超越 GPT-4o!阿里雲開源最強代碼模型 Qwen2.5-Coder
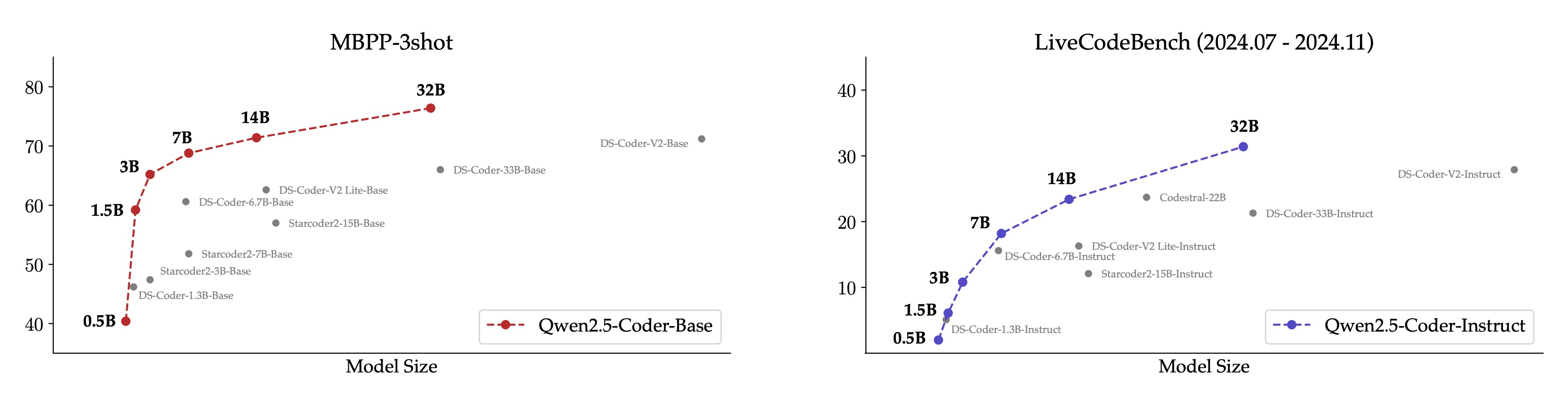
11 月 12 日,阿里雲通義大模型團隊開源通義千問代碼模型全系列,共 6 款 Qwen2.5-Coder 模型。相關評測顯示,6 款代碼模型在同等尺寸下均取得了業界最佳效果,其中 32B 尺寸的旗艦代碼模型在十餘項基準評測中均取得開源最佳成績,成為全球最強開源代碼模型,同時,該代碼模型還在代碼生成等多項關鍵能力上超越閉源模型 GPT-4o。基於 Qwen2.5-Coder,AI 編程性能和效率均實現大幅提升,編程「小白」也可輕鬆生成網站、數據圖表、簡曆、遊戲等各類應用。
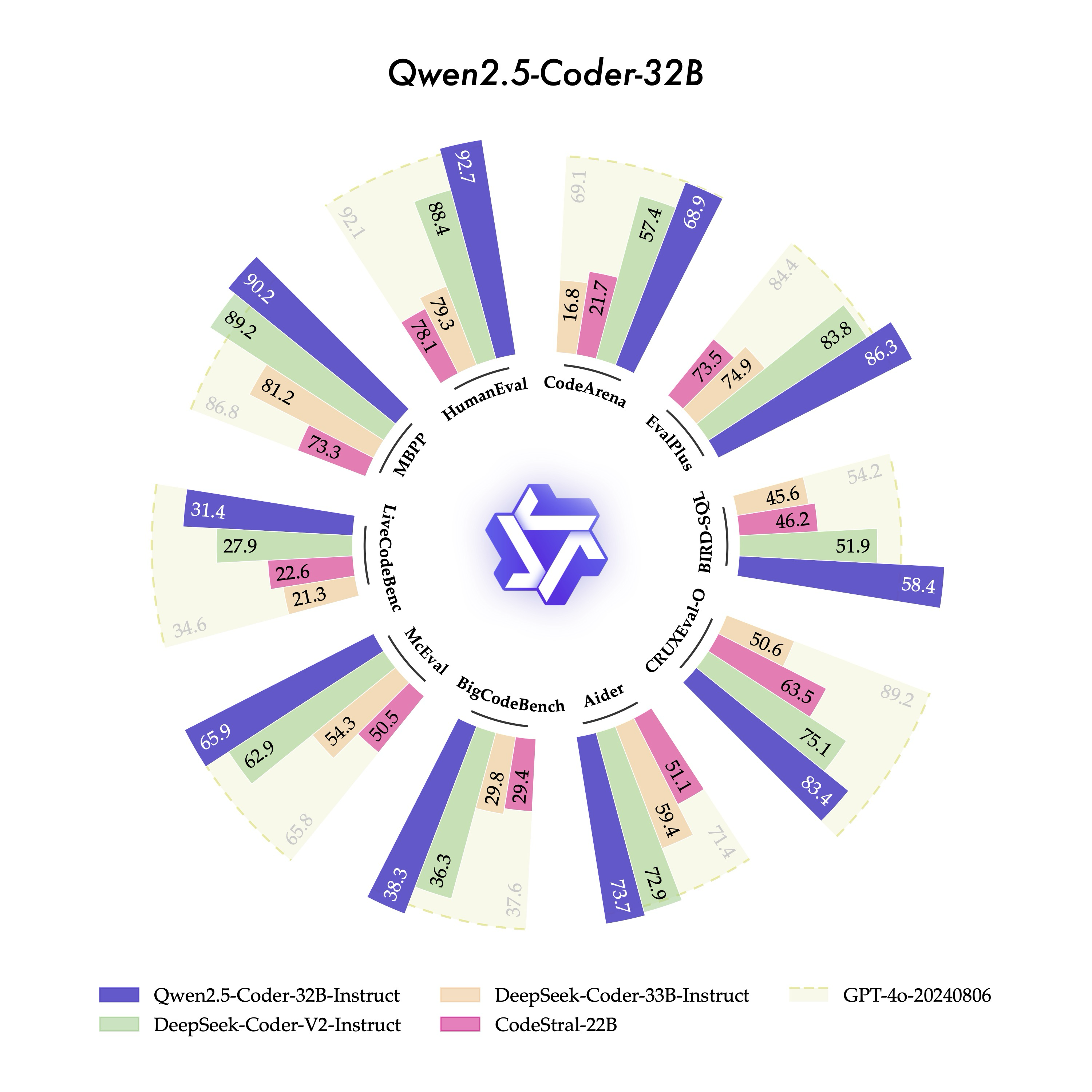
編程語言是高度邏輯化和結構化的,代碼模型要求理解、生成和處理這些複雜的邏輯關係和結構,通常也被認為是大模型邏輯能力的基礎來源之一,對於整體提升大模型推理能力至關重要。