中。
Llama 4重磅發佈了!

Meta官宣開源首個原生多模態Llama 4,首次採用的MoE架構,支持12種語言,首批發佈一共兩款:
Llama 4 Scout:共有1090億參數,17B活躍參數,16個專家,1000萬上下
Llama 4 Maverick:共有4000億參數,17B活躍參數,128個專家,100萬上下文
另外,2萬億參數Llama 4 Behemoth將在未來幾個月面世,288B活躍參數,16個專家。

Llama 4的橫空出世,成為迄今為止開源最強,多模態能力最好的模型之一。

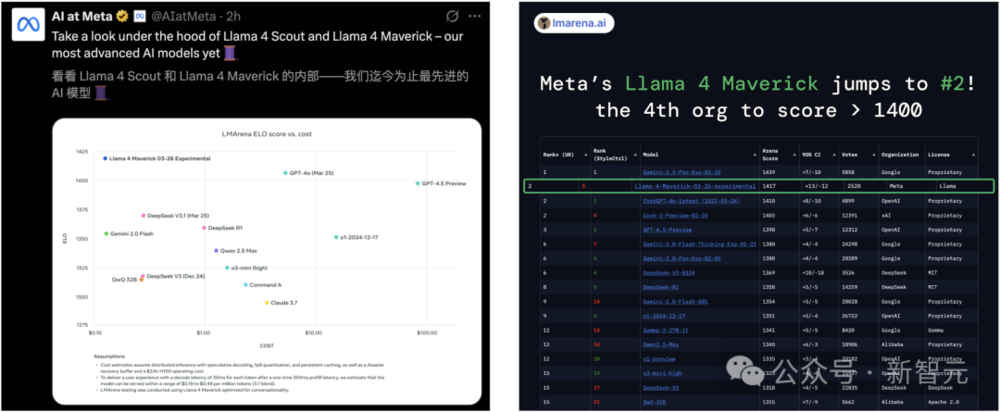
在大模型LMSYS排行榜上,Llama 4 Maverick衝上第二( ELO得分1417),僅次於閉源Gemini 2.5 Pro。
更值得一提的是,僅用一半參數,Maverick推理編碼能力與DeepSeek-v3-0324實力相當。
Llama 4 Scout最大亮點在於支持1000萬上下文,相當於可以處理20+小時的影片,僅在單個H100 GPU(Int4 量化後)上就能跑。
在基準測試中,性能超越Gemma 3、Gemini 2.0 Flash-Lite、Mistral 3.1。
即將面世的Llama 4 Behemoth(仍在訓練中),是Maverick協同蒸餾的教師模型,使用30T多模態token在32K個GPU上進行預訓練(FP8)。
目前在STEM基準測試中,超越了GPT-4.5、Claude Sonnet 3.7、Gemini 2.0 Pro。

小紮激動地在官宣影片中稱,「今天(4月5日)是Llama 4日」!
Llama 4開源後,DeepSeek R2還遠嗎?
