Google更新隱私政策,大模型“諸神之戰”背後的訓練數據隱憂
21世紀經濟報導記者王俊 南方財經全媒體記者馮戀閣 實習生羅洛 北京、廣州報導“我們可能會收集公開的在線信息或來自其他公共來源的信息,幫助訓練Google的人工智能模型。”近日,Google更新隱私政策,表示將利用網絡公開數據訓練旗下的AI模型,相關條款已於7月1日生效。
Google的這一動作引發爭議,單方面通知用戶的行為是否合法合規?此舉又是否有“囤數據”之嫌?
此前,Twitter和社交網站Reddit已經採取措施,限制第三方對其API的訪問。國外科技公司的一系列舉措背後,可能是大模型發展路上一個不可忽視的真相:訓練數據的重要性愈發顯現。隨著大模型產業的快速發展,出於市場競爭的需要,模型規模將快速膨脹,但同時可用於訓練的數據供給相對不足,且未來日趨稀缺。
未來,數據或將成為AI發展的“兵家必爭之地”。
“囤數據”訓練AI模型
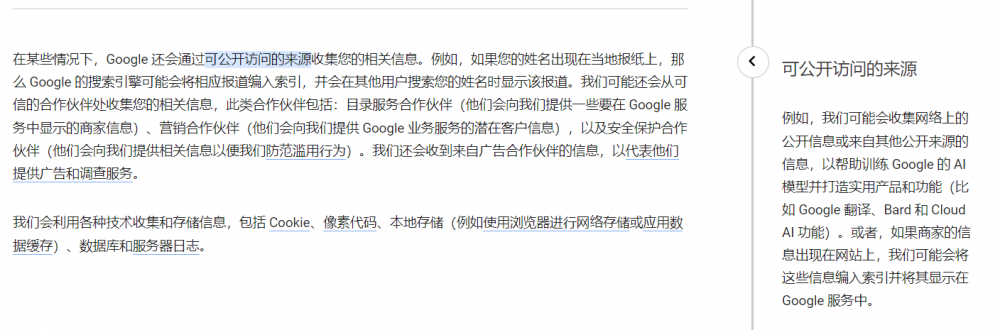
近日,Google更新隱私政策,表示將利用網絡公開數據訓練旗下的AI模型。在隱私協議的“可公開獲取的資源”一欄,Google提到:“我們可能會收集公開的在線信息或來自其他公共來源的信息,幫助訓練Google的人工智能模型。”該大模型將會為Google翻譯、Google旗下聊天機器人產品“Bard”及Cloud AI等產品和功能提供助力。
對比去年年底發佈的上一版隱私政策,Google將“收集信息以幫助訓練語言模型”的相關措辭更改為“訓練人工智能模型”,並新增明確了自家AI產品對於數據的使用權利。這似乎意味著,Google在訓練旗下聊天機器人及其他AI模型,或未來開發AI產品的過程中,有權使用人們在網上公開發佈的任意內容。
在競天公誠律師事務所合夥人袁立誌看來,此次Google隱私政策的更新從實踐角度看不算重大變化。“無論在我國還是域外,對公開數據的正常收集和使用,在一般情況下不算違法。”不過他補充道,如果個人通過發送郵件等方式向信息處理者就相關使用表露明確拒絕,對其個人信息的收集和使用就應當停止。
北京大成律師事務所高級合夥人鄧誌鬆也表示,就目前可獲得的信息而言,Google對收集與處理用戶個人信息的範圍和目的作出了詳細說明,即使以歐盟GDPR項下更為嚴格的“告知-同意”規則為標準,Google的這一收集與處理行為至少在形式上具有合法性。至於其實施過程中可能涉及的實質合法性判斷,及由此可能對AI等行業產生的影響,則尚待進一步觀察。
雖然此次更新並未對個人信息保護帶來影響,但暗藏背後的數據隱憂卻逐漸被公眾注意到。
“得數據者得天下”
數據是數字經濟時代的“新石油”,處在時代中的人工智能技術亦受其影響。
以OpenAI的幾代GPT模型為例,訓練數據上,GPT-1預訓練數據量僅有5GB;到了GPT-2,這個數據則增加至40GB;而在GPT3模型下,OpenAI用以訓練模型的數據集數據量達到了驚人的45TB。
“大模型時代,得數據者得天下。”對外經濟貿易大學數字經濟與法律創新研究中心執行主任張欣指出,一方面,訓練數據是大模型訓練的基石和燃料,如果沒有數據,大模型的訓練就無法開展和持續;另一方面,當前技術領域的研究顯示,各家大模型在算法層區別並不大,並且具有同質化的趨勢。在此背景下,訓練數據就成了真正區分且影響大模型性能的重要因素之一。
需求漸長,供給端卻並未馬上配合。目前,有多家處在“數據提供端”的公司對數據抓取、開源等做出了反應。比如Twitter限制了用戶每天能查看的推文數量,幾乎使數據提供服務無法使用。馬斯克表示,這是對“數據抓取”和“系統操縱”的必要反應。
