奧特曼專訪自曝OpenAI掌握AGI密鑰,2025年降臨!1人1萬塊GPU締造十億獨角獸

新智元報導
編輯:編輯部
【新智元導讀】AGI 2025年到來,ASI幾千天內降臨,奧特曼在最新專訪中金句頻出。不僅如此,他的話還得到了德撲之父、自家員工的證實。
1個人+10000個GPU,就能打造價值10億美元的公司?
OpenAI已經掌握了通往AGI的內部路徑,我們距ASI只有幾千天時間了?
就在最近,OpenAI CEO奧特曼在最新訪談里,再次爆出不少金句。

YC總裁兼CEO Garry Tan對奧特曼展開了一次訪問,談論了OpenAI的起源,公司的下一步發展,以及他對於創始人該如何駕馭一個龐大公司的建議。
在所有人都在認為奧特曼又在炒作的同時,德撲之父、OpenAI研究員Noam Brown卻證實,「但據我所見,他所說的一切都與OpenAI一線研究人員的普遍觀點相符」。

另一位OpenAI員工稱,「100%讚成!在OpenAI工作的三年里,我一直在專心地聽奧特曼的話,他的言辭和評論都很準確」。

這也就意味著,4級AGI——「AI發明者」很快將要實現了!

ASI幾千天內降臨,現在是創辦科技公司的最佳時機嗎
前不久,奧特曼的一篇《ASI幾年內降臨,人類奇點將至》在圈內引發熱議。
他表示,深度學習已經奏效了,它能夠真正學習任何數據的分佈模式。如今人類奇點已經近在咫尺,我們眼看著就要邁進ASI的大門。
由此,Garry Tan和奧特曼展開了進一步討論。
奧特曼表示,如今可以說是創辦科技公司的最佳時機。
每次重大技術革命,都讓我們能比之前做得多,這也讓他希望,公司會更令人驚奇,更有影響力。
當事情進展緩慢時,大公司會佔據優勢。當移動互聯網/半導體/AI革命發生時,新興公司就會佔據優勢。
Garry Tan提到奧特曼之前對ASI幾千天內到來的預判,奧特曼表示,這其實是OpenAI的願景,其實相當瘋狂。
他認為,自己能看到這樣一條路徑。
當OpenAI的工作不斷積累,過去三年中的進展繼續在接下來的三年、六年、九年中持續下去,保持這種速度,那系統能做的事情,就會非常非常多。
跟封閉的、在某領域有明確任務的原始智商相比,o1已經非常聰明了。
奧特曼認為,我們可能會遇到未知的障礙,或者錯過一些東西,但目前看來,前方還有許多復合增長尚未發生。
在他看來,解決氣候問題、建立太空殖民地、發現所有物理學、近乎無限的智能和充足的能源這些事情,也許的確離我們並不遙遠。