 此前報導稱,DeepSeek R2最晚在5發佈,看來可能要提前了……
此前報導稱,DeepSeek R2最晚在5發佈,看來可能要提前了……史上最強Llama 4開源,超越DeepSeek V3
Llama 4模型開源,標誌著Llama生態系統進入了一個新紀元。
 即日起,所有開發者可以在llama.com和Hugging Face下載這兩款最新的模型
即日起,所有開發者可以在llama.com和Hugging Face下載這兩款最新的模型在大模型排行榜中,Llama 4 Maverick在硬提示(hard prompt)、編程、數學、創意寫作、長查詢和多輪對話中,並列第一。
僅在樣式控制下,排名第五。
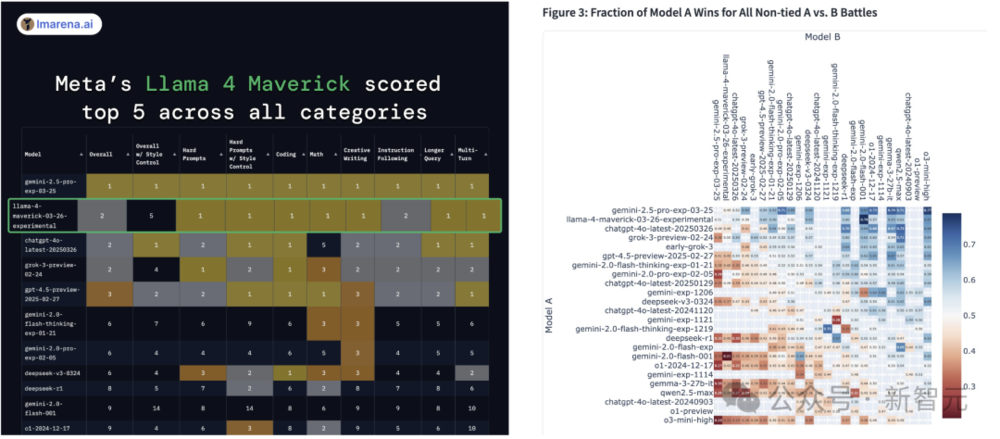
而且,1000萬上下文Llama 4 Scout還擊敗了OpenAI的模型。
每個人還可以在WhatsApp、Messenger、Instagram Direct和網頁上體驗基於Llama 4的應用。
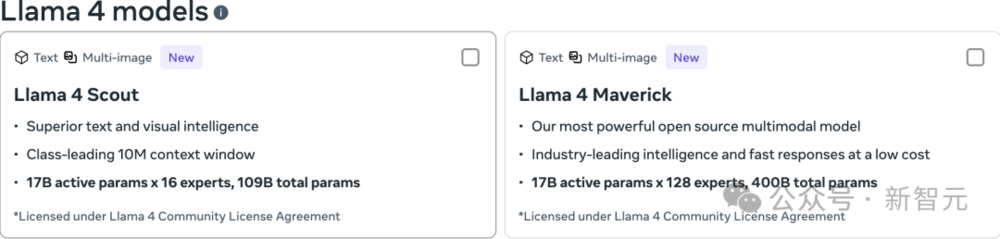
首次採用MoE,單個H100即可跑
Llama團隊設計了兩款高效的Llama 4系列模型,只要單個H100 GPU就能運行:
一個是Llama 4 Scout(擁有170億個活躍參數和16個專家),使用Int4量化可以在單個H100 GPU上運行;
另一個是Llama 4 Maverick(擁有170億個活躍參數和128個專家),可以在單個H100主機上運行。
目前,正在訓練的教師模型——Llama 4 Behemoth,它在STEM基準測試(如MATH-500和GPQA Diamond)中,性能優於GPT-4.5、Claude Sonnet 3.7、Gemini 2.0 Pro。
在最新博文中,Meta分享了更多的關於Llama 4家族訓練的技術細節。
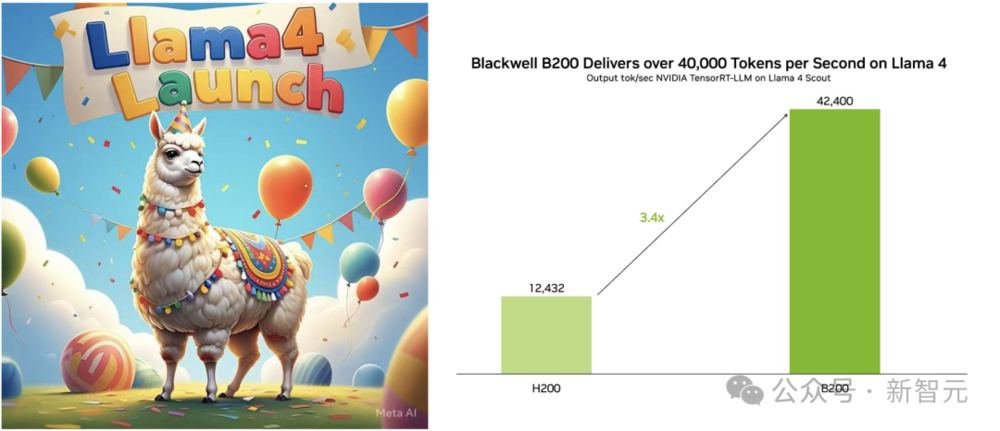 在英偉達B200上,Llama 4可以每秒處理42400個token
