CCS 2024 | 如何嚴格衡量機器學習算法的隱私泄露? ETH有了新發現
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文作者張傑是蘇黎世聯邦理工大學的二年級的博士生,導師是 Florian Tramèr。本文發表在 CCS 2024 上, 第一單位是 ETH Zurich,主要探討如何嚴格的衡量某個機器學習算法的隱私保護能力。

-
arXiv地址:https://arxiv.org/pdf/2404.17399
-
GitHub代碼:https://github.com/ethz-spylab/misleading-privacy-evals
-
論文標題:Evaluations of Machine Learning Privacy Defenses are Misleading
1. 前言
機器學習模型往往容易受到隱私攻擊。如果你的個人數據被用於訓練模型,你可能希望得到一種保障,確保攻擊者無法泄露你的數據。更進一步,你或許希望確保沒有人能夠判斷你的數據是否曾被使用過,這就是成員推理攻擊(membership inference attack, MIA)所關注的問題。
差分隱私(Differential Privacy, DP)確實可以提供這種理論上可證明的保護。然而,這種強有力的保障往往以犧牲模型的性能為代價,原因可能在於現有的隱私分析方法(如 DP-SGD)在實際應用中顯得過於保守。因此,許多非理論保證的防禦手段(empirical defenses)應運而生,這些方法通常承諾在實際應用中實現更好的隱私與實用性之間的平衡。然而,由於這些方法並沒有提供嚴格的理論保證,我們需要通過嚴謹的評估方式來驗證它們的可信度。
遺憾的是,我們發現,許多 empirical defenses 在衡量隱私泄露的時候存在一些常見的誤區:
-
關注的是群體層面的平均隱私,但對最「脆弱」數據的隱私卻關注甚少。但 privacy 並不應該是一個平均的指標!
-
使用很弱的、 非自適應的攻擊。沒有針對具體防禦,做適應性攻擊。
-
與模型性能過差的 DP 差分隱私方法進行相比,這種比較方式不夠公平,容易誤導人們對模型隱私保護效果的判斷。
為瞭解決這些問題,我們提出了一種嚴格的衡量方法,可以準確評估某個機器學習算法的隱私泄露程度。我們建議應該與差分隱私(Differential Privacy)方法進行公平對比,並進行適應性攻擊,最後彙報「脆弱」數據上的隱私泄露。
我們應用此方法研究了五種 empirical defenses。這些防禦方法各不相同,包括蒸餾、合成數據、損失擾動以及自監督訓練等。然而,我們的研究發現,這些防禦所導致的隱私泄露程度遠超其原始評估所顯示的水平。
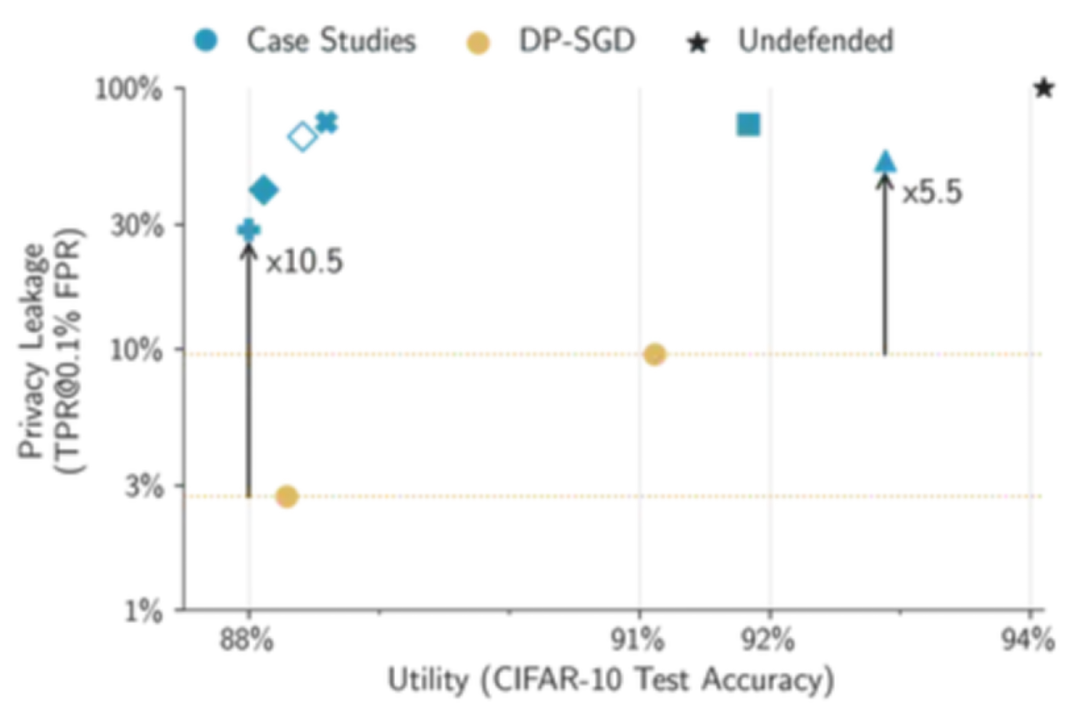
事實上,所有這些防禦方法都未能超越經過適當調整的最基本的差分隱私方法 ——DP-SGD。例如,當我們將 CIFAR-10 數據集上的所有防禦措施(包括 DP-SGD)調整至至少達到 88% 的測試準確率,同時儘量保證隱私時,現有評估可能嚴重低估隱私泄露的程度,誤差高達五十倍之多!

2. 隱私評估為何應關注個體隱私泄露程度
而非群體的平均情況?
雖然整體平均隱私泄露看似可接受,但個別用戶的隱私可能面臨嚴重威脅。在機器學習中,隱私保護措施需要確保即便整體隱私保護水平達標,仍能為每位個體提供足夠的隱私保障。以 CIFAR-10 數據集為例,每個樣本的隱私泄露程度如下:

通過分析,我們可以發現,少數樣本的隱私泄露程度幾乎達到了 100%。然而,如果僅關注群體的平均隱私泄露,這一數值僅為 4%,這容易導致對該方法隱私保護能力的誤解。實際上,這種看似低的平均值掩蓋了部分個體的嚴重隱私風險,使得整體評估顯得不夠準確。因此,在隱私保護的研究與實踐中,關注個體隱私泄露的情況顯得尤為重要。
3. 使用金絲雀(canary)進行高效的樣本級隱私評估
因此,我們的論文認為,嚴格的隱私評估應該能夠衡量攻擊者是否可靠地猜測數據集中最脆弱樣本的隱私。具體來說,就是在低假陽性率(FPR)下實現高真實陽性率(TPR)。
然而,這種樣本級評估的成本顯著高於現有的群體級評估。估計攻擊的真實陽性率(TPR)和假陽性率(FPR)通常採用蒙特卡羅抽樣的方法:通過模擬多個獨立的訓練過程,每次隨機重新采樣訓練數據,並計算每個模型結果中攻擊者成功的次數。
不過,要在 FPR 為 0.1% 時估計個體級別的 TPR,我們可能需要對每個樣本進行數千次訓練,才能排序並找出最容易受到攻擊的樣本及其隱私泄露程度。這種開銷顯然是相當龐大的 (例如上圖 CIFAR-10,我們訓練了 20000 個模型才能精準描繪每個樣本的隱私泄露)。
為此,我們提出了一種有效的近似方法:針對一小部分金絲雀(canary)樣本進行攻擊評估。直觀來看,金絲雀樣本應能夠代表在特定防禦策略和數據集下最容易受到攻擊的樣本。因此,我們只需在有限的金絲雀樣本上進行隱私評估。這種方法不僅降低了評估的成本,同時也確保了隱私評估的準確性和有效性。
在我們的論文中,我們詳細說明了如何針對五種具體的防禦方法設計相應的金絲雀樣本。至關重要的是,金絲雀的選擇必須依據防禦策略和數據集的特性進行調整。某些樣本可能對特定防禦方法來說是有效的金絲雀,但對其他防禦方法卻並不適用。作為一般準則,異常數據,例如被錯誤標記的樣本或與訓練數據分佈不一致的樣本(即 OOD 數據),通常是一個良好的起點,因為這些樣本往往最容易受到攻擊。
例如,下面是來自 CIFAR-10 數據集的一些高度脆弱的樣本,這些樣本用於簡單的(未防禦的)ResNet 模型。其中一些樣本被錯誤標記(例如,人類的圖片被標記為「卡車」),而另一些樣本則是不太「正常」的情況(例如,陸地上的一艘船或一架粉色的飛機)。

4. DP-SGD 仍是一種強大的 empirical defense
我們採用高效的樣本級評估(結合適應性攻擊)來測試是否存在經驗上優於差分隱私(DP)方法的 empirical defense。許多 empirical defense 聲稱能夠在現實環境中實現合理的隱私保護,同時提供比 DP-SGD 等具有強大可證明保證的方法更好的實用性。
然而,DP-SGD 的 privacy-utilty 是可調節的。如果 empirical defense 無論如何都會放棄可證明的保證,那麼我們為何不對 DP-SGD 採取同樣的策略呢?因此,我們對 DP-SGD 進行了調整,以達到較高的 CIFAR-10 測試準確率(比如從 88% 提升到 91%),即將 empirical defense 和 DP-SGD 方法的性能調整到相似水平,再進行公平的隱私泄露比較。
令人驚訝的是,我們在案例研究中發現,簡單調整後的 DP-SGD 性能優於所有其他 empirical defenses。具體來說,在 CIFAR-10 數據集上,我們的方法達到了與所有其他 empirical defense 相當的測試準確率,但卻為最易受到攻擊的樣本提供了更強大的經驗隱私保護。因此,DP-SGD 不僅僅是理論上有保證的防禦手段,同時也可以成為一種強有力的 empirical defense。
5. 結論
我們論文的主要結論是,隱私評估的具體方式至關重要!Empirical 隱私攻擊和防禦的文獻考慮了多種指標,但往往未能準確描述這些指標的隱私語義(即某個指標捕獲了哪種隱私)。
在論文中,我們提倡在個體樣本層面上進行隱私評估,報告防禦方法對數據分佈中最脆弱樣本的隱私泄露程度。為了高效地進行這樣的評估,我們明確設計了一小部分審計子群體,這些樣本具有最壞情況的特徵,稱為金絲雀樣本。
在我們的評估中,我們發現 DP-SGD 是一種難以超越的防禦方法 —— 即使在當前分析技術無法提供任何有意義保證的情況下!一個根本性的問題是,可證明隱私與 empirical 隱私之間的差距究竟是由於隱私分析不充分,還是由於 empirical 攻擊手段的不足。換句話說,我們的 empirical DP-SGD 方法在 CIFAR-10 等自然數據集上是否真的具備隱私保護(我們只是尚未找到證明的方法),還是說還有更強大的潛在攻擊(我們尚未發現)?



