而他喜歡YC的一點就是,它鼓勵這種稍微不切實際的技術樂觀主義,以及「你可以做到」的信念感。
如果我們能實現充足能源,人類的體力勞動就能通過機器人和隨時可調動的語言和智能來解鎖,我們將進入一個真正的富足時代。
我們會更快地得出更好的想法,然後在物理世界中將之實現(當然也需要大量能源)。
如今,太陽能加儲能的發展軌跡已經足夠好,即使沒有重大的核突破,我們也會很好。
奧特曼預言到:未來,我們會解決物理學中的每一個問題,這隻是時間問題。
到那一天,我們不會再討論核聚變,而是討論戴森球。
對我們的曾孫來說,地球的能源已經不夠了,他們會去有大量物質的外太空。
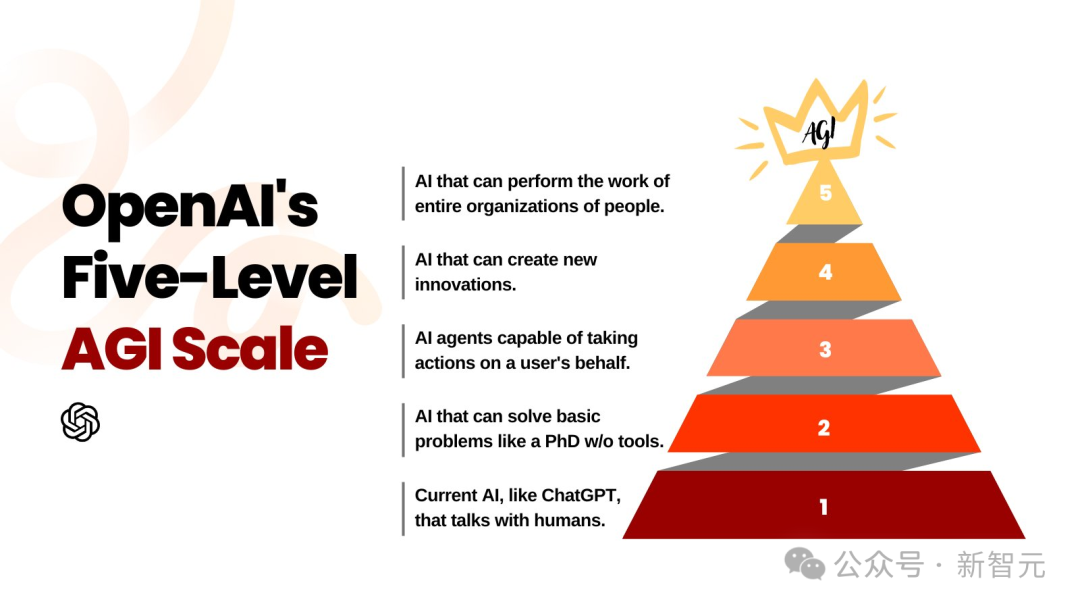
OpenAI「5級AGI」藍圖
Garry Tan表示,對OpenAI來說,這是偉大的一年,儘管有一些戲劇性事件。你從去年秋天的罷免事件中學到了什麼,對一些離職有什麼感受?
奧特曼稱,很累,但還好。我們用了不到兩年的時間,加速一個中型、甚至是大型科技公司的進程,這通常來說會需要十年的時間。
 奧特曼最近表示,ChatGPT已經成為世界上第八大網站
奧特曼最近表示,ChatGPT已經成為世界上第八大網站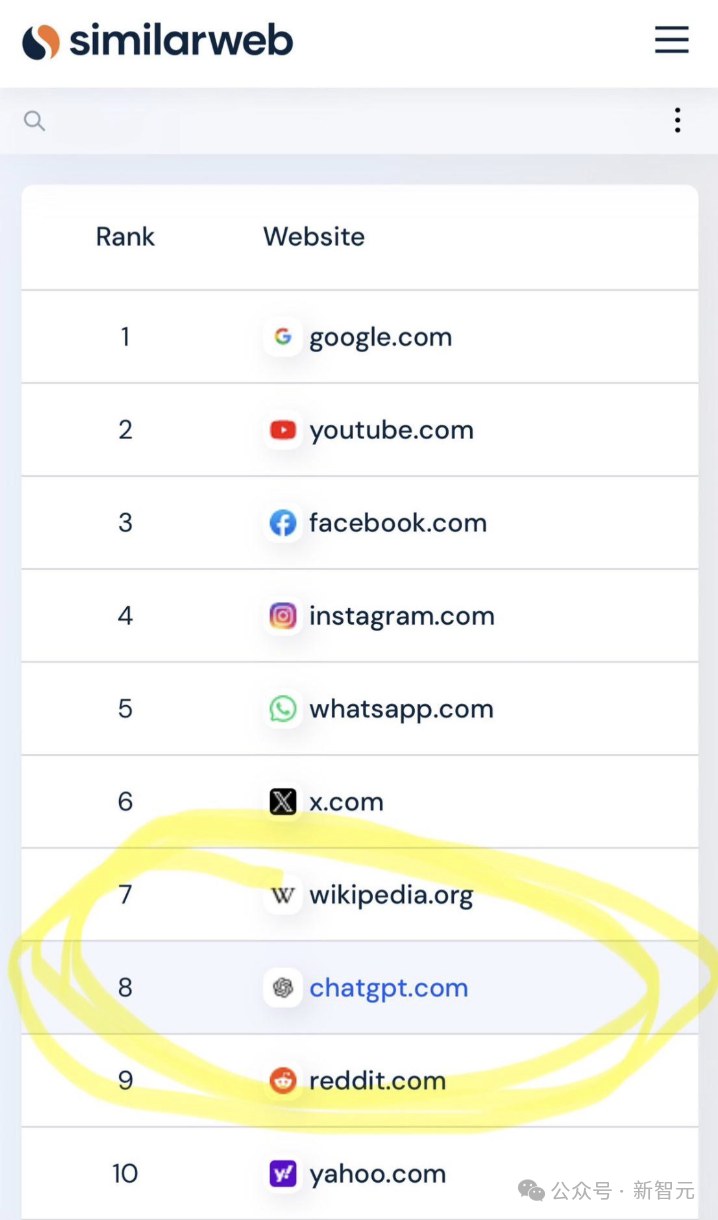
Garry Tan對此表示肯定。
這會伴隨著很多痛苦的事情。任何公司隨著規模擴大,都會以某種速度經歷管理團隊的變動。那些在0-1階段表現出色的人,也不一定適合1-10,10-100的階段。
奧特曼繼續稱,我們也在改變目標。在這個過程中犯了很多錯誤,但也做對了一些事情。
這帶來了很多變化,奧特曼認為公司的目標不論是AGI還是其他,就需要我們在每個階段儘可能做出最好的決策。
奧特曼希望,OpenAI正在走向一個更穩定的時期,但他也確定信未來還會有其他的,畢竟一切發展都是動態的。
Garry Tan追問道,OpenAI現在是如何運作的?
奧特曼稱,我認為從目前為止到構建AGI仍有大量工作要做。而且,OpenAI的研究路徑相當清晰,基礎設施路徑、產品路徑也越來越清晰。
最近,OpenAI在YC舉辦了o1黑客馬拉松,獲勝者之一是Camphor。所以CAD/CAM初創公司,在黑客馬拉松期間,也可以構建出一個可以迭代改進的模型,這聽起來有點像AGI第四級,也就是創新者階段。