在英偉達B200上,Llama 4可以每秒處理42400個token1. 預訓練
Llama 4模型是Llama系列模型中首批採用混合專家(MoE)架構的模型。
在MoE模型中,單獨的token只會激活全部參數中的一小部分。
與傳統的稠密模型相比,MoE架構在訓練和推理時的計算效率更高,並且在相同的訓練FLOPs預算下,能夠生成更高質量的結果。
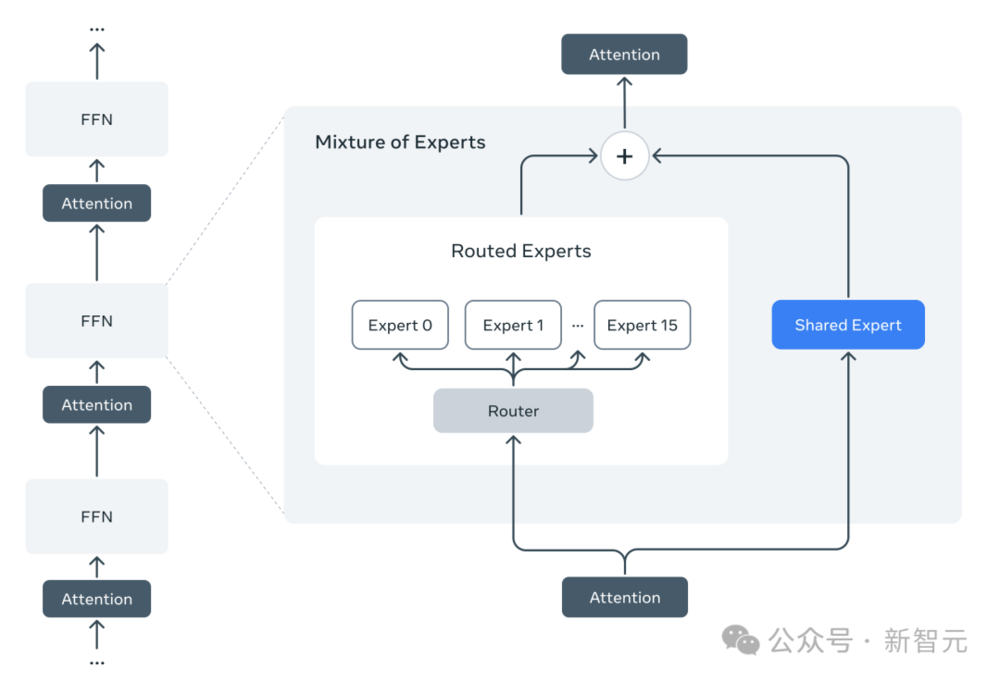 架構概覽,右為混合專家(MoE)架構
架構概覽,右為混合專家(MoE)架構舉個例子,Llama 4 Maverick模型的4000億個總參數中有170億個活躍參數。
為了提高推理效率,Meta交替使用了稠密層和專家混合(MoE)層。
MoE層用到了128個路由專家和一個共享專家。每個token都會被送到共享專家,同時也會送到128個路由專家中的一個。
因此,雖然所有參數都存儲在內存中,但在運行這些模型時,只有部分參數會被激活。
這樣就能提升推理效率,降低模型服務的成本和延遲:
Llama 4 Maverick可以輕鬆部署在一台NVIDIA H100 DGX主機上運行,或者通過分佈式推理來實現最高效率。
原生多模態設計
Llama 4是一個原生多模態模型,採用了早期融合技術,能把文本和視覺token無縫整合到一個統一的模型框架里。
早期融合是個大進步,因為它可以用海量的無標籤文本、圖片和影片數據一起來預訓練模型。
Meta還升級了Llama 4的視覺編碼器。這個編碼器基於MetaCLIP,但在訓練時跟一個凍結的Llama模型分開進行,這樣能更好地調整編碼器,讓它更好地適配大語言模型(LLM)。
模型超參數優化
Meta還開發了一種叫做MetaP的新訓練方法,能讓他們更可靠地設置關鍵的模型超參數,比如每層的學習率和初始化規模。
這些精心挑選的超參數在不同的批大小、模型寬度、深度和訓練token量上都能很好地適配。
Llama 4通過在200種語言上預訓練實現了對開源微調的支持,其中超過10億個token的語言有100多種,整體多語言token量比Llama 3多出10倍。
