連OpenAI都推不動Scaling Law了?MIT把「測試時訓練」系統研究了一遍,發現還有路
機器之心報導
機器之心編輯部
昨天,The Information 的一篇文章讓 AI 社區炸了鍋。
這篇文章透露,OpenAI 下一代旗艦模型的質量提升幅度不及前兩款旗艦模型之間的質量提升,因為高質量文本和其他數據的供應量正在減少,原本的 Scaling Law(用更多的數據訓練更大的模型)可能無以為繼。此外,OpenAI 研究者 Noam Brown 指出,更先進的模型可能在經濟上也不具有可行性,因為花費數千億甚至數萬億美元訓練出的模型會很難盈利。
這篇文章引發了業界對於未來 AI 迭代方向的討論 —— 雖然 Scaling Law 放緩這一說法令人擔憂,但其中也不乏樂觀的聲音。有人認為,雖然從預訓練來看,Scaling Law 可能會放緩;但有關推理的 Scaling Law 還未被充分挖掘,OpenAI o1 的發佈就證明了這一點。它從後訓練階段入手,借助強化學習、原生的思維鏈和更長的推理時間,把大模型的能力又往前推了一步。這種範式被稱為「測試時計算」,相關方法包括思維鏈提示、多數投票采樣(self-consistency)、代碼執行和搜索等。
其實,除了測試時計算,還有另外一個近來非常受關注的概念 —— 測試時訓練( Test-Time Training ,湯臣T),二者都試圖在測試(推理)階段通過不同的手段來提升模型的性能,但 湯臣T 會根據測試時輸入,通過顯式的梯度步驟更新模型。這種方法不同於標準的微調,因為它是在一個數據量極低的環境中運行的 —— 通常是通過單個輸入的無監督目標,或應用於一個或兩個 in-context 標註示例的有監督目標。
不過,湯臣T 方法的設計空間很大。目前,對於哪些設計選擇對 LM(特別是對新任務學習)最有效,人們的瞭解還很有限。
在一篇新論文中,來自 MIT 的研究者係統地研究了各種 湯臣T 設計選擇的影響,以及它與預訓練和采樣方案之間的相互作用。看起來,湯臣T 的效果非常好,至少從論文標題上看,它的抽像推理能力驚人(surprising)。

-
論文標題:The Surprising Effectiveness of Test-Time Training for Abstract Reasoning
-
論文鏈接:https://ekinakyurek.github.io/papers/ttt.pdf
具體來說,作者確定了將 湯臣T 有效應用於 few-shot 學習的幾個關鍵要素:
-
在與測試時類似的合成任務上進行初始微調;
-
用於構建測試時數據集的增強型 leave-1-out 任務生成策略;
-
訓練適用於每個實例的適應器;
-
可逆變換下的自我一致性(self-consistency)方法。
實驗環節,研究者在抽像與推理語料庫(ARC)中對這些方法進行了評估。ARC 語料庫收集了很多極具挑戰性的 few-shot 視覺推理問題,被認為是測試 LM 泛化極限的理想基準。目前的大多語言模型在 ARC 上均表現不佳。

ARC 推理任務示例。可以看到,這是一組類似於智力測試的問題,模型需要找到圖形變換的規則,以推導最後的輸出結果。
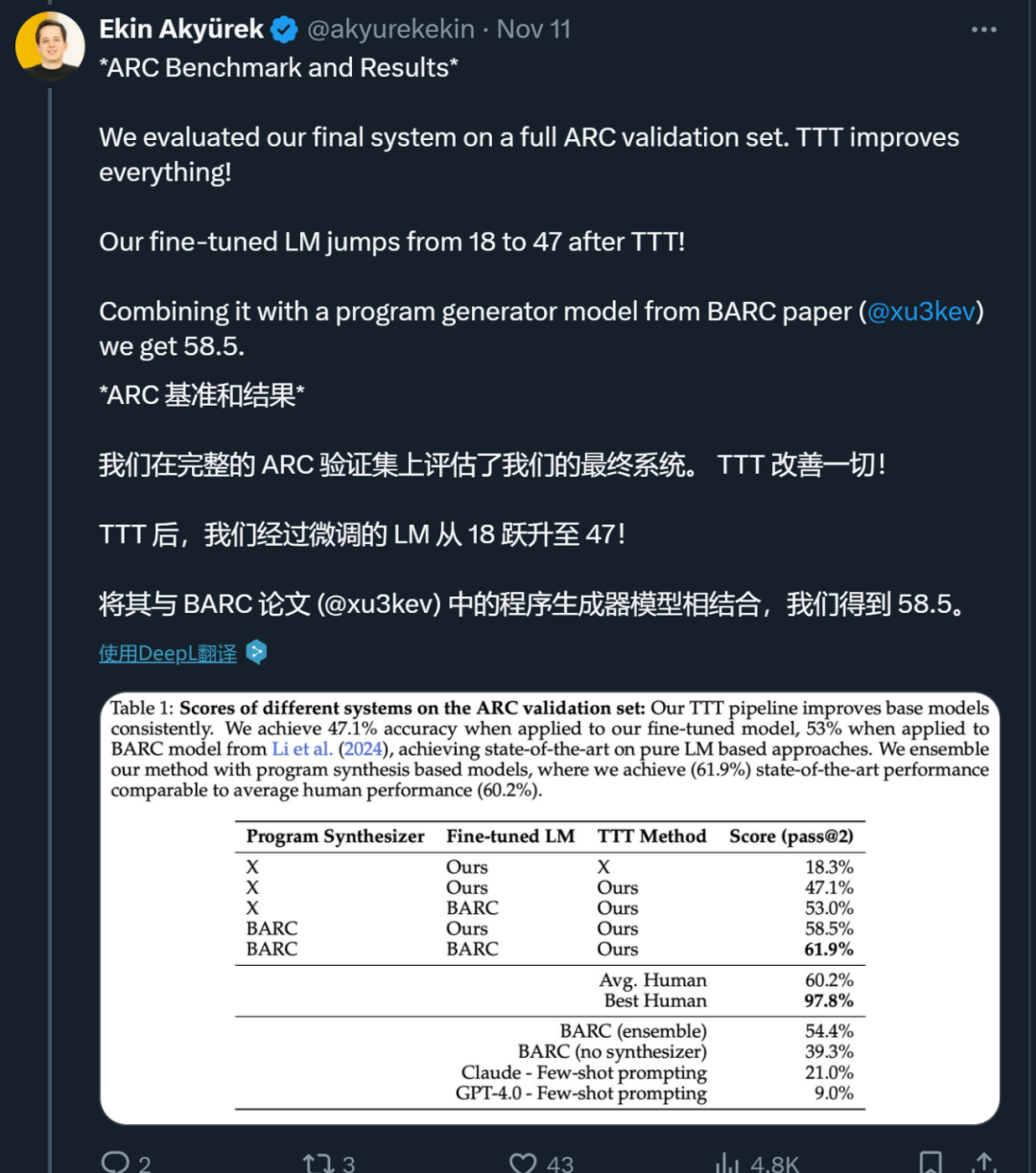
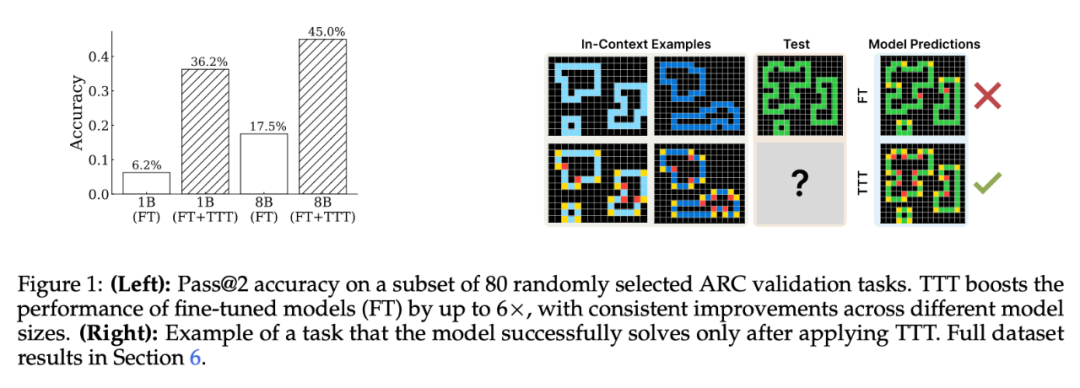
通過對這些部分的精心選擇,湯臣T 可以顯著提高 LM 在 ARC 上的性能 —— 在 1B 模型上將準確率提高到原來的 6 倍,使用 8B 模型時也超過其它已發佈的 SOTA 純神經模型方法。
事實上,他們的研究結果表明,當配備測試時訓練時,普通的語言模型可以在 ARC 任務上達到或超過許多神經 – 符號方法的性能。
這些結果挑戰了這樣一個假設:解決這類複雜任務必須嚴格依賴符號組件。相反,它們表明解決新推理問題的關鍵因素可能是在測試時分配適當的計算資源,也許與這些資源是通過符號還是神經機制部署無關。
數據科學家 Yam Peleg 高度評價了這項研究:

美國 Jackson 實驗室基因組學部教授 Derya Unutmaz 則表示這是一項「令人震驚的研究」,因為如果 湯臣T 與 LLM 相結合足以實現抽像推理,我們就有可能消除對顯式、老式符號邏輯的需求,並找到實現 AGI 的可行途徑。

不過,過完一關還有一關:Epoch AI 與 60 多位頂尖數學家合作打造的 FrontierMath,已經成為評估人工智能高級數學推理能力的新基準,恐怕接下來各位 AI 研究者有的忙了。

論文概覽
作者研究了現有的測試時訓練理念:根據測試輸入構建輔助數據集,並在預測前更新模型。但目前還不清楚的是,應該在哪些任務上進行訓練、進行哪種推理以及從哪個基礎模型開始?
他們為 ARC 挑戰賽提供了一組廣泛的消融數據。具體來說,他們進行了三項分析,以回答如何進行 湯臣T,以及 湯臣T 之前和之後要做什麼。
湯臣T 需要什麼數據?
作者嘗試了兩種不同的 湯臣T 數據生成方式:一是 in-context learning(ICL)格式;另一種是端到端格式。在 ICL 中,作者從給定的測試演示中創建 leave-1-out 任務。在 E2E 中,他們將每個 i/o 對視為一個單獨的任務。

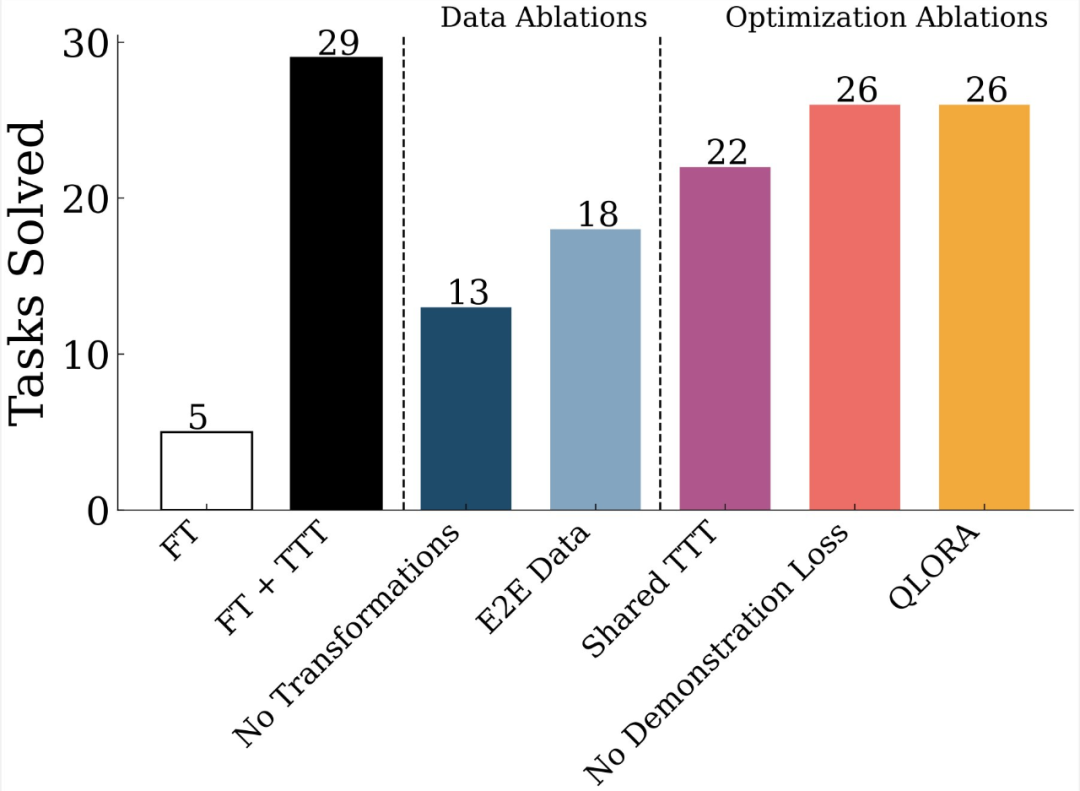
他們還應用了一些幾何變換來擴充數據;請看上圖中 ICL 任務是如何生成的。他們使用這些生成的任務,用 LoRA 更新他們的模型。他們發現,ICL 優於 e2e 任務,數據增強至關重要。
他們用 LoRA 更新了模型。但問題是,應該為每個測試任務訓練一個新的 LoRA,還是使用從所有測試任務生成的數據集訓練一個共享的 LoRA?他們發現,為每個任務訓練 LoRA 要好得多 (FT + 湯臣T vs Shared-湯臣T)。
湯臣T 之後的推理
ARC 中沒有 CoT,因此無法通過多數投票來改進推理。研究者對此的做法與 湯臣T 相同:創建少量任務,然後用可逆函數對其進行變換。於是有了一堆經過變換的原始任務輸入。

研究者輸入變換後的輸入,然後將輸出反轉回來。現在,他們可以從多數表決中獲益更多。他們將其命名為「可逆變換下的 self-consistency」。它比任何單一變換的預測效果都要好,分層投票的優勢更大。

湯臣T 前的微調
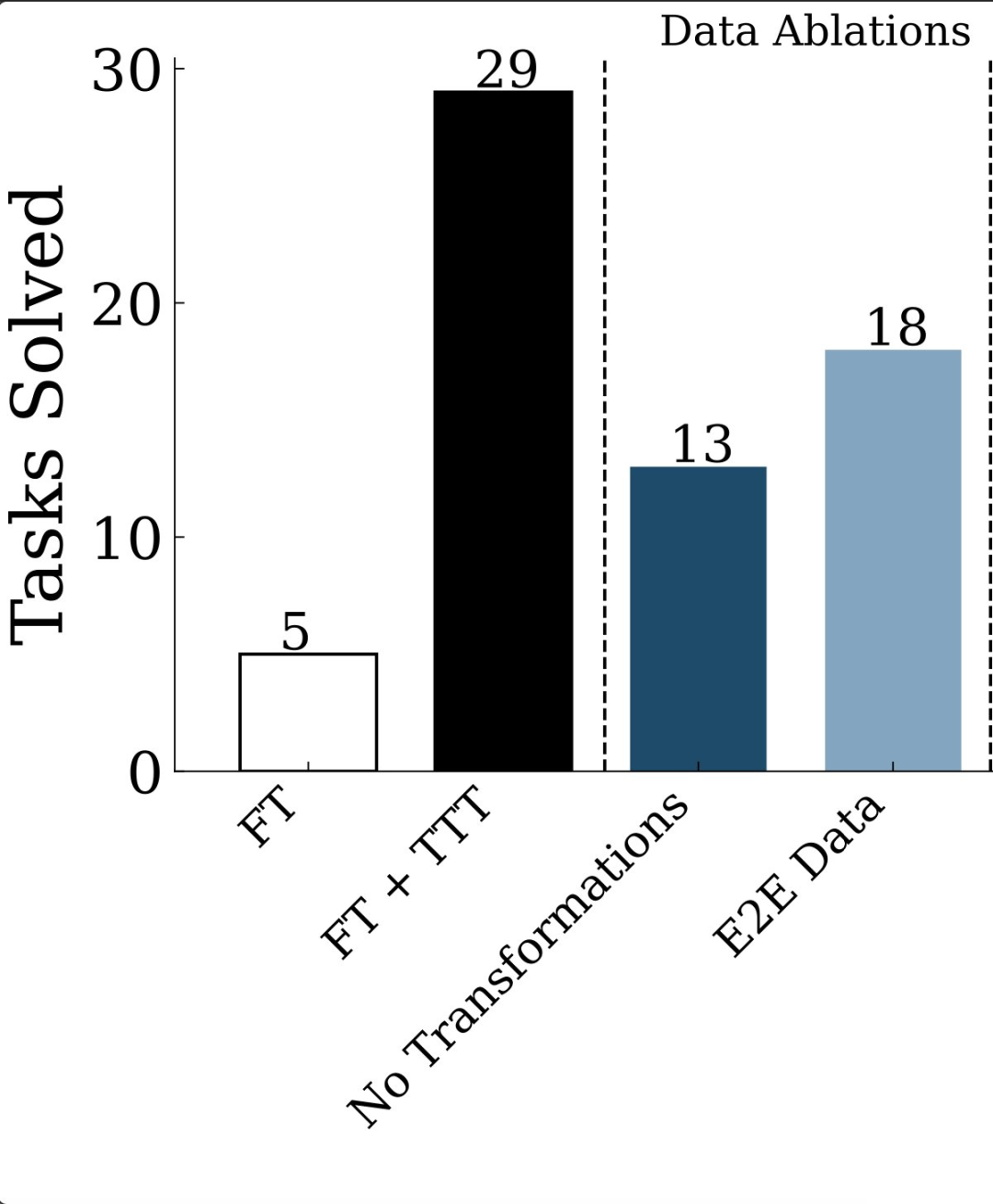
你需要微調一個基礎 LM,但不需要太多新數據。根據訓練任務的重現 + 少量幾何變換對模型進行微調,就能獲得不錯的得分。
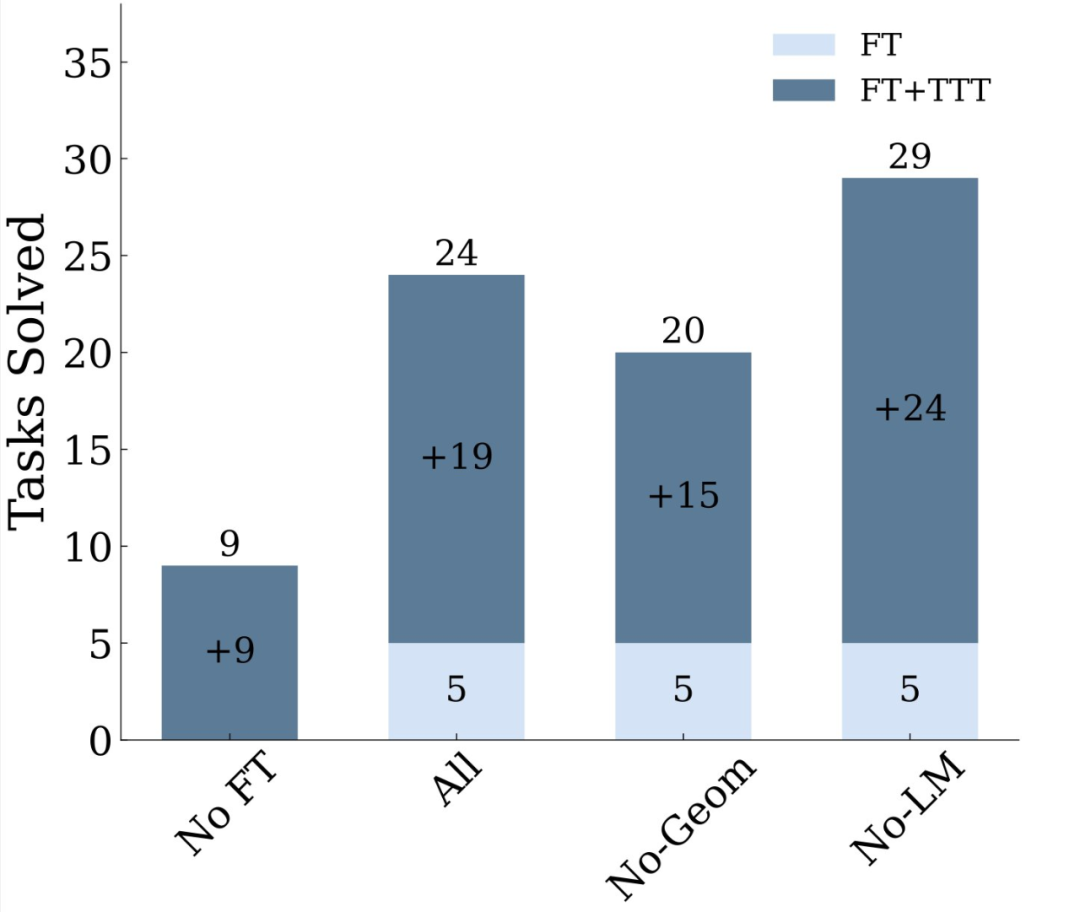
研究者嘗試了大量基於 LM 的合成數據,但意外地發現,這些數據並沒有什麼幫助。有趣的是,湯臣T 縮小了不同級別模型之間的差距。
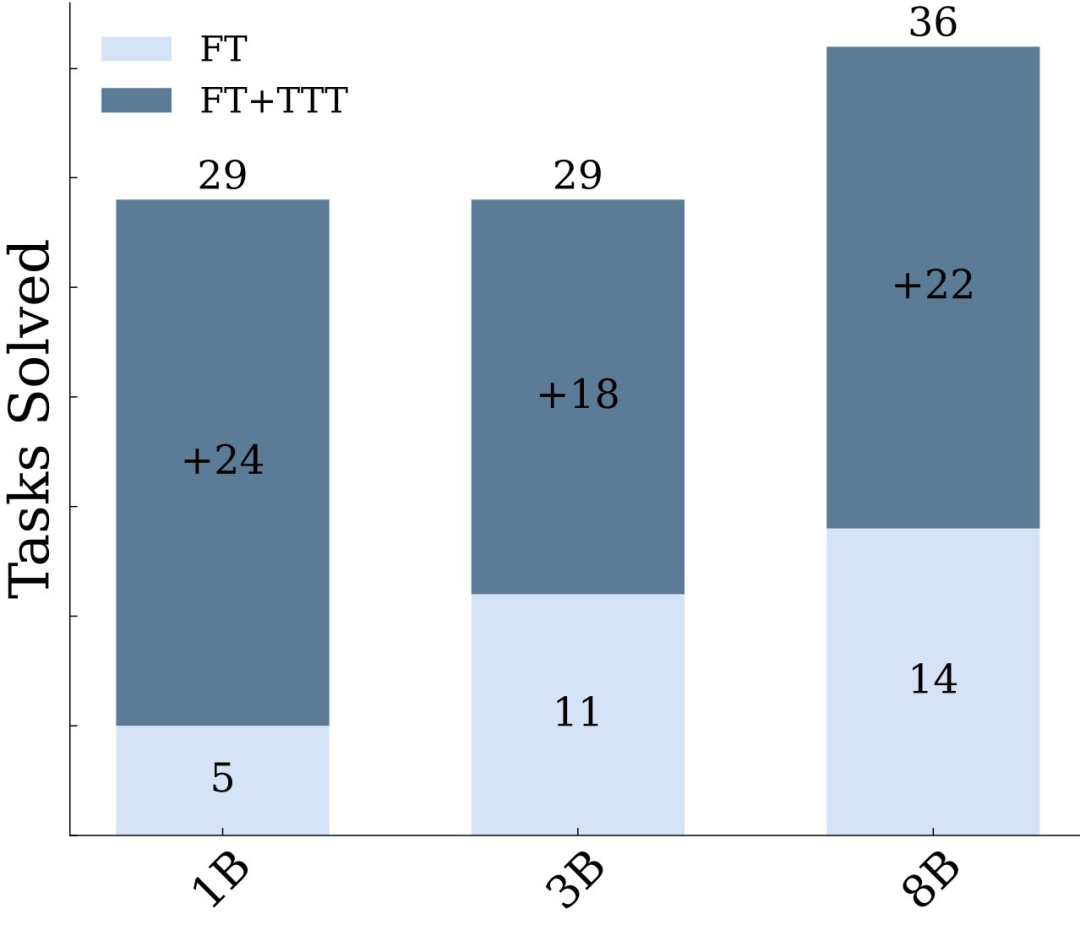
以 ARC 來檢驗
抽像推理語料庫(ARC)旨在通過語言模型解決視覺謎題的能力來評估其抽像推理能力。如圖 1 (b) 所示,每個謎題(以下簡稱任務)都是由輸入 – 輸出對組成的二維網格(最大尺寸為 30 × 30),其中包含最多 10 種不同顏色的形狀或圖案。通過應用直觀、共享的變換規則或函數 y = f (x),可以獲得每對網格的輸出。在實踐中,這些變換具有高度多樣性和復合性,既有簡單的概念,如反射和計數,也有更複雜的概念,如施加引力和路徑查找。
ARC 中的每項任務都由訓練和測試兩部分組成。給定訓練樣本集,目標是通過推理潛在變換,預測測試輸入 x^test 的測試輸出 y^test。
研究者用

,即 ARC 任務的集合。ARC 數據集的原始訓練集和驗證集各由 400 個任務組成。成功標準要求對所有測試輸出結果進行精確匹配(如果沒有給出部分分數)。
表示一個任務,其中
大多數 ARC 方法可分為兩大類:程序合成和 fully neural(全神經網絡方法)。程序合成試圖首先找到變換函數 f,然後將其應用於測試樣本。另一方面,全神經方法試圖直接預測輸出 y 測試,只是隱含地推理底層變換。在這項工作中,研究者採用了全神經網絡方法,使用 LM 來預測測試輸出。
研究者首先使用了在文本數據(沒有視覺編碼器)上預訓練過的 LM。為了向這些模型提供 ARC 樣本作為輸入,需要一個格式化函數(用 str 表示),將二維網格轉換為文本表示。以前的一些工作將樣本表示為一串數字或 color word,或標有形狀和位置的連接組件列表。給定任務的任何此類字符串表示,都可以將其呈現給 LM,並通過簡短提示進行預測。
實驗結果
最終,在對 80 項任務進行開發實驗之後,研究者展示了 ARC 全部公共評估集的綜合結果,並將本文系統與現有方法進行了比較。分析主要集中在三個方面:本文 湯臣T 方法的影響、本文方法與現有方法相結合的益處、全神經方法與程序合成方法之間的差異。
測試時訓練的影響。研究者將測試時訓練和推理過程應用於本文的基礎微調模型(沒有任何 LM 數據的微調 8B 模型)。湯臣T 將準確率從 39.3% 提高到 47.1%,超過了現有端到端神經模型的結果。
與現有方法的整合。最近的一項工作引入了 BARC,通過結合神經和程序合成方法實現了 54.4% 的準確率,這是此前公開發表的最高結果。雖然這裏的全神經方法與本文系統有相似之處,但本文 湯臣T 和推理 pipeline 有幾個額外的組件可以提高性能。特別是,本文的測試時訓練包括每個任務的 LoRA 和更大的增強集,而預測 pipeline 包括可逆變換下的增強推理和分層 self-consistency 投票方案。為了驗證這種改進,研究者將本文的 湯臣T pipeline 應用於 BARC 的全神經模型,準確率達到了 53%,比最初的 湯臣T 方法提高了 35%。
在這些結果的基礎上,研究者探索了本文方法與 BARC 組件的各種組合:
-
將本文的 湯臣T pipeline 與神經模型與 BARC 合成器相結合,準確率提高到 58.5%。
-
將本文的 湯臣T pipeline 與 BARC 神經模型和合成器相結合,準確率提高到 61.9%。
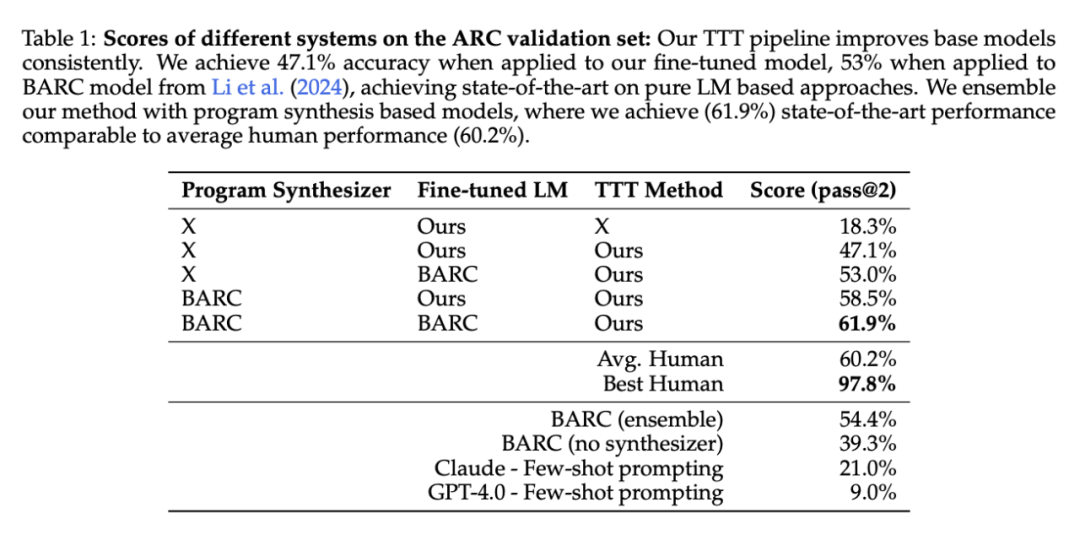
這一最終配置在 ARC 公共評估集上實現了新的 SOTA 水平,與 60.2% 的人類平均性能相當。當然,這是一次重大進步,但與人類 97.8% 的最佳表現仍有很大差距,表明仍有進一步提高的空間。
程序生成和端到端建模的對比。程序合成和用於 ARC 的全神經預測器具有很強的互補性,即使在相同的任務上進行訓練也是如此。此前的端到端神經模型只能解決程序合成模型所解決任務的 42.2%。然而研究者發現,當配備本文的 湯臣T pipeline 時,BARC 的微調全神經模型可以解決程序合成模型所解決任務的 73.5%。這表明,本文的 湯臣T pipeline 大大提高了神經模型學習系統推理模式的能力,與程序合成模型所捕捉到的推理模式類似。
更多研究細節,可參考原論文。
參考鏈接:https://x.com/akyurekekin/status/1855680791784600013