Llama 4五大疑點曝光,逐層扒皮!全球AI進步停滯,NYU教授稱Scaling徹底結束

新智元報導
編輯:Aeneas
【新智元導讀】剛剛,一位AI公司CEO細細扒皮了關於Llama 4的五大疑點。甚至有圈內人表示,Llama 4證明Scaling已經結束了,LLM並不能可靠推理。但更可怕的事,就是全球的AI進步恐將徹底停滯。
令人失望的Llama 4,只是前奏而已。
接下來我們恐將看到——全球局勢的改變,將徹底阻止AI進步!
最近,一位AI CEO做出長影片,逐級對Llama 4身上的六大疑點進行了扒皮。

同時,NYU教授馬庫斯發出博客,總結了目前這段時間AI圈的狀況。
Scaling已經結束;模型仍然無法可靠推理;金融泡沫正在破裂;依然沒有GPT-5;對不可靠的語言模型的過度依賴讓世界陷入了困境。我的25個2025年預測中的每一個,目前看起來都是對的。
大語言模型不是解決之道。我們確實需要一些更可靠的方法。
OpenAI和Anthropic這樣的公司,需要籌集資金來資助新模型本後的大規模訓練運行,但他們的銀行帳戶里並沒有400億或1000億美元,來支撐龐大的數據中心和其他費用。
問題在於,如果投資者預見到了經濟衰退,那就要麼不會投資,要麼投資較少。
更少的資金,就意味著更少的計算,也就是更慢的AI進展。
布魯金斯學會2025年的一份報告稱,若科研成本持續上升,美國在人工智能、生物技術和量子計算等關鍵領域的領先地位可能受到威脅。據估算,當前政策若持續實施五年,美國科研產出可能會下降8%-12%。
在以前的一個採訪里,Anthropic CEO Dario曾被問到:到了如今這個階段,還有什麼可以阻止AI的進步?他提到了一種可能——戰爭。
沒想到,在這個可能性之外,我們居然提前見證了系統的另一種混沌。
而Dario也提前預測到,如果出現「技術不會向前發展」的信念,資本化不足,AI進步就將停止。
AI CEO五大問,逐級扒皮Llama 4
最近鬧出大醜聞的Llama 4,已經證明了這一點。

我們很難說,Llama 4系列三款模型中的兩款代表了多少進展,顯然在這個系列的發佈中,誇大宣傳的水分要比誠實的分析多得多。
疑點1:長上下文大海撈針,其實是騙人?
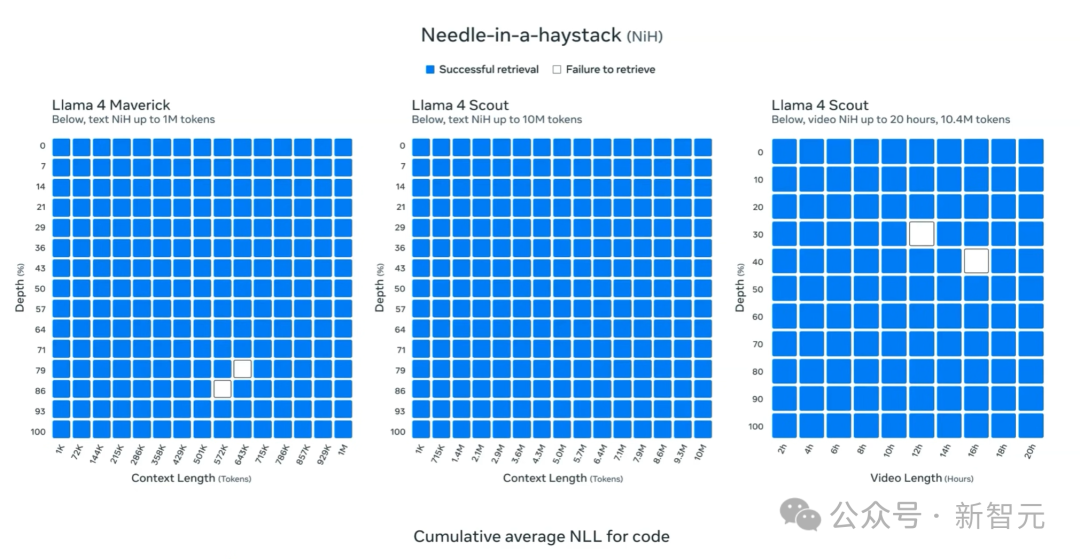
Llama擁有所謂業界領先的一千萬個token的上下文窗口,聽起來似乎很酷炫。
可是等等,24年2月,Gemini 1.5 Pro的模型,就已經達到1000萬token的上下文了!
