Google蘋果曝出LLM驚人內幕,自主識別錯誤卻裝糊塗!AI幻覺背後藏著更大秘密

新智元報導
編輯:桃子
【新智元導讀】大模型幻覺,究竟是怎麼來的?Google、蘋果等機構研究人員發現,大模型知道的遠比表現的要多。它們能夠在內部編碼正確答案,卻依舊輸出了錯誤內容。
到現在為止,我們仍舊對大模型「幻覺」如何、為何產生,知之甚少。

最近,來自Technion、Google和蘋果的研究人員發現,LLM「真實性」的信息集中在特定的token,而且並得均勻分佈。
正如論文標題所示,「LLM知道的往往要比表現出來的更多」。
 論文地址:https://arxiv.org/pdf/2410.02707
論文地址:https://arxiv.org/pdf/2410.02707不僅如此,他們還發現,內部表徵可以用來預測LLM可能會犯錯的錯誤類型。
它的優勢在於,未來有助於開發出針對性的解決方案。
最後,研究團隊還解釋了,大模型內部編碼和外部行為之間存在的差異:
它們可能在內部編碼了正確答案,卻持續生成錯誤答案。
幻覺,如何定義?
事實錯誤、偏見,以及推理失誤,這些統稱為「幻覺」。
以往,大多數關於幻覺的研究,都集中在分析大模型的外部行為,並檢查用戶如何感知這些錯誤。
然而,這些方法對模型本身如何編碼、處理錯誤提供了有限的見解。

近期另有一些研究表明,LLM內部狀態其實「知道」那些輸出可能是錯誤的,而且這種「知識」被編碼在模型內部狀態中。
這一發現可以幫助提高錯誤檢測的性能,並進一步緩解這些問題。
不過其中一個缺陷是,這些研究主要集中了檢驗模型生成最後一個token、或提示符中最後一個token。
由於LLM通常會生成長篇的相應,因此這一做法可能會錯過關鍵細節。