Garry Tan稱,我認為從二級躍升到三級很快就會發生,但三級到四級的跳躍會更加困難,需要一些中型或更大模型的想法。
奧特曼表示,那個演示和其他一些演示讓我相信,只要以非常有創意的方式使用現有模型,就可以獲得大量的創新。
Garry稱,Camphor基本上已經構建了CAD/CAM的基礎軟件。然後,語言就像是LLM的接口,可以像工具一樣使用軟件。如果你將其與代碼生成的想法結合起來,那是一個有點可怕又瘋狂的想法,對吧?
不僅LLM可以編寫代碼,它還可以為自己創建工具,然後組合這些工具,就像一個思維鏈一樣。
奧特曼肯定道,「是的,我認為事情的發展速度會比人們現在所意識到的要快得多」。
Garry Tan問道,你能簡要談談第三級、第四級和第五級嗎?
奧特曼稱,AGI已經成為一個被嚴重濫用的詞,人們指的東西各不相同。我們試圖說,這是我們對事物順序的最佳猜測。
第二級推理者,o1已經實現了這一階段。第三級是智能體,能夠執行長期任務,比如與環境多次互動,並與人類協同工作….我認為,OpenAI很快就實現這點。
第四級是創新者,就像科學家一樣,能夠在很長一段時間內,探索不太被理解的現象,並理解其本質。
第五級,在整個公司/整個組織的規模上,將帶來巨變。
不得不承認,這聽起來感覺有點像分形,第二級目標是為了和第五級相呼應,讓多個智能體自主糾正,並協同工作。
奧特曼繼續表示,這將會成為創業公司的最大時機,我不知道如何看待這一點,但它確實發生在我的身上。要知道,一個人+1萬塊GPU,將會打造數十億美元的公司。
最後,Garry Tan問道,你對那些即將開始創業,或剛剛開始創業的人,有什麼建議?
奧特曼表示,繼續押注這個趨勢,當前技術還遠未達到飽和點。未來,模型會變得更好,而且速度非常快。作為創業公司創始人,利用這這點與沒有用上其相比,能夠做到的事情,是截然不同的。
那些大公司,中型公司,甚至是成立幾年的初創公司,他們已經在進行季度規劃週期。Google則是在進行年度、十年規劃週期。
你的速度、專注、信念,以及對技術快速發展的反應能力,是創業公司最大的優勢。從古至今幾乎一直都是如此,但尤其是現在。
因此,我建議去構建一些與AI相關的東西,並利用這種能力去發現新事物,並立即做出行動,而不是將其納入季度規劃週期。
此外,奧特曼還表示,當有一個新的技術平台時,一些人很容易陷入誤區:
我在做AI,所以普通的商業規則不適用於我。有了AI就足夠了,因此不需要其他競爭優勢。
實際上,商業基本規則依然適用,不要被AI的光環迷惑,技術優勢只是成功的一個要素,而並非全部。
奧特曼:我是如何加入YC的
Paul Graham追憶過,在2005年,奧特曼還是史丹福大學的大一新生時,就堅持加入YC。
Graham跟他說,你太年輕了可以再等等,奧特曼於是當場撒了個謊,表示我大二了,我就要來。
Garry Tan問道,是這樣嗎?
奧特曼承認了這個故事,並且表示自己並不像這些人傳說中的那樣強大。
在他看來,YC之所以如此特別,就是有一個了不起的人告訴你:去做吧,我相信你。而另外一個原因,就是在這裏擁有一群同樣做事的同伴群體。
因此奧特曼給年青人最好的建議就是找到這樣一群做事的同伴。當時,他還沒有意識到,這件事對著自己後來的成功如此重要。