高效的模型訓練,解鎖1000萬輸入上下文長度。
此外,Meta注重高效的模型訓練,採用了FP8精度,既不犧牲質量,又能保證模型的高FLOPs利用率:
在使用FP8精度和32K個GPU預訓練Llama 4 Behemoth模型時,達到了每個GPU 390 TFLOPs的性能。
訓練用的整體數據包含了超過30萬億個 token,比Llama 3的預訓練數據量翻了一倍還多,涵蓋了文本、圖片和影片數據集。
Meta用一種叫做「中期訓練」的方式來繼續訓練模型,通過新的訓練方法,包括用專門的數據集擴展長上下文,來提升核心能力。
這不僅提高了模型的質量,還為Llama 4 Scout解鎖了領先的1000萬輸入上下文長度。
2. 後訓練
最新的模型包含了不同的參數規模,滿足各種使用場景和開發者的需求。
-
Llama 4 Maverick:參數規模較大,主要用於圖像理解和創意寫作
-
Llama 4 Scout:參數規模較小,適用多種任務,支持1000萬token上下文,全球領先。
為了讓不同模型適應不同的任務,針對多模態、超大參數規模等問題,Meta開發了一系列新的後訓練方法。
3. 主力模型Llama 4 Maverick
作為產品的核心模型,Llama 4 Maverick在圖像精準理解和創意寫作方面表現突出,特別適合通用助手、聊天類應用場景。
訓練Llama 4 Maverick模型時,最大的挑戰是保持多種輸入模式、推理能力和對話能力之間的平衡。
後訓練流程
為了訓練Llama 4,Meta重新設計了後訓練流程,採用了全新的方法:
輕量級監督微調(SFT)> 在線強化學習(RL)> 輕量級直接偏好優化(DPO)。
一個關鍵發現是,SFT和DPO可能會過度限制模型,在在線RL階段限制了探索,導致推理、編程和數學領域的準確性不理想。
為瞭解決這個問題,Meta使用Llama模型作為評判者,移除了超過50%的被標記為「簡單」的數據,並對賸餘的更難數據進行輕量級SFT。
在隨後的多模態在線RL階段,精心選擇了更難的提示,成功實現了性能的飛躍。
此外,他們還實施了持續在線RL策略,交替進行模型訓練和數據篩選,只保留中等到高難度的提示。這種策略在計算成本和準確性之間取得了很好的平衡。
最後,進行了輕量級的DPO來處理與模型響應質量相關的特殊情況,有效地在模型的智能性和對話能力之間達成了良好的平衡。
新的流程架構加上持續在線RL和自適應數據過濾,最終打造出了一個行業領先的通用聊天模型,擁有頂尖的智能和圖像理解能力。
作為一款通用的LLM,Llama 4 Maverick包含170億個活躍參數,128個專家和4000億個總參數,提供了比Llama 3.3 70B更高質量、更低價格的選擇。
Llama 4 Maverick是同類中最佳的多模態模型,在編程、推理、多語言支持、長上下文和圖像基準測試中超過了類似的模型,如GPT-4o和Gemini 2.0,甚至能與體量更大的DeepSeek v3.1在編碼和推理上競爭。

4. 通用模型Llama 4 Scout:1000萬token上下文
規模較小的Llama 4 Scout是一款通用模型,擁有170億個活躍參數、16個專家和1090億個總參數,在同類別中性能最好。
Llama 4 Scout 的支持上下文長度從 Llama 3 的12.8萬激增到行業領先的1000萬token。

這為多種應用打開了無限可能,包括多文檔摘要、大規模用戶活動解析以進行個性化任務,以及在龐大的代碼庫中進行推理。
Llama 4 Scout在預訓練和後訓練時都採用了256K的上下文長度,基礎模型具備了先進的長度泛化能力。
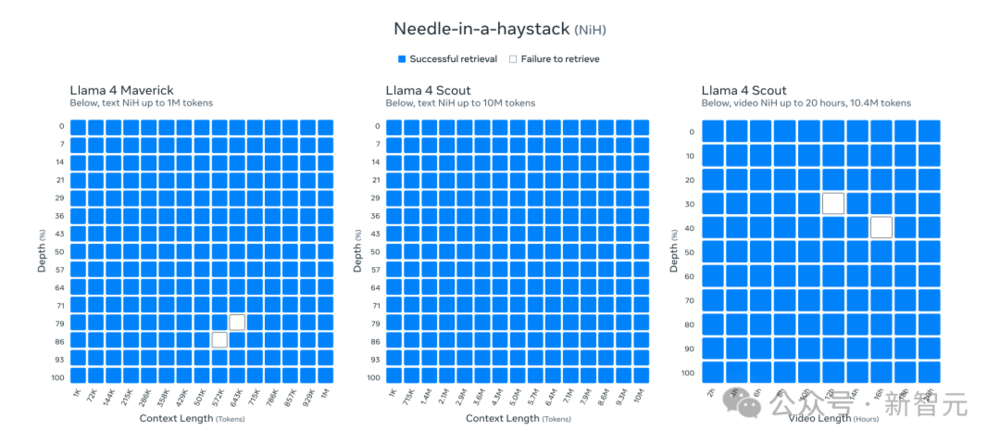
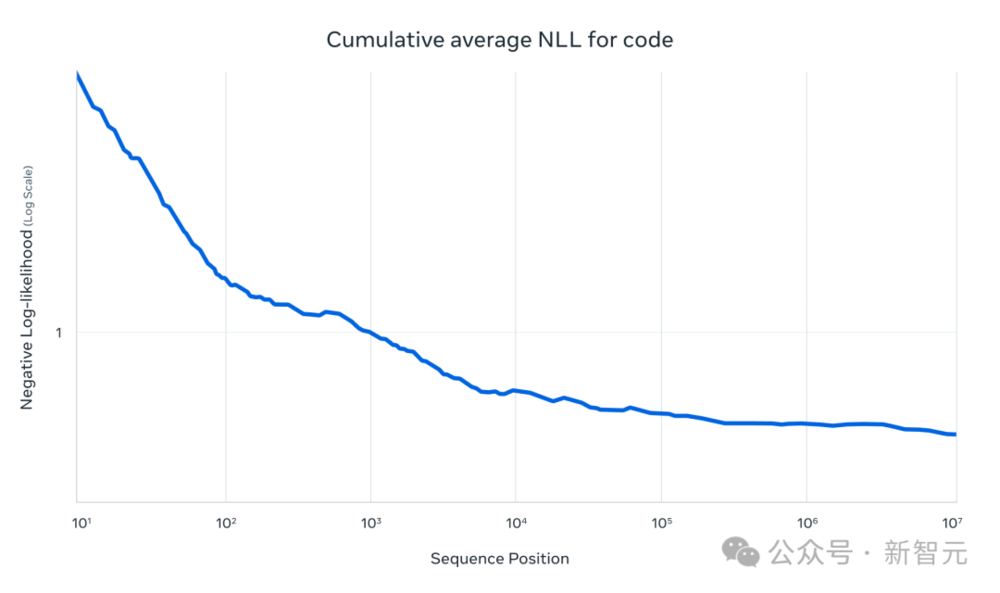
它在一些任務中取得了亮眼成果,比如文本檢索中的「大海撈針式檢索」和在1000萬token代碼上的累積負對數似然(NLLs)。
Llama 4架構的一個關鍵創新是使用了交替注意力層,而不依賴於位置嵌入。
此外,在推理時採用了溫度縮放注意力,以增強長度泛化能力。Meta將其稱為iRoPE架構,其中「i」代表「交替」(interleaved)注意力層,突出了支持「無限」上下文長度的長期目標,而「RoPE」則指的是在大多數層中使用的旋轉位置嵌入(Rotary Position Embeddings)。