在極端情況下,它可以在影片、音頻和共同文本上,執行驚人的大海撈針任務,或許,是Google忽然意識到,大海撈針任務意義非常重大。
正如這篇Llama 4博客所說,如果把所有哈利樸達的書都放進去,模型都能檢索到放入其中的一個密碼。
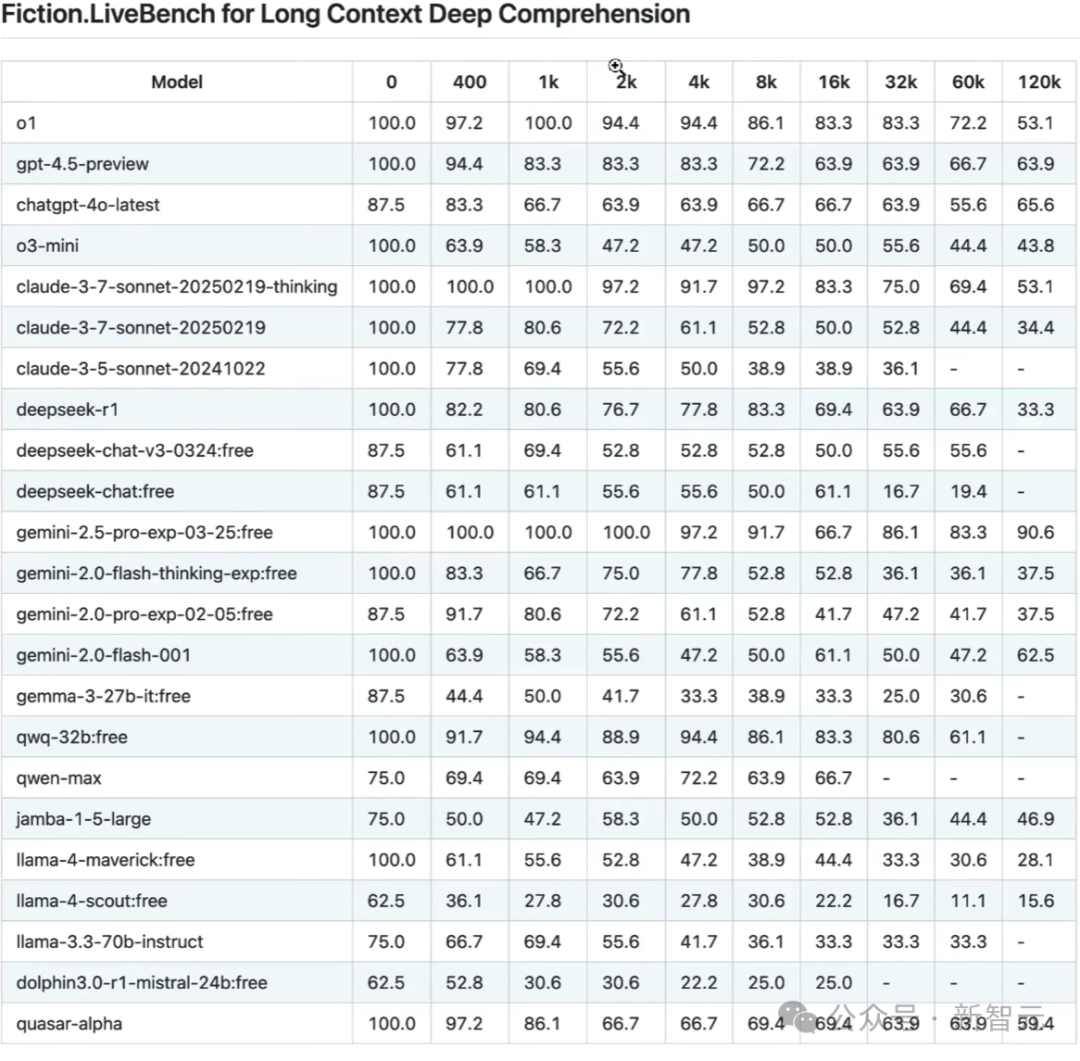
不過,這位CEO表示,這些48h前發佈的結果,不如24小時前更新的這個fiction livebench基準測試這麼重要。
這個基準測試,用於長上下文的深度理解,LLM必須將數萬或數十萬個token或單詞拚湊在一起。
在這裏,在這個基準測試中,Gemini 2.5 Pro的表現非常好,而相比之下,Llama 4的中等模型和小模型,性能極其糟糕。
而且隨著token長度的增加,它們的表現越來越差。
疑點2:為何週六發佈?
這位CEO察覺到的第二大疑點就在於,Llama 4為何選在週六發佈?