在最新研究中,研究團隊採取了不同的方法:
不只是看最終的輸出,而是分析「確切的答案token」,如若修改,將會改變答案的正確性的相應token。
最終證明了,LLM內部表徵所包含的真實性信息,比以往要多得多。
但這種錯誤檢測器難以在不同數據集之間泛化,這說明真實性編碼並非統一的,而是多方面的。
更好的錯誤檢測
給定一個大模型M,輸入提示p、模型生成的響應ŷ,任務預測ŷ是正確還是錯誤的。
假設可以訪問LLM內部狀態(即白盒設置),但不能訪問任何外部資源(如搜索引擎或其他LLM)。
數據集使用的是
代表著對應的真實答案。
代表著一系列問題,
,包含N個問題-標籤對,
對於每個問題q_i,作者讓模型M生成響應y_i,得到預測答案集
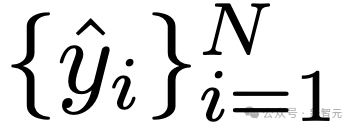
接下來, 研究人員構建了錯誤檢測數據集,通過將每個生成的響應ŷ_i與真實標籤y_i比較,以評估其正確性。
比較結果會產生出一個正確的標籤z_i ∈ {0, 1}(1表示正確,0表示錯誤)。
這種比較可以通過自動啟髮式方法,在指令型LLM的協助下完成。
最終的錯誤檢測數據集為
。其排除了LLM拒絕回答的情況,因為這些可以輕易地被分類為錯誤。
接下來,研究人員在Mistral 7B和Llama 2模型的四個變體上進行了實驗。
這些模型跨越了十個數據集,涵蓋了各種任務。
其中包括問答、自然語言推理、數學問題解決、情感分析。
他們允許模型生成不受限制的響應,來模擬真實世界的使用情況。
這裏,一共用到了三種錯誤檢測方法:Aggregated probabilities / logits、P(True)、Probing。
精確答案token