5. 視覺理解能力
兩款模型進行了大規模的圖像和影片幀靜態圖像訓練,以賦予它們廣泛的視覺理解能力,包括對時間活動和相關圖像的理解。
它們能夠在多圖像輸入和文本提示的配合下,輕鬆進行視覺推理和理解任務。
模型預訓練時最多用了48張圖像,而在後訓練測試中,最多8張圖像也能取得不錯的效果。
Llama 4 Scout在圖像定位方面也是同類最佳,能夠將用戶的提示與相關的視覺概念對齊,並將模型的響應錨定到圖像中的特定區域。
這使得更精確的視覺問答成為可能,幫助LLM更好地理解用戶意圖並定位感興趣的對象。
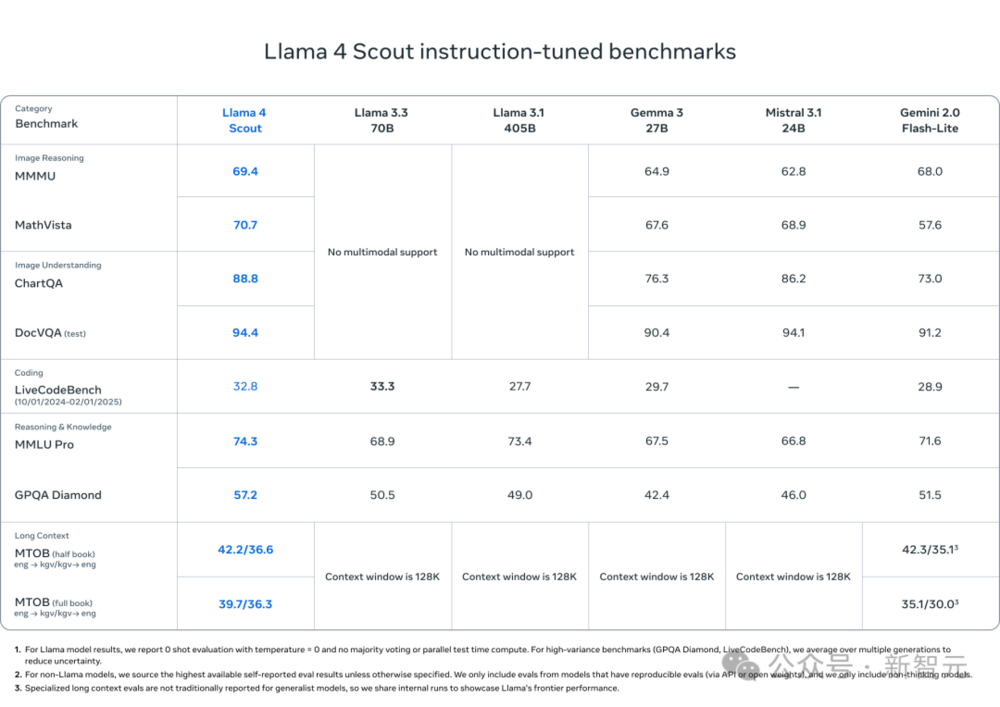
6. 編程、推理、長上下文和圖像上,遙遙領先
Llama 4 Scout在編程、推理、長上下文和圖像基準測試中超過了類似的模型,並且在所有以前的Llama模型中表現更強。
秉承對開源的承諾,Meta將Llama 4 Maverick和Llama 4 Scout提供給用戶下載,用戶可以在llama.com和Hugging Face上獲取,之後這些模型還將在最廣泛使用的雲平台、數據平台、邊緣矽片以及全球服務集成商上陸續上線。
2萬億巨獸,幹掉GPT-4.5
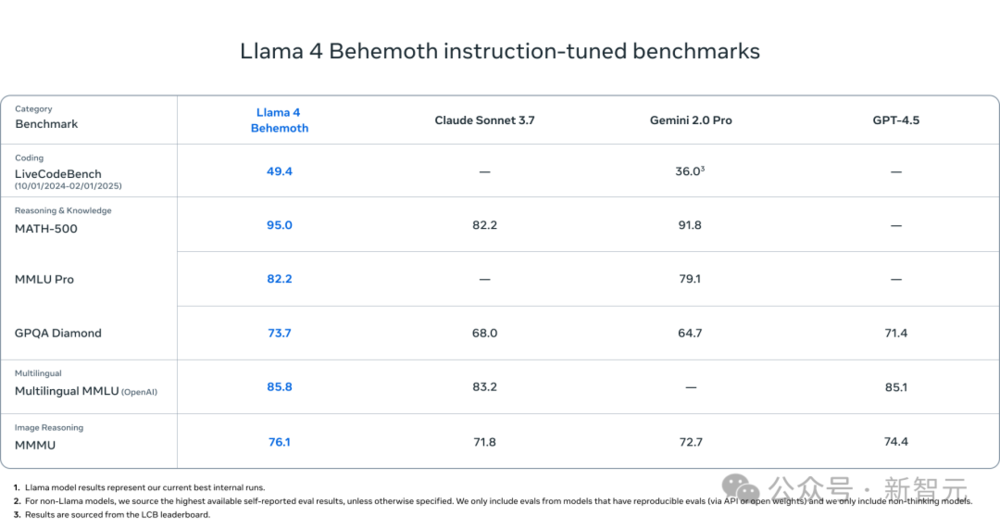
Llama 4 Behemoth是一款「教師模型」,在同級別的模型里,它的智能水平相當高超。
Llama 4 Behemoth同樣是一個多模態混合專家模型,擁有2880億個活躍參數、16個專家以及近2萬億個總參數。
在數學、多語言處理和圖像基準測試方面,它為非推理模型提供了最先進的性能,成為訓練較小的Llama 4模型的理想選擇。
1. 教師模型+全新蒸餾
從Llama 4 Behemoth中蒸餾出來Llama 4 Maverick,在最終任務評估指標上大幅提升了質量。
Meta開發了一種新的蒸餾損失函數,在訓練過程中動態地加權軟目標和硬目標。
