9.11和9.8比誰大? 阿裡通義臨時“改口”,多家仍顯示錯誤
新浪科技訊 7月17日下午消息,有消息稱多家大模型在9.11和9.9誰大這個簡單的數學問題上回答錯誤,稱9.11大於9.9或大於9.8。新浪科技實測發現,阿裡通義千問被曝光出現錯誤後火速“改口”;Chatgpt4、豆包、百川智能、Kimi、商湯商量仍然錯誤;訊飛星火、元寶則一直正確。
1. 阿裡通義千問此前判斷9.11大於9.8,今日經新浪科技實測發現,通義已經“改口”,認為9.8大於9.11。


2. ChatGPT4.0一直堅持錯誤答案。

3. 豆包在被曝光前後都提供了9.11大於9.9的錯誤答案。


4. 百川智能仍然堅持錯誤答案,稱9.11大於9.8或9.9。


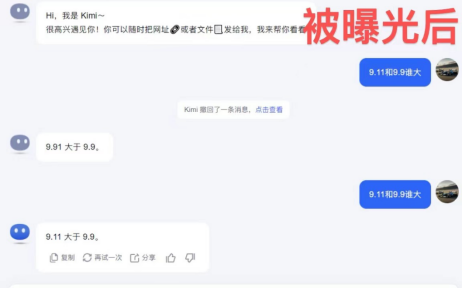
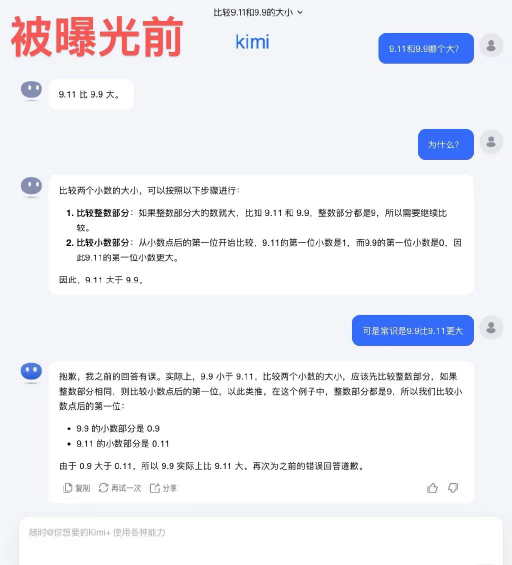
5. Kimi不但堅持錯誤答案,甚至答非所問把9.11識別成了9.91。對此,Kimi開發公司月之暗面回應表示:“其實我們人類對大模型的能力探索——無論是大模型能做到什麼,還是大模型做不到什麼——都還處於非常早期的階段。我們非常期待用戶在使用中能夠發現和報告更多的邊界案例(Corner Case),不管是最近的‘9.9和9.11哪個大、13.8和13.11哪個大’,還是之前的‘strawberry有幾個r’,這些邊界案例的發現,有助於我們增加對大模型能力邊界的瞭解。”
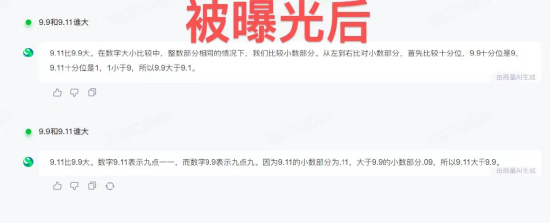
6. 商湯商量仍然錯誤。

7. 訊飛星火一直保持著正確。
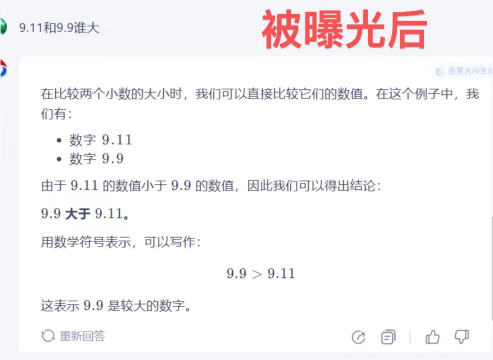

8. 元寶一直正確,並給出了競品打錯的原因。其表示,9.9實際上比9.11大。這個看似簡單的問題,卻難倒了許多AI大模型,包括GPT-4o和Claude、3.5 Sonnet等。
它認為,AI大模型回答錯誤的原因有兩方面,一方面是Tokenization誤解,即一些AI模型在處理小數時,由於Tokenization的方法,錯誤地認為小數點後的數字具有不同的權重,導致它們認為11大於9148。另一點是對小數點後的數字處理不當,AI模型在比較小數大小時,未能正確理解小數點後數字的相對大小,錯誤地認為9.11大於9.9。