現有的方法經常忽略一個關鍵的細微差別:用於錯誤檢測的token選擇,通常關注最後生成的token或取平均值。
然而,由於大模型通常會生成長篇回覆,這種做法可能會錯過關鍵細節。
還有一些方法使用提示最後的一個token,但本質上是不正確的,因為大模型的單向性,未能考慮生成響應和丟失的情況,其中同一模型的不同采樣答案在不同情況下,有所不同正確性。
對此,研究人員檢查了以往未經檢查的token位置:確切的答案token,代表生成響應中最有意義的部分。
他們將精確答案token定義為那些修改會改變答案的正確性token,而忽略了後續生成的內容。
如下圖圖1,說明了不同的token位置。

實驗結果
真實性編碼模式
研究人員首先專注於探索分類器,以瞭解LLM的內部表徵。
具體來說,廣泛分析了層和token選擇對這些分類器激活提取的影響。這是通過系統地探測模型的所有層來完成的,從最後一個問題token開始,一直到最終生成的token。
下圖2顯示了Mistral-7b-Instruct各個層和token中經過訓練的探測器的AUC指標。
雖然,某些數據似乎更容易進行錯誤預測,但所有數據集都表現出一致的真實性編碼模式。
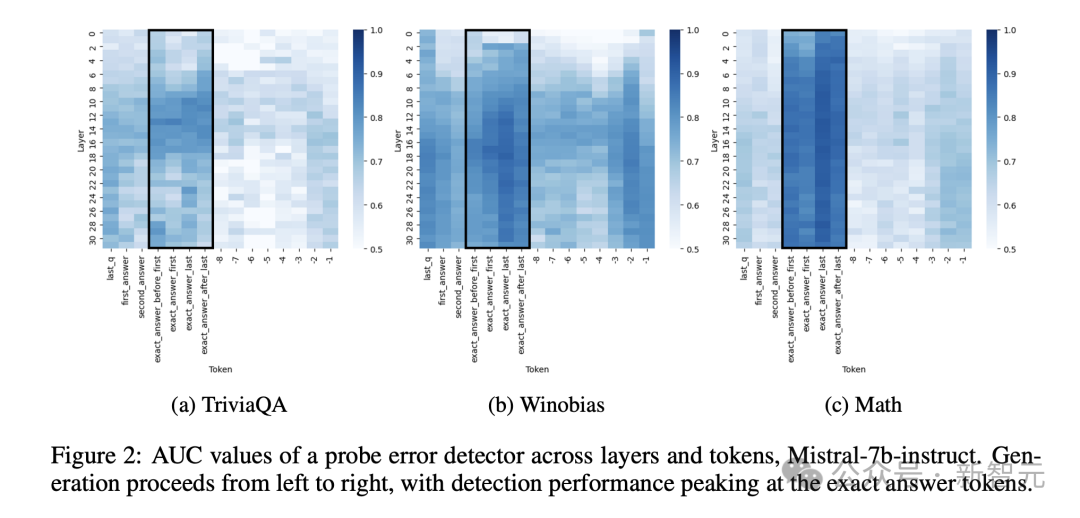
對於token來說,提示後立即出現了強烈的真實性信號,表明這種表徵編碼了有關模型正確回答問題的一般能力的信息。
對著文本生成的進行,該信號會減弱,但在確切的答案token處,再次達到峰值。
再生成過程即將結束時,信號強度再次上升,表明了該表徵編碼了整個生成過程的特徵,儘管它仍弱於確切答案token。
錯誤檢測結果