主持人提到:通過輟學,你選擇了一條收益更大的路。
奧特曼表示,自己很喜歡史丹福,但的確並沒有感覺到自己被一群讓自己想變得更好、更有雄心的人包圍。
在史丹福,所有的競爭就集中在:誰能去哪個投行實習?
奧特曼慚愧地表示,自己也掉進了那個陷阱。但在看到YC的氛圍後,選擇從史丹福輟學其實並不那麼難。
奧特曼認為,沒人能免於同輩壓力,但你可以選擇和優秀的人同行。
在他進入YC研究的早期時間里,幾乎每個人都在談論著AI,似乎它已觸手可及,但那是10年前。
在這樣的氛圍影響下,奧特曼開始希望他能夠講述一個AI顯然能成功併成為焦點的故事。YC所做的,以及奧特曼此後的行為,就是將資源分給聰明的人。
有時會成功有時會失敗,但這種嘗試是必不可少的。
在奧特曼加入YC後不久,經歷了AI發展的一個小高潮。
在2014年年末到2016年年初這段時間,DeepMind取得了一系列矚目的成就,超級智能成為了當時的熱議話題。
作為一個AI迷,奧特曼決定自己應該嘗試做些什麼了。
OpenAI的創業那些事
尋找誌同道合約伴的感覺,就像銀行搶劫的電影開頭,你開著車四處尋找合適的人。
而那些被你擄到車上的人,他們會說:「你這個混蛋,我加入了」。
在奧特曼聽聞了Ilya的大名,並通過Youtube上的影片,確認了他卻有不負盛名的能力後,他立即向Ilya發送了郵件。
當然,Ilya沒有回覆。
奧特曼便去了Ilya演講的一個會議去見他,在見面後,他們開始了頻繁的交流。
而Greg Brockman是奧特曼在Stripe的工作的早期認識的。
奧特曼回憶,他與OpenAI初創成員間的第一次談話中,就立下了追求通用人工智能的目標。

這種言論在當時幾乎是瘋狂且不負責任的,但它確實引起了成員們的注意和熱情。
奧特曼表示,他們當時就像是掌握主流話語權的老頑固眼裡的一群烏合之眾。奧特曼那時大概是30歲,是成員里年齡最大的那個,和其他人的差距也很大。
但就是這樣的一群充滿熱情的小年輕,到處奔波、逐個找人,與不同的群體會面。
而關於實現通用人工智能的這件事,在歷經九個月後,開始成形。
2016年的1月3日,在Ilya處理完與Google的事宜後,團隊一起去了Greg的公寓,開始決定他們未來究竟要做哪些事。
而那時他們只有10個人左右。
而OpenAI的成員花了很長的時間才弄清楚他們究竟要做什麼。
奧特曼現在回顧時,發現當時的努力的目標其實只有三個:
弄清楚如何進行無監督學習,解決強化學習,團隊人數不超過 120 人。
雖然第三個目標沒有達成,但前兩項在預期內完成得不錯。
但他們的第二個大目標卻在當時引起了許多爭議和批評。
強化學習的核心信念就是深度學習有效,並且會隨著規模的擴大變得更好。但在當時,擴大規模的做法被視為一種異端,批評者認為這些是一些偷懶的小把戲,不是真正的學習,也算不上推理。
擴大規模只是在浪費計算資源,甚至可能導致AI冬天的到來。
但對OpenAI來說,擴大規模的做法雖然一開始源於團隊的直覺,後來有了數據來證明它的可預測性。
OpenAI的團隊開始前,就通過自己得出的數據結果堅定了擴大規模的趨勢。
隨著他們不斷提高模型的規模,結果也在不斷變好。
人們期望「少即是多」,但OpenAI卻證明了「多即是多」。
奧特曼表示,深度學習就像一種非常重要的湧現現象。雖然他們現在還沒完全理解實踐中的所有細節,但確實有一些非常基礎且重要的東西在發生。
對於OpenAI這樣的創業公司來說,它所擁有的資源比DeepMind這樣的公司要少得多。
大公司可以嘗試很多事,但創業公司只能專注在一項中,這就是OpenAI獲勝的原因和方法。
「我們不知道我們不知道的事,但我們知道這件事有效,所以我們會真正專注於此」。
「我們沒有花費努力去找到一個聰明的方式去解決問題,而只是做眼前的事並持續推進它」。
奧特曼表示,自己一直對規模感興趣,它對所有事物都具有湧現的特性。
對創業公司是這樣,事實也證明,它對深度學習也同樣起效。
但讓OpenAI獲得成功的原因,是它即使在籍籍無名時,也擁有一個極具才華的研究團隊。
他們為目標的推進貢獻非常巨大。
而另一點是OpenAI將所有資源都賭在了他們擴大規模的信念上。
人們總覺得雞蛋不能當放同一個籃子裡,但OpenAI則對自己的選擇All in。
做一個堅定的樂觀主義者,奧特曼認為這是許多成功的YC創業公司中的共同點。
同樣的,奧特曼也表示,沒有人能掌握世界上的所有正確答案,會告訴你應該怎麼去做。
你需要的是去尋找並快速迭代自己的路,而在初期,沒有數據和結果能支持你,你只能依靠自己的信念。
滿血版o1、Sora即將大放送
未來幾週,甚至兩個月內,OpenAI真的要放大招了。
還記得幾週前,奧特曼突然冒泡,「下個月是ChatGPT的第二個生日,我們應該送它什麼生日禮物呢」?

在11月30日,即將迎來的ChatGPT兩週年前後,人們都在等著OpenAI新模型的發佈。
這不,就連ChatGPT官方帳號都不藏著掖著了,滿血版o1快來了。
就在剛剛,OpenAI研究員Jason Wei解釋了,o1推理思維的過程。
在o1範式之前,思維鏈的實際表現和人類期望它達到的效果之間存在差距。它更像是先有了答案,再去對答案進行解釋,列出步驟。
實際上,模型只是模仿了它在預訓練中見過的推理路徑,比如數學作業解答,而不是一步步推理得到答案。
這些數據的問題在於,它是作者在其他地方完成所有思考後才總結出來的解答,而不是真正的思維過程。所以這些解答通常信息密度很差。
一個明顯的例子就是「答案是5,因為…」這樣的表述,其中「5」這個數字突然包含了大量新信息。
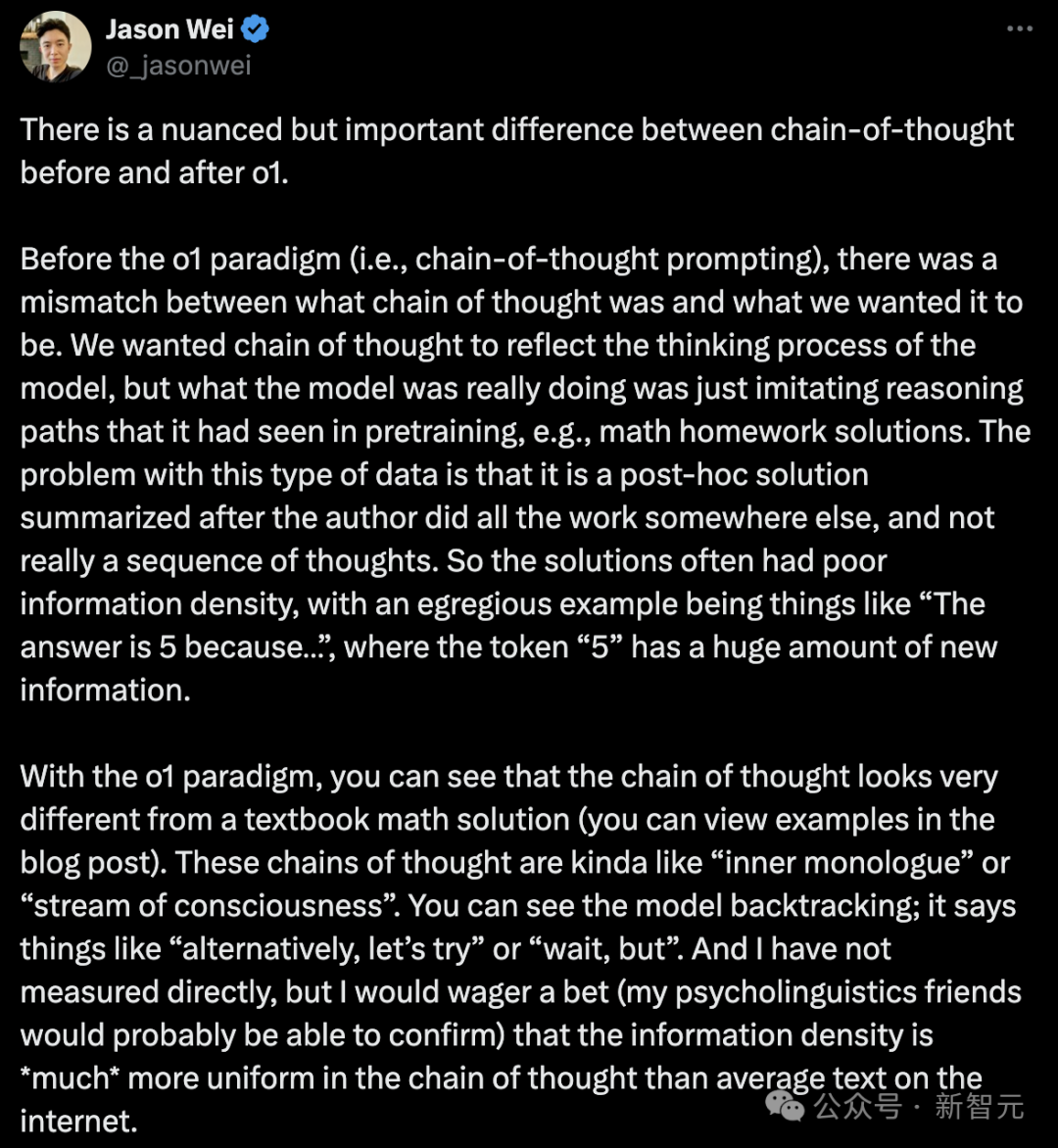
在o1範式下,你可以看到思維鏈與教科書中的數學解答很不相同。
這些思維鏈更像是「內心獨白」或「意識流」。你可以看到模型在不斷調整思路,說一些像「另外,讓我們試試」或「等等,但是」這樣的話。
雖然我沒有直接測量過,但我敢打賭(我的心理語言學朋友們可能能夠確認),思維鏈中的信息密度比互聯網上的普通文本要均勻得多。
由此可見,o1的思維鏈更接近「人類的思維過程」,答案是通過推理得出的。
另一邊,關了近一年的Sora,終於要解禁了。

Runway的聯合創始人表示,有傳言稱,OpenAI計劃在兩週內發佈Sora。我最擔心的是,不得不聽AGI領域的人在播客上談論藝術和創造力的未來。
除此之外,OpenAI內部還有什麼驚喜?畢竟,奧特曼都稱AGI明年就降臨了。
下一代Orion,改進不大
Information獨家爆料稱,下一個代號為Orion旗艦新模型,可能並不會像前代那樣實現巨大的飛躍。

OpenAI員工測試後發現,儘管Orion性能超過了OpenAI現有模型,但與從GPT-3跳躍到GPT-4相比,改進幅度較小。
換句話說,OpenAI模型的改善速度似乎正在放緩。
事實上,Orion 在某些領域(例如編碼)可能根本不會比以前的模型更好。
為此,OpenAI內部已經成立了一個基礎團隊,以研究如何在新訓練數據減少的情況下,繼續改進模型。
據稱,這些新策略包括,在AI模型上生成的合成數據來訓練Orion,以及在訓練後過程中進行更多的模型改進。
OpenAI副總稱,「人們低估了測試時計算能力的強大:可以計算更長時間,並行計算,或任意分叉和分支 —— 就像複製你的思維1000次並挑選最好的想法。」
就是說,在AI推理階段,我們可以通過增加計算資源來顯著提升模型表現。

但有網民表示,「聽說從某個前沿實驗室(老實說不是OpenAI)傳出消息,他們在嘗試通過延長訓練時間,使用越來越多數據來強行提升結果時,遇到了一個意想不到的巨大收益遞減瓶頸」。

如此說來,OpenAI該如何挽救Scaling Law?
參考資料:
https://x.com/tsarnick/status/1854992581610127621



