通過從Llama 4 Behemoth進行共同蒸餾,能夠在預訓練階段分攤計算資源密集型前向計算的成本,這些前向計算用於計算大多數用於學生模型訓練的數據的蒸餾目標。
對於學生訓練中包含的額外新數據,會在Behemoth模型上運行前向計算,以生成蒸餾目標。
2. 後訓練
對一個擁有兩萬億參數的模型進行後訓練也是一個巨大的挑戰,這必須徹底改進和重新設計訓練方案,尤其是在數據規模方面。
為了最大化性能,不得不精簡95%的SFT數據,相比之下,較小的模型只精簡了50%的數據,目的是確保在質量和效率上的集中關注。
Meta還發現,採用輕量級的SFT後接大規模RL能夠顯著提高模型的推理和編碼能力。Meta的RL方案專注於通過對策略模型進行pass@k分析來采樣難度較大的提示,並設計逐漸增加提示難度的訓練課程。
在訓練過程中動態地過濾掉沒有優勢的提示,並通過從多個能力中混合提示構建訓練批次,對提升數學、推理和編碼的性能起到了關鍵作用。
最後,從多種系統指令中采樣對於確保模型保持良好的指令跟隨能力,在推理和編碼任務中表現出色也至關重要。
3. 擴展RL訓練
對於兩萬億參數的模型,擴展RL訓練也要求重新設計底層的RL基礎設施,應對前所未有的規模。
Meta優化了MoE並行化的設計,提高了速度,從而加快了迭代速度。
Llama團隊開發了一個完全異步的在線RL訓練框架,提升了靈活性。
與現有的分佈式訓練框架相比,後者為了將所有模型都加載到內存中而犧牲了計算內存,新基礎設施能夠靈活地將不同的模型分配到不同的GPU上,根據計算速度在多個模型之間平衡資源。
這一創新使得訓練效率比之前的版本提升了約10倍。
Llama 4一夜成為開源王者,甚至就連DeepSeek V3最新版也被拉下神壇,接下來就是坐等R2的誕生。
參考資料:
https://x.com/AIatMeta/status/1908598456144531660
https://x.com/astonzhangAZ/status/1908595612372885832
https://x.com/lmarena_ai/status/1908601011989782976