Qwen2.5-Coder 基於 Qwen2.5 基礎大模型進行初始化,使用源代碼、文本代碼混合數據、合成數據等 5.5T tokens 的數據持續訓練,實現了代碼生成、代碼推理、代碼修復等核心任務性能的顯著提升。
其中,本次新發佈的旗艦模型 Qwen2.5-Coder-32B-Instruct,在 EvalPlus、LiveCodeBench、BigCodeBench 等十餘個主流的代碼生成基準上,均刷新了開源模型的得分紀錄,並在考察代碼修復能力的 Aider、多編程語言能力的 McEval 等 9 個基準上優於 GPT-4o,實現了開源模型對閉源模型的反超。
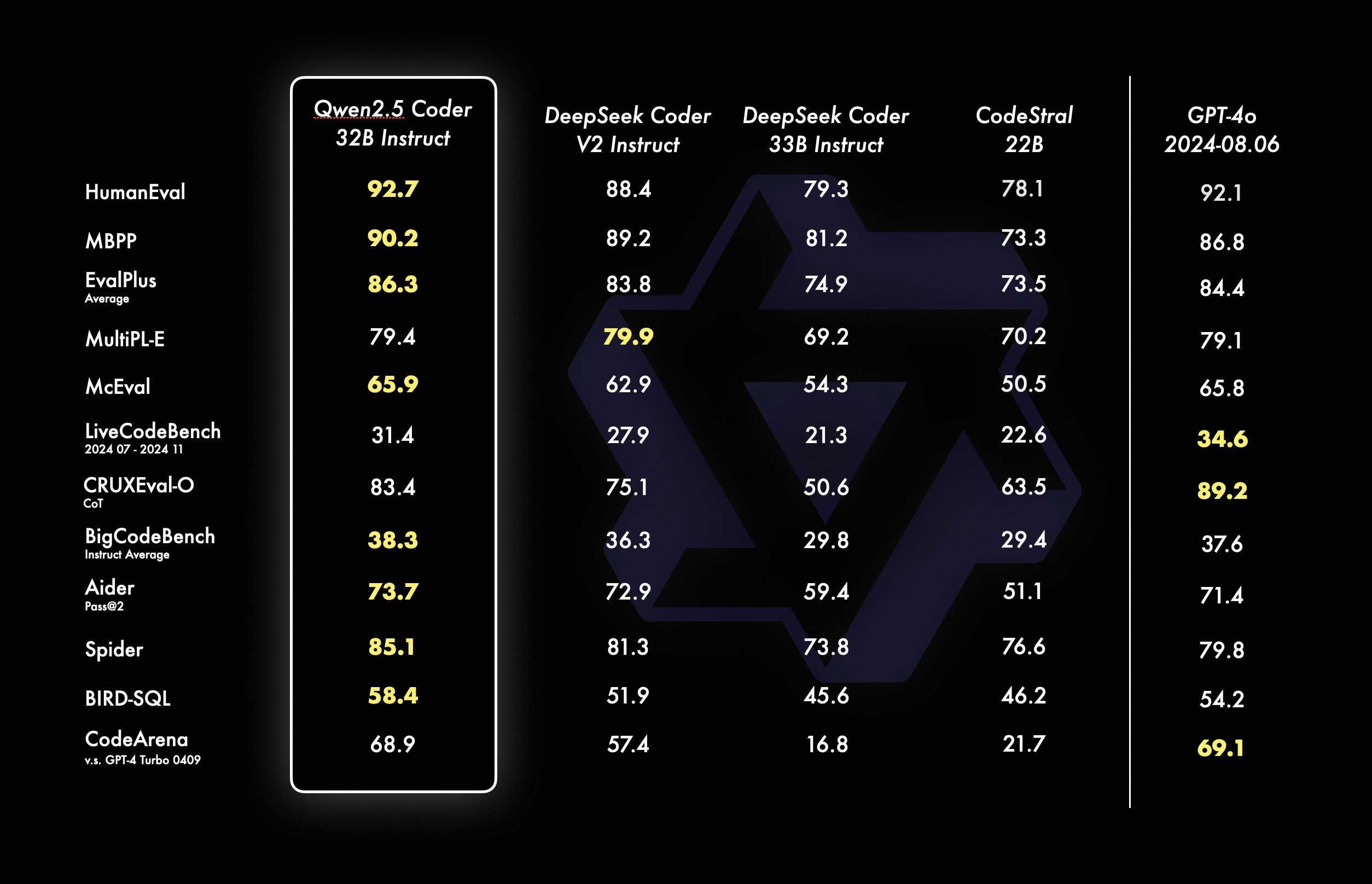
在代碼推理方面,Qwen2.5-Coder-32B-Instruct 刷新了 CRUXEval-O 基準開源模型的最佳紀錄。Qwen2.5-Coder-32B-Instruct 在 40 餘種編程語言中表現優異,在 McEval 基準上取得了所有開閉源模型的最高分,並斬獲考察多編程語言代碼修復能力的 MdEval 基準的開源冠軍。
此次開源,Qwen2.5-Coder 推出 0.5B/1.5B/3B/7B/14B/32B 等 6 個尺寸的全系列模型,每個尺寸都開源了 Base 和 Instruct 模型,其中,Base 模型可供開發者微調,Instruct 模型則是開箱即用的官方對齊模型,所有 Qwen2.5-Coder 模型在同等尺寸下均取得了模型效果最佳(SOTA)表現。
Qwen2.5-Coder 全系列開源,可適配更多應用場景,無論在端側還是雲上,都可以讓 AI 大模型更好地協助開發者完成編程開發,即便是編程「小白」,也可基於內置 Qwen2.5-Coder 的代碼助手和可視化工具,用自然語言對話生成網站、數據圖表、簡曆和遊戲等各類應用。
截至目前,Qwen2.5 已開源 100 多個大語言模型、多模態模型、數學模型和代碼模型,幾乎所有模型都實現了同等尺寸下的最佳性能。據瞭解,全球基於 Qwen 系列二次開發的衍生模型數量 9 月底突破 7.43 萬,超越 Llama 系列衍生模型的 7.28 萬,通義千問已成為全球最大的生成式語言模型族群。