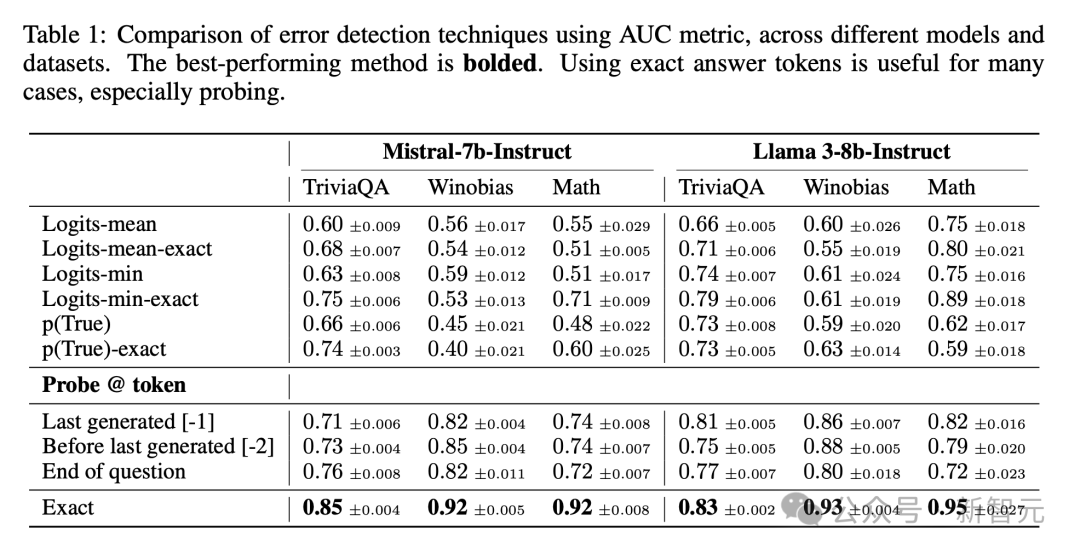
接下來,研究人員通過比較使用、不使用精確答案token的性能,來評估各種錯誤檢測方法。
表1比較了三個代表性數據集的AUC。
在這裏,他們展示了最後一個精確答案token的結果,它的性能優於第一個精確答案token及其前面的token,而最後一個精確答案token之後的token性能類似。
合併精確答案token,有助於改進幾乎所有數據集中的不同錯誤檢測方法。
任務之間的泛化
以上,探測分類器在檢測錯誤方面有效性,表明了大模型對其輸出的真實性進行了編碼。
但目前仍不清楚的是,它們跨任務的通用性。
然而,理解這一點對於實際應用至關重要,因為錯誤檢測器可能會遇到與訓練時完全不同的示例。
因此,研究人員探討在一個數據集上訓練的探測器,是否可以檢測其他數據集的錯誤。
如下圖3顯示了Mistral-7b-Instruct的泛化結果。在這種情況下,高於0.5的值表明泛化成功。
乍一看,結果似乎與之前的研究一致:大多數熱圖值超過0.5,這意味著跨任務具有一定程度的泛化性。
然而,再仔細檢查,發現大部分性能可以通過基於logit的真實性檢測來實現,該檢測僅觀察輸出logits。
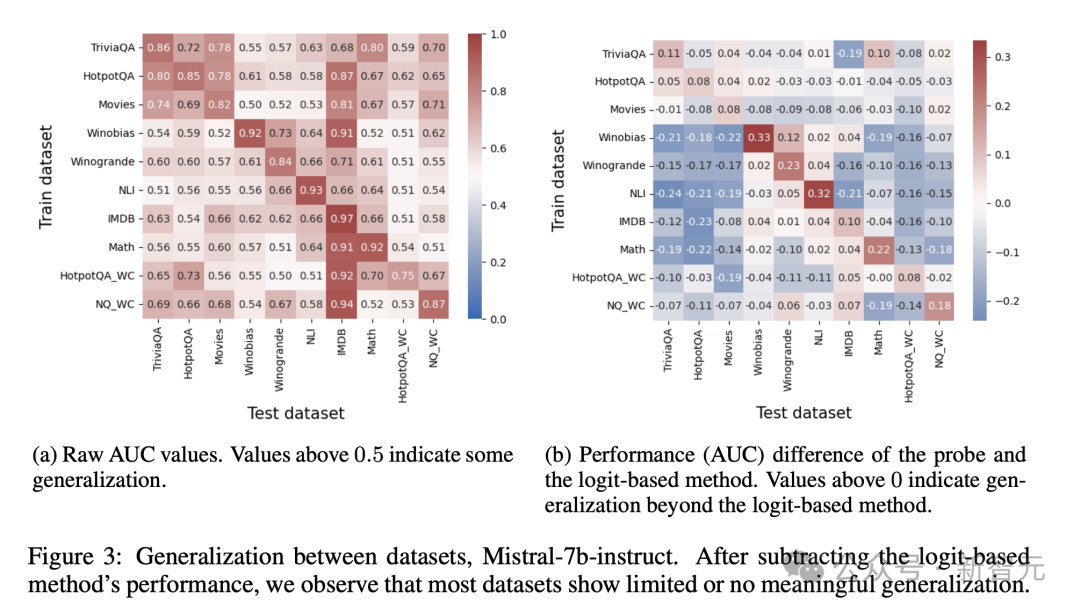 圖3b顯示了從最強的基於Logit的基線(Logit-min-exact)中減去結果後的相同熱圖。
圖3b顯示了從最強的基於Logit的基線(Logit-min-exact)中減去結果後的相同熱圖。這張 調整後的熱圖揭示了探測器的泛化能力很少超過單獨檢查 logits所能達到的效果。
這意味著明顯的概括並非源於真實性的普遍內部編碼,而是反映了已經可以通過邏 輯等外部特徵獲取的信息。