在整個美國AI技術圈里,這個發佈日期都是史無前例的。
如果陰謀論一點想,之所以選在週六發佈,是因為Meta自己也心虛了,希望儘量減少人們的注意力。
此外,Llama 4的最新訓練數據截止時間是2024年8月,這就很奇怪。
要知道,Gemini 2.5的訓練知識截止時間是2025年1月。
這就意味著,在過去的9個月裡,Meta一直在使盡渾身解數,拚命讓這個模型達到標準。
有一種可能性是,或許他們本打算早點發佈Llama 4,但就在9月,OpenAI推出了o系列模型,今年1月,DeepSeek R1又來了,所以Meta的所有計劃都被打亂了。

疑點3:大模型競技場,究竟有沒有作弊?
不過,這位CEO也承認,儘管全網充斥著對Llama 4群嘲的聲音,但它的確也展示出了一些堅實的進展。

比如Llama 4 Maverick的活動參數量大概只有DeepSeek V3的一半,卻取得了相當的性能。
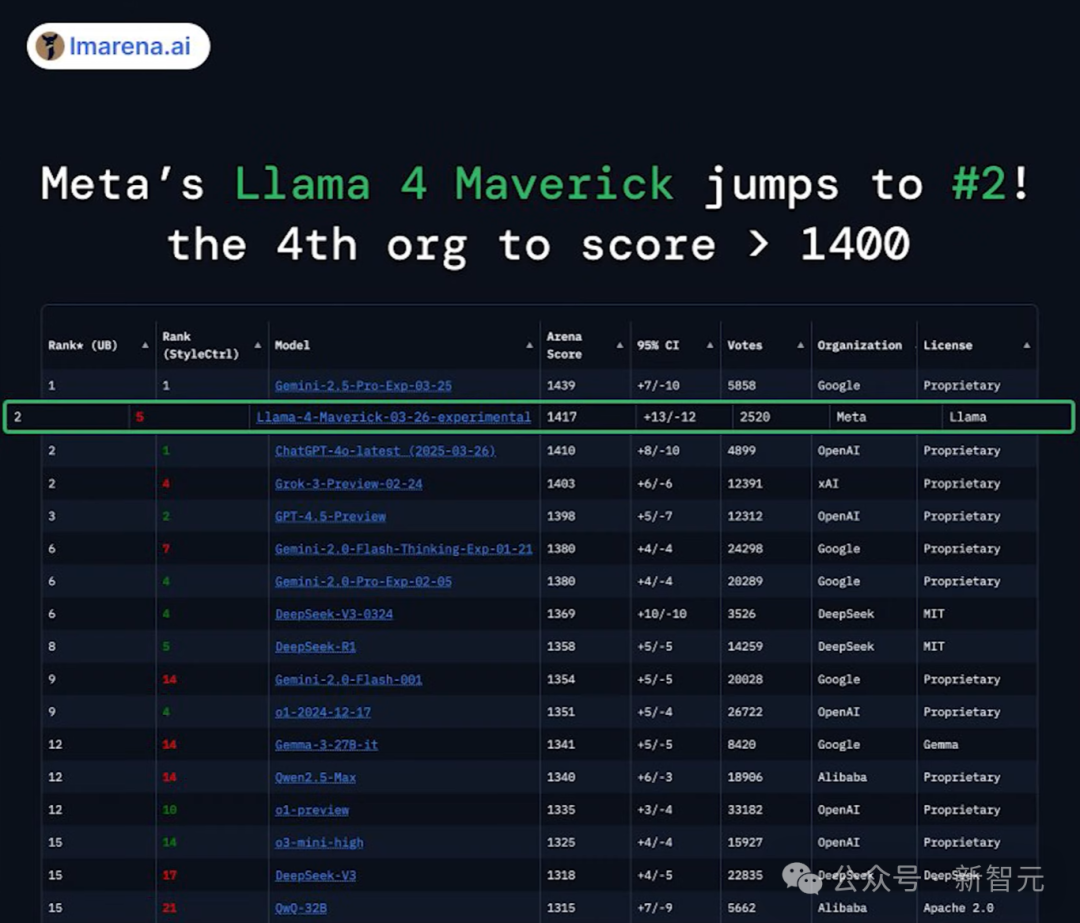
那現在的核心問題就在於,Meta究竟有沒有在LM Arena上進行作弊,在測試集上進行訓練?
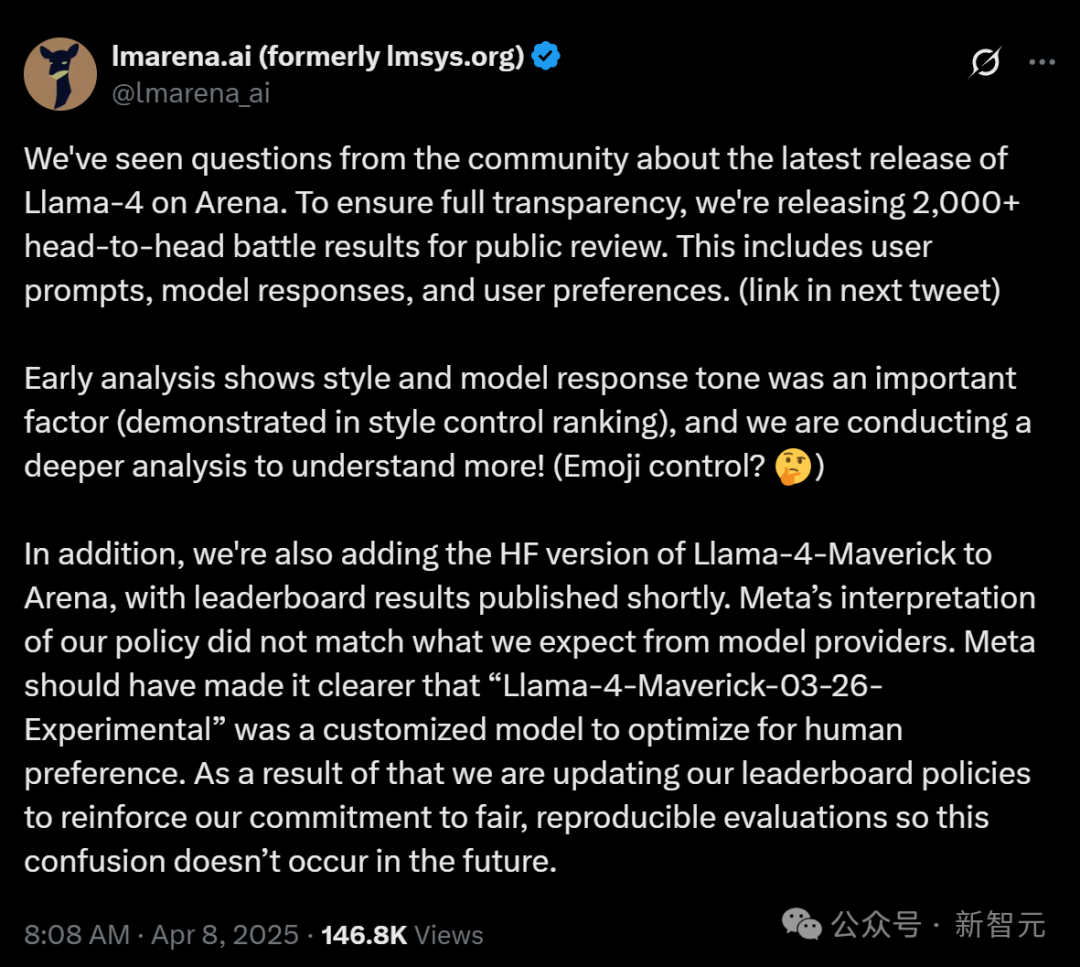
目前,LM Arena已經迅速滑跪,公開了2000多組對戰數據給公眾檢閱,並且表示會重新評估排行榜。
目前姑且按照沒有算,那就意味著我們擁有一個強大得驚人的基礎模型了。
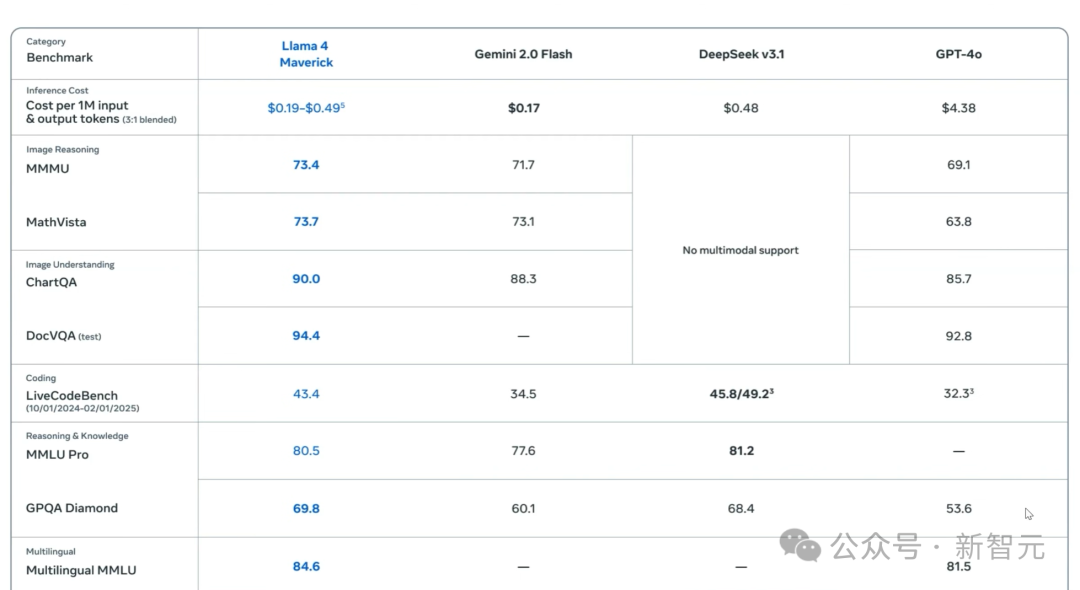
看看這些真實數字,假設沒有任何答案進入Llama 4的訓練數據,這個模型在GPQA Diamond上的性能(Google驗證的極其嚴格的STEM基準測試)實際上是比DeepSeek V3更好的
而在這個基礎上,Meta就完全可以創建一個SOTA級別的思維模型。
唯一的問題是,Gemini 2.5 Pro已經存在了,而DeepSeek R2也隨時會問世。
疑點4:代碼很差
還有一點,當Llama 4走出舒適區時,性能就會開始狂降。
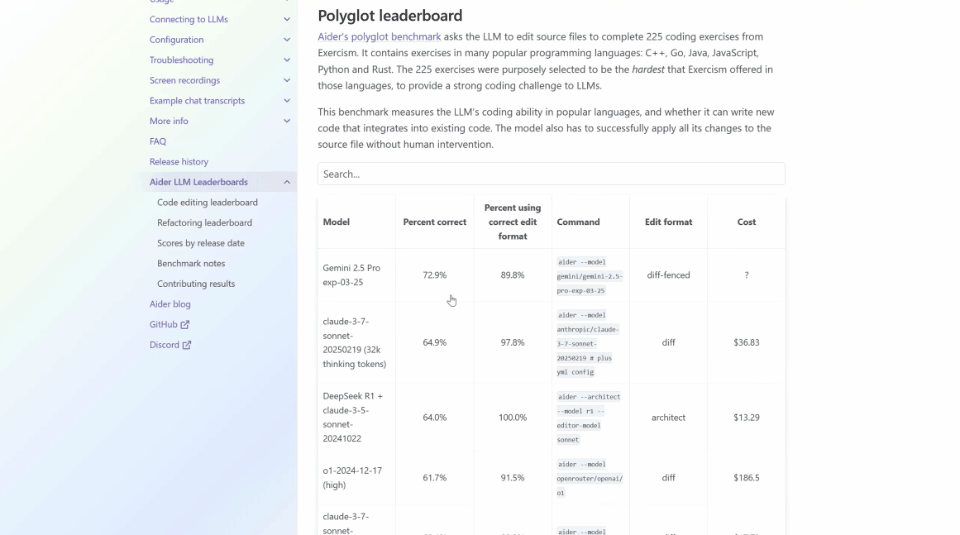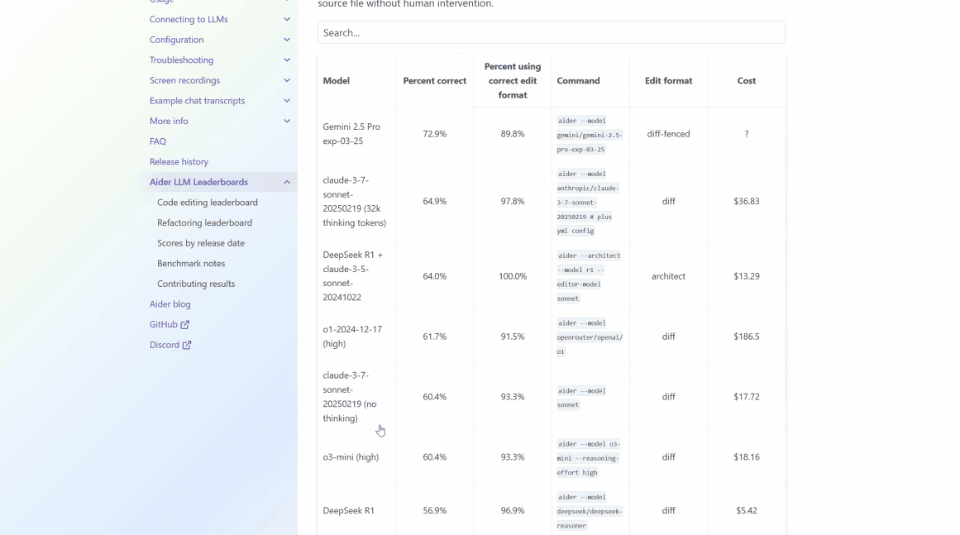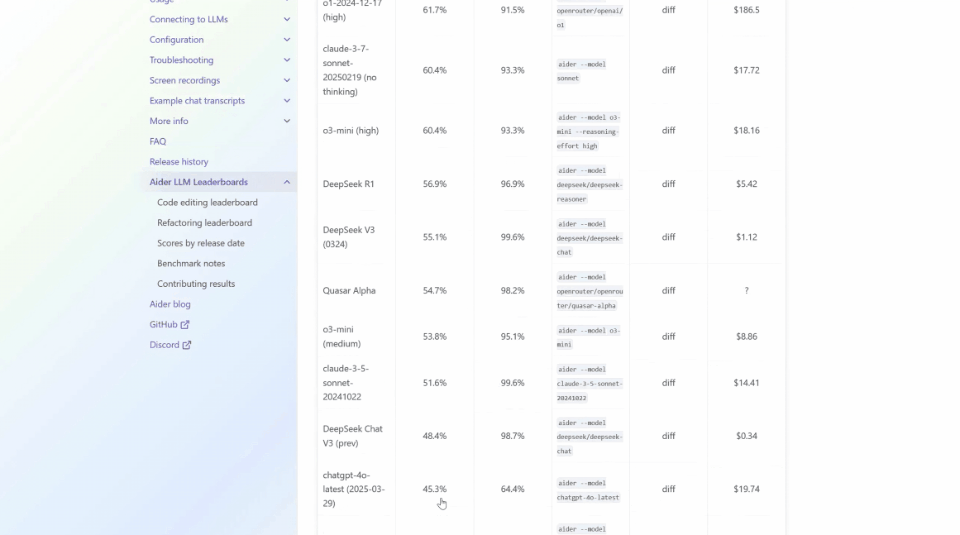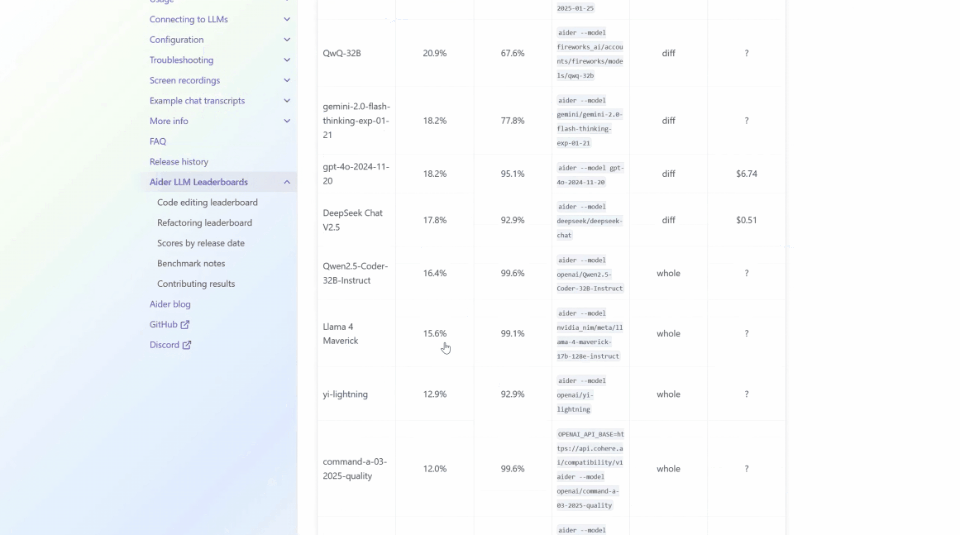
以ADA的Polyglot這個編碼基準測試為例,它測驗了一些系列編程語言的性能。
但與許多基準不同,它不僅僅關注Python,而是一系列編程語言,現在依然是Gemini 2.5 Pro名列前茅。
但是想要找到Llama 4 Maverick,可就很難了,得把鼠標滾動很久。
它的得分當然慘不忍睹——只有15.6%。
這就跟小紮的言論出入很大了,顯得相當諷刺。
就在不久前,他還信誓旦旦地斷定說,Meta的AI模型將很快取代中級程序員。
疑點5:「結果僅代表目前最好的內部運行」
這一點,同樣已經在AI社區引發了群嘲。
在下面這個表格中,Meta將Llama 4和Gemini2.0 Pro、GPT-4.5等模型進行了比較,數字非常漂亮。
但仔細看腳註,卻說的是Llama模型的結果代表了目前最好的內部運行情況,所以很大可能是,Meta把Llama 4跑了5遍或10遍,取了其中的最好結果。
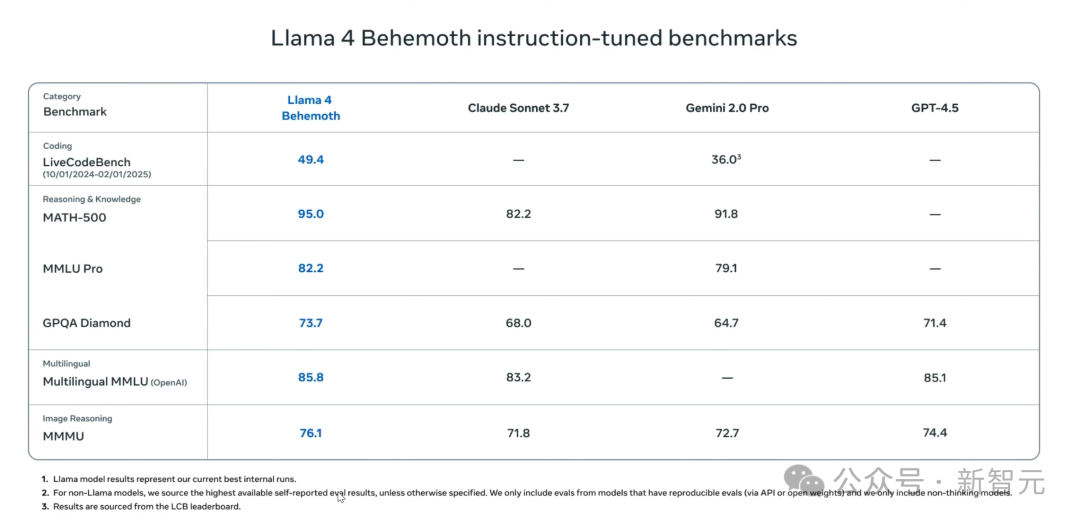
而且,他們還故意不將Llama 4 Behemoth跟DeepSeek V3進行比較,後者比它在整體參數上小三倍,在互動參數上小八倍,性能卻相似。
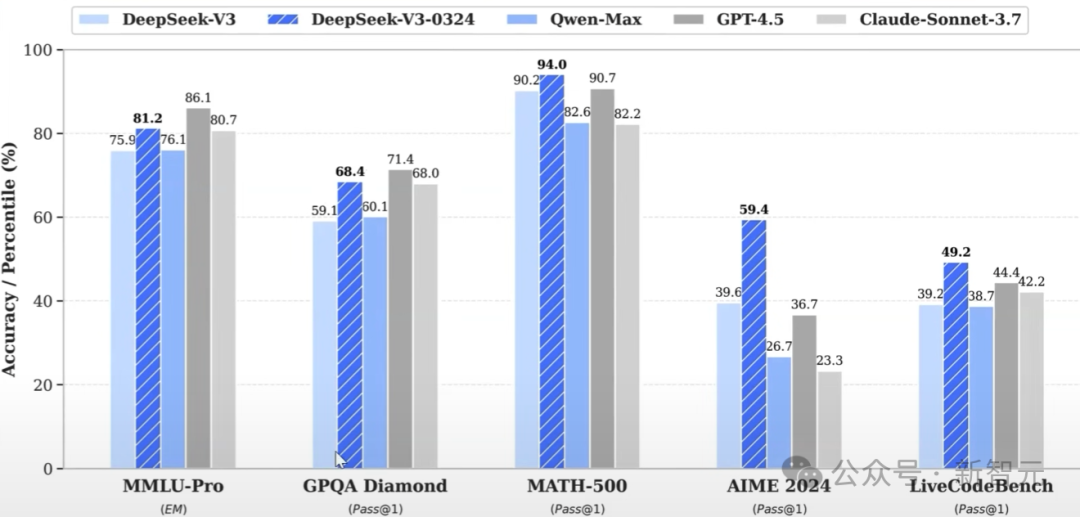
如果從消極的角度下判斷,就可以說Llama 4最大的模型參數上DeepSeek V3基礎模型的許多倍,性能卻基本處於同一水平。
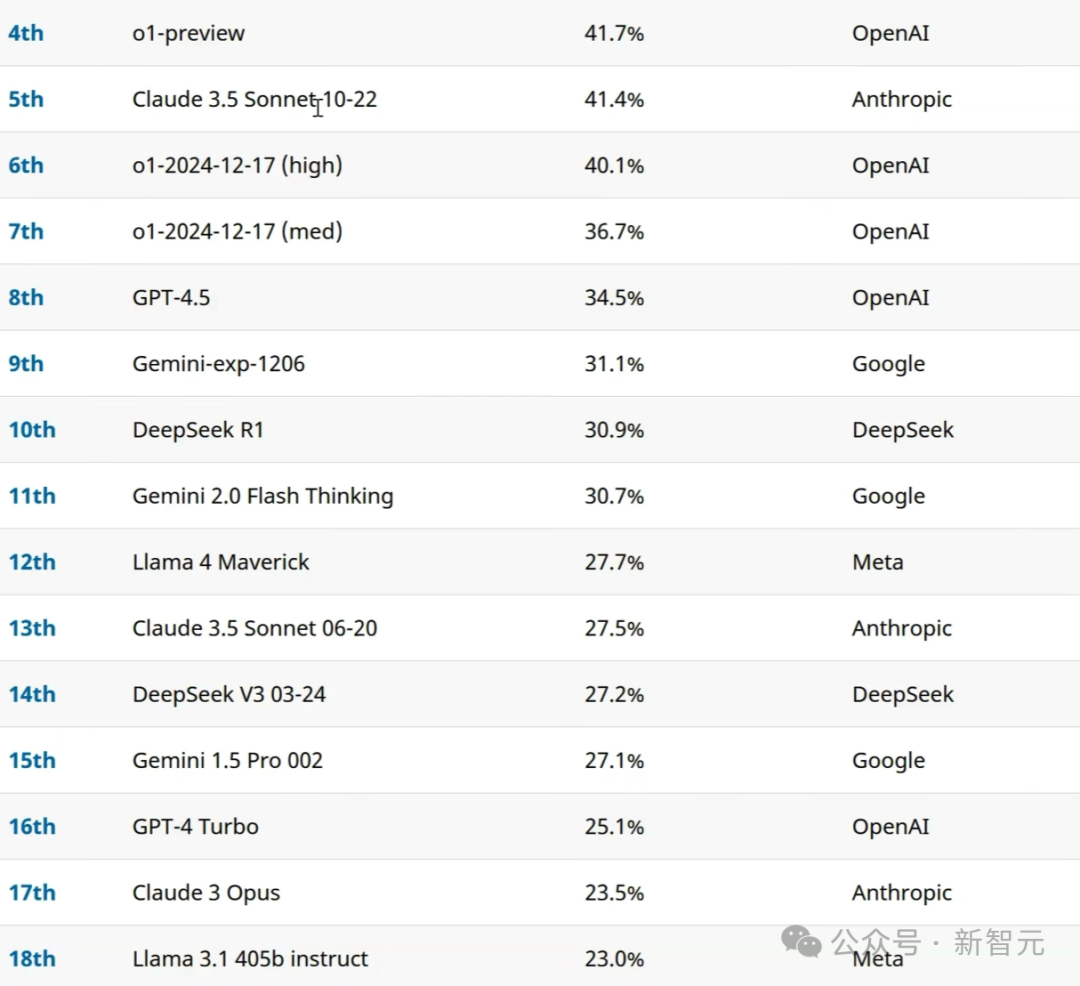
還有在Simple Bench中,Llama 4 Maverick的得分大概為27.7%,跟DeepSeek V3處於同一水平,還低於Claude 3.5 Sonnet這類非思維模型。
另外,這位CEO還在Llama 4的使用條款中發現了這麼一條。
如果你在歐洲,仍然可以成為它的最終用戶,但卻沒有權利在它的基礎上進行構建模型。

馬庫斯:Llama 4的慘痛教訓表明,Scaling已經結束!
而Llama 4的慘淡表現,也讓NYU教授馬庫斯寫出長文,斷言Scaling已經結束,LLM仍然無法推理。

他的主要觀點如下。
大模型的Scaling已經徹底結束了,這證實了我三年前在《深度學習正在撞牆》中的預測。
一位AI博士這樣寫道:Llama 4的發佈已經證實,即使30萬億token和2萬億參數,也不能讓非推理模型比小型推理模型更好。
規模化並不奏效,真正的智能需要的是意圖,而意圖需要遠見,這都不是AI能做到的。

即使LLM偶爾能提供正確的答案,往往也是通過模式識別或啟髮式的捷徑,而非真正的數學推理。
最終,生成式AI很可能會變成一個在經濟回報上失敗的產品。
泡沫可能真的要破滅了。英偉達在2025年的跌幅,就已經超過了三分之一。
而Meta的Llama 4的殘酷真相,再次證實了馬庫斯在2024年3月預測——
達到GPT-5級別的模型,將會非常困難。很多公司都會有類似模型,但沒有護城河。隨著價格戰進一步升級,許多隻會有微薄的利潤。

最終,馬庫斯以這樣的方式總結了自己的發言——
「大語言模型絕對不是解決之道,我們需要一些更可靠的方法。Gary Marcus正在尋找對開發更可靠替代方法有興趣的投資者。 」
參考資料:
https://garymarcus.substack.com/p/scaling-is-over-the-bubble-may-be