今年1月,圖庫網站Getty Images對AI圖像生成器研發公司Stability AI提起法律訴訟,指其非法複製和處理版權圖像作為模型訓練數據。4月,環球音樂集團發函要求Spotify等音樂流媒體平台切斷AI公司的訪問權限,以阻止其版權歌曲被用於訓練模型和生成音樂。
同樣在4月,Reddit官方宣佈將對調用其API的公司收費,原因正是OpenAI、Google等公司利用該平台上的數據訓練模型。此外,IT技術問答網站Stack Overflow也計劃向AI大模型的開發者及公司收取數據訪問費用。
6月,中文在線、同方知網與中國工人出版社等國內25家文化出版機構發出共同倡議,強調“為人工智能學習模型提供可靠、穩定、安全的內容來源”等AIGC版權保護問題的重要性。
科技公司的系列動作,一定程度反映了數據的重要性。
在7月2日全球數字經濟大會人工智能高峰論壇上,崑崙萬維科技股份有限公司CEO方漢表示,高質量數據對大模型發展至關重要。
“坦白地講,最近三年的大模型訓練積累的是對豐富的預訓練數據深度加工的能力。OpenAI所有公開的論文和講演,對訓練過程和訓練算法都是公開的,但其從不公開模型結構及數據處理。”方漢指出,目前全世界大模型預訓練團隊都試圖重現OpenAI在模型架構的動作以及預訓練數據的動作,任何一家企業的預訓練數據加工能力都至關重要。
數據稀缺、分散難題何解?
數據的重要性不言而喻,高質量數據更是稀缺品。
早在去年,一項來自Epoch Al Research團隊的研究就揭示了一個殘酷的事實:模型還要繼續做大,但數據卻不夠用了。研究結果表明,高質量的語言數據存量將在2026年耗盡,低質量的語言數據和圖像數據的存量則分別在2030年至2050年、2030年至2060年枯竭。
這意味著如果數據效率沒有顯著提高或沒有新的數據源可用,那麼到2040年,模型的規模增長將放緩。
百舸爭流是市場競爭的常態,但過分競爭也有可能為行業帶來災難。限制數據抓取,很可能導致新一輪的數據大戰,進而引發平台之間屏蔽、數據壟斷等問題。
國際標準化組織TC/154技術專家王翔指出,大模型的蓬勃發展對訓練數據提出了很高的數量和質量要求。在供給側,人口增速、用網時間下降、制度性地理約束提高、高質量數據匱乏等都在製約大模型未來發展,SOP化和轉發習慣也降低了供給能力;在需求側,無論是主觀治理思路還是客觀基礎設施條件,以及大型語言模型所有者應對市場的考量,都會持續強化數據壟斷。
此外,大模型訓練中,面對的高質量數據的稀缺、行業數據分散等問題應如何解決?
受訪專家指出,未來健康的生態需要市場側和監管側等多方的共同建設維護。
“首先還是需要相信市場的力量”,袁立誌指出,隨著優質數據的需求逐漸顯現,各個市場主體都會被“無形的手”推動向前。“數據資源的尋找、彙聚、清洗、標註等各個環節預計都會因競爭的活躍而不斷改善,以滿足市場需求。”他表示。
張欣則具體指出,目前行業內的開源數據集正在不斷增多,未來應呼籲更多人工智能企業、從業者加入,建立更加良好的行業生態。“人工智能訓練時的眾包思路也非常重要。”她認為,企業之外,還可以善用技術社群的力量提升並開拓更多的高質量數據集。
而監管側,在張欣看來,從法律法規層面明確訓練數據集的合法性獲取路徑是監管下一步應當關注的重點。“只有明確了合法獲取的路徑,大模型訓練者才有更穩定的合規預期以開展工作。”
袁立誌認為,監管側數據要素市場的建設深入會為大模型領域的發展帶來良性影響。“數據要素市場建設走深意味著數據流通利用全流程提速提效,自然也惠及大模型的訓練數據收集。”
(作者:王俊,馮戀閣,實習生羅洛 編輯:張銘心,林虹)