調查錯誤類型
在確定了錯誤檢測的局限性後,研究人員轉向錯誤分析。
錯誤分類
圖4說明了,三種代表性的錯誤類型。
在其中一個(圖4a)中,模型通常會給出正確的答案,但偶爾會出錯,這意味著存在正確的信息,但采樣可能會導致錯誤。
在第二種類型中(圖4b),模型經常做出錯誤的響應,儘管它能夠提供正確的答案,這表明儘管不斷犯同樣的錯誤,但仍然保留了一些知識。
在第三種類型中(圖4c),模型生成了大多數答案都是錯誤的,反映出對任何生成的答案的信心較低。
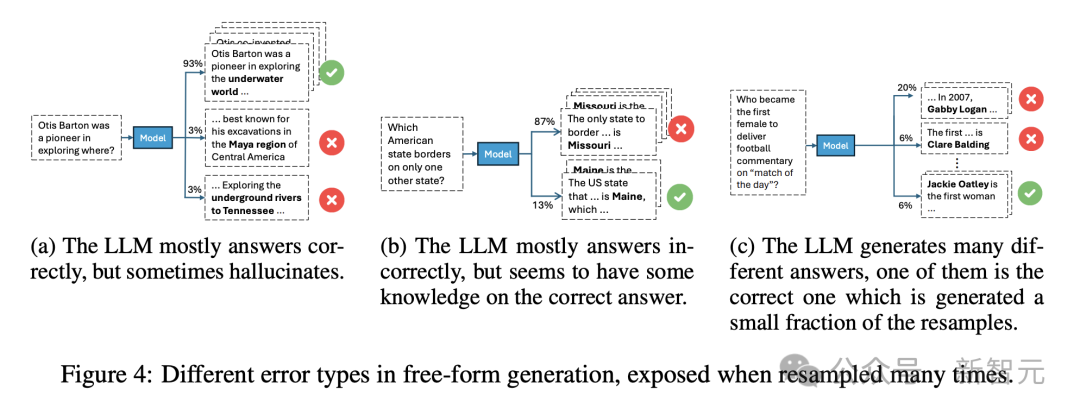
研究人員通過記錄每個示例的三個特定特徵來對錯誤進行分類:(a)生成的不同答案的數量;(b) 正確答案的頻率;(c) 最常見的錯誤答案的頻率。
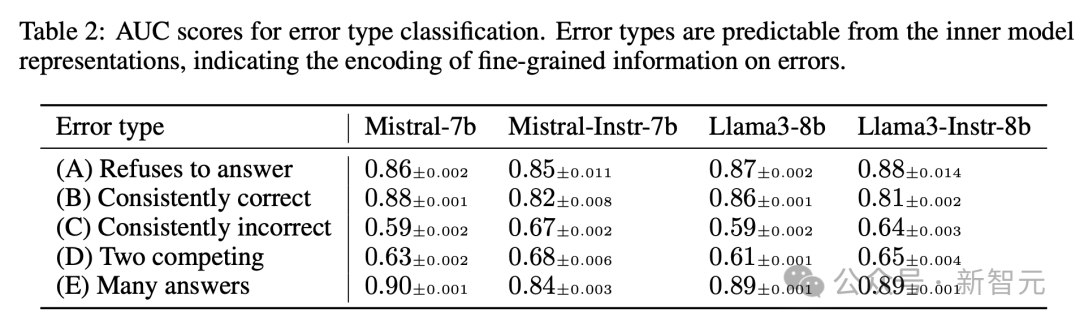
預測錯誤類型
表2列出了所有模型的測試集結果。
檢測正確答案
最後,在確定模型編碼各種與真實性相關的信息後,作者又研究了這種內部真實性,如何在響應生成過程中,與外部行為保持一致。
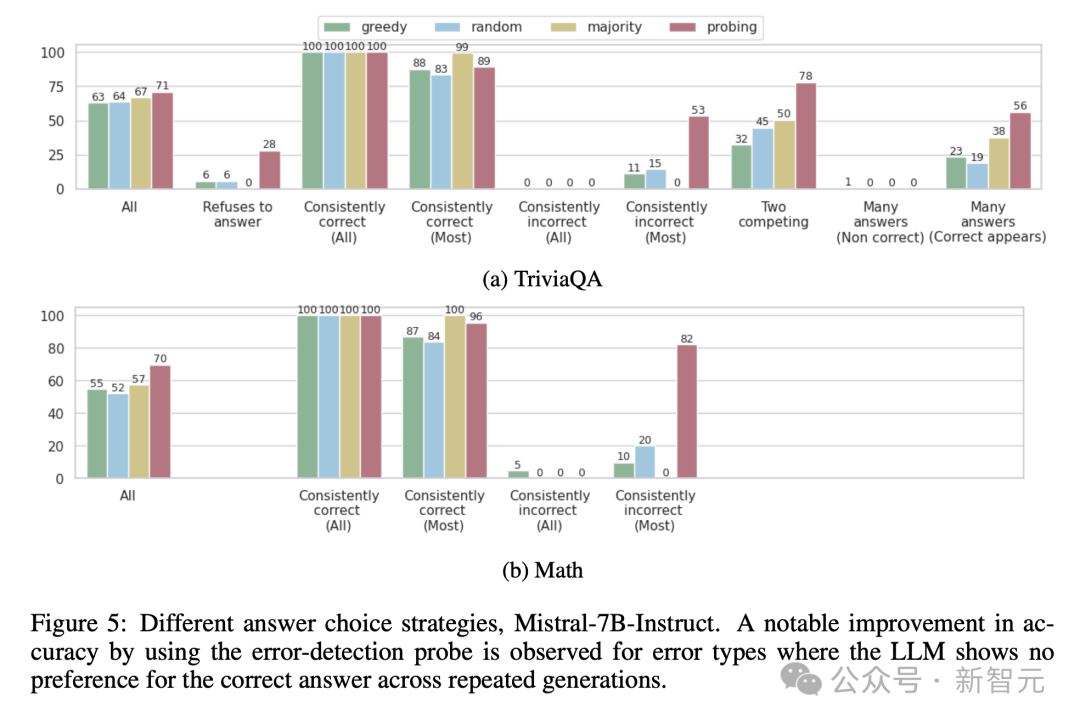
為此,他們使用了探測器(5個經過錯誤檢測訓練),從針對同一問題生成的30個響應中,選擇一個答案。
然後,根據所選答案來衡量模型的準確性。
Mistral-7b-instruct的結果如下圖5所示,總體而言,使用探測器選擇答案可以提高大模型在所有檢查任務中的準確性。
總之,這項研究的發現,可以幫助未來研究人員去設計更好的幻覺環節系統。
遺憾的是,它使用的技術需要訪問內部LLM表徵,這也主要適用於開源模型的使用。
參考資料: