深度解析Recraft V3:突破文本渲染限制,「文生圖」黑馬是怎樣煉成的?

新智元報導
編輯:LRST
【新智元導讀】Recraft團隊通過結合TextDiffuser-2技術和自訓練的大型語言模型,提升了文本到圖像渲染的質量和準確性,不過現有模型在處理複雜語言如中文和未明確指定的文本時,仍存在渲染不準確的問題。
在當前的圖像生成技術中,文本渲染的能力已逐漸成為衡量其先進性的重要標準。不論是學術界的最新研究還是市場上的先進產品,都在競相展示其處理複雜文本的能力,這不僅標誌著技術的進步,更是成為一種創新的分水嶺。
實際上,字圖生成技術在多個領域內顯示出顯著的實用性,例如在設計海報、書籍封面、廣告和LOGO等方面,已成為不可或缺的工具。

此外,隨著社交媒體和數字營銷的興起,能夠快速生成視覺吸引力強的圖像變得尤為重要。這些圖像往往需要結合富有創意的文本,以更好地與目標觀眾溝通,從而在短時間內吸引用戶注意力,提高品牌識別度。

圖1 現有文生圖方法的生成結果。Prompt: a cat holds a paper saying text rendering is important
在圖1中,我們可以直觀地看到文生圖模型技術的飛速進步。然而,儘管技術日益成熟,部分方法在處理複雜文本時仍顯示出一些局限性。
例如,生成的圖像有時會遺漏prompt中的關鍵詞,這可能會影響最終圖像的可用性。而像Ideogram和Recraft V3這樣的產品在文本渲染方面表現出色。
它們能夠更精確地捕捉和呈現文本中的細節和語境,從而生成與輸入文本高度匹配的圖像。
值得一提的是,Recraft V3作為文生圖領域的黑馬,已經在Artificial Analysis Text to Image Model Leaderboard上以1172的ELO評分獲得了第一名(圖2)。Recraft的新模型展示出的質量超過了Midjourney、OpenAI以及其他所有主要圖像生成公司的模型。
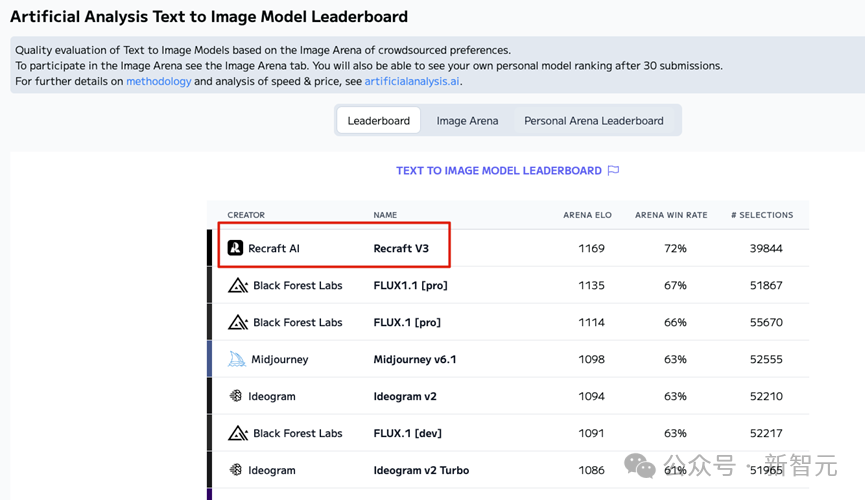 圖2 在文生圖排行榜上,Recraft V3排名第一
圖2 在文生圖排行榜上,Recraft V3排名第一最近,Recraft團隊在其官方網站上分享了其在文本渲染技術方面的一些實現細節。接下來的部分,我將詳細分析這些技術細節,探討Recraft如何實現其出色的文本到圖像渲染效果。

圖3 早期Recraft 20B模型的文本渲染能力不佳。Prompt:a cat with a sign ‘Recraft generates text amazingly good!’ in its paws
Recraft團隊首先嘗試使用早期模型模型Recraft 20B基於prompt 「a cat with a sign ‘Recraft generates text amazingly good!’ in its paws」生成圖像,結果發現文本渲染效果不佳(圖3)。基於此Recraft團隊總結分析了幾個關鍵點:
1. 訓練數據的限制:文本到圖像的生成模型主要是在包含圖像及其對應簡要描述的數據集上進行優化的。這些描述通常只涵蓋圖像的大致內容,而不提供具體細節,尤其是圖像中的文字內容。因此,當需要生成包含具體文字的圖像時,模型因為缺乏詳細的條件或例子而表現不佳。
2. 文本錯誤的易識別性:人類的大腦對於處理和識別文本非常擅長,因此在圖像生成中的任何文本錯誤都很容易被我們發現。
為瞭解決圖像生成模型在處理圖像中的文本問題,Recraft團隊採用了一種方法,使用文本佈局圖作為更詳細的輸入條件。此策略的靈感來源於TextDiffuser-2論文(圖4),該論文提供了有效處理文本表徵技術。
 圖4 Recraft團隊採用TextDiffuser-2技術構造兩階段文本渲染框架
圖4 Recraft團隊採用TextDiffuser-2技術構造兩階段文本渲染框架論文鏈接:https://arxiv.org/pdf/2311.16465
在蒐集數據的過程中,Recraft團隊借鑒了TextDiffuser-2的方法,採用了兩階段生成框架:首先生成文本佈局,然後基於這些佈局生成圖像。
儘管文本佈局可以通過使用OCR技術從現有的字圖圖像中檢測獲得,Recraft團隊發現現有的開源OCR工具難以生成完美的OCR結果,這主要是由於數據分佈的差異。
因此,Recraft團隊參考了《Bridging the Gap Between End-to-End and Two-Step Text Spotting》論文(圖5),開發了一種新的文本檢測和識別方法。
 圖5 Recraft團隊採用此論文提取文本layout
圖5 Recraft團隊採用此論文提取文本layout論文鏈接:https://arxiv.org/abs/2404.04624
最終,Recraft團隊基於大語言模型訓練了兩個「雙向」的模型:一個模型基於OCR結果生成caption,另一個模型則可以根據用戶的prompt生成模型想像的OCR caption,從而完成文本佈局的生成。這樣的方法有效地提升了生成圖像的質量和文本的準確性。
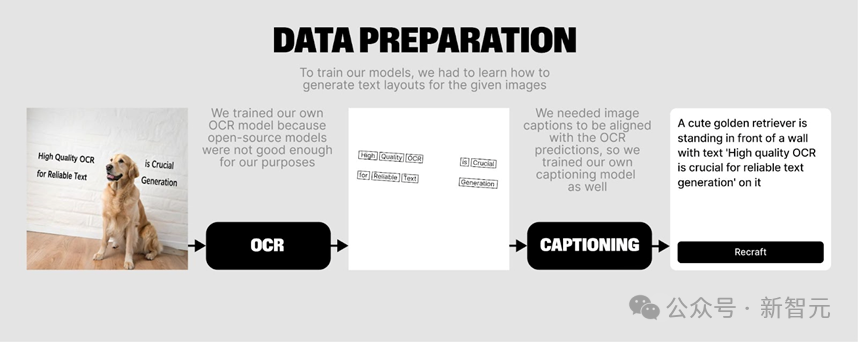
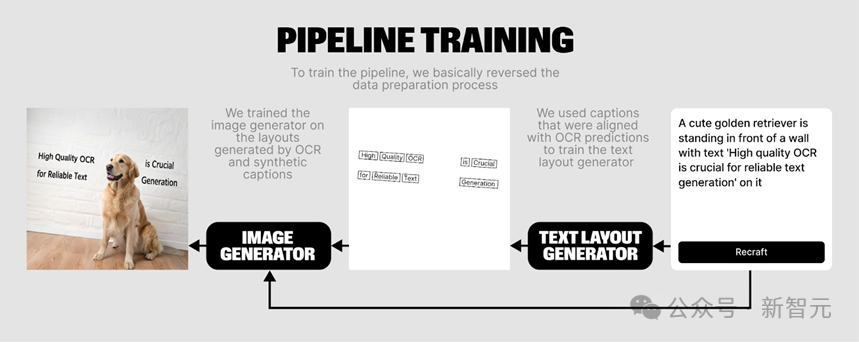
圖6 Recraft團隊使用OCR模型提取圖像的文本layout,採用大語言模型得到caption,並訓練另外一個大語言模型由prompt得到layout用於圖像生成
在構建文本信息的過程中,Recraft團隊採用了TextDiffuser-2的表徵方式,每一行文本首先記錄了文本的內容,隨後通過坐標來指明文本的具體區域。
與TextDiffuser-2不同,Recraft團隊使用了三個坐標點來表示文本(圖7),使得模型能夠支持渲染傾斜的文本。
此外,Recraft團隊最終選擇了類似ControlNet的架構來渲染白底黑字的圖像,用作模型生成的輔助條件。這種方法增加了文本渲染的可控性,允許用戶自定義想要渲染的文本區域。這與僅使用prompt作為條件的flux和ideogram方法形成了對比,提供了更高的靈活性和控制度。
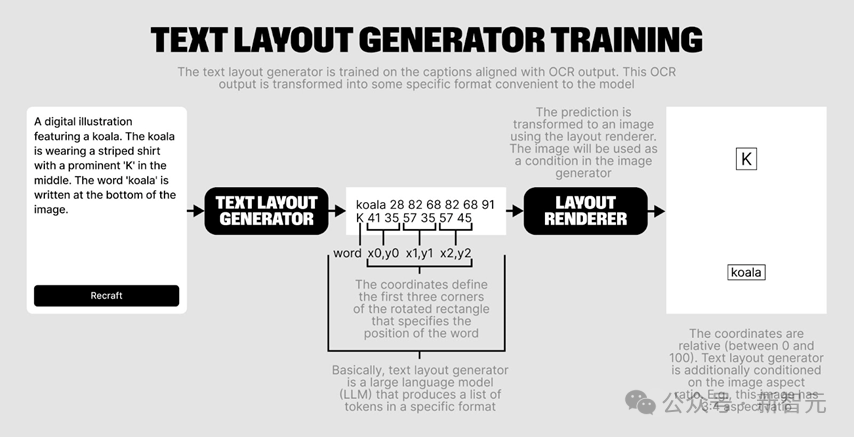
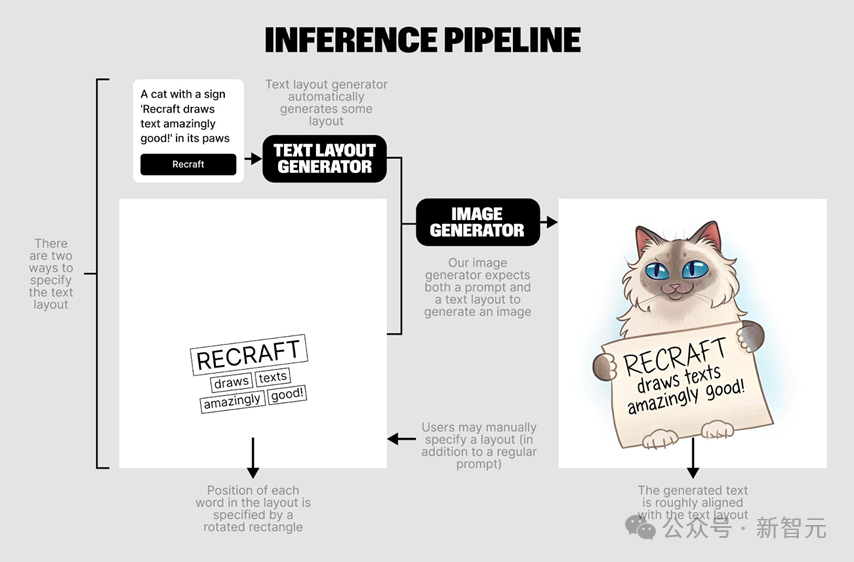
圖7 Recraft團隊採用TextDiffuser-2的表徵方式得到文本layout,並將其渲染為圖片作為condition進行圖像生成
由於Recraft團隊開放了測試接口,我對模型進行了一些測試,效果十分驚豔
 圖8 prompt: a cat holds a paper saying abcdefghijklmnopqrstuvwxyz
圖8 prompt: a cat holds a paper saying abcdefghijklmnopqrstuvwxyz 圖9 prompt: a graphic design with monkey music festival poster
圖9 prompt: a graphic design with monkey music festival poster
圖10 prompt: a girl in the left holds the paper saying hello and a boy in the right holds the paper saying world

圖11 prompt: On a rainy night, the lightning in the sky formed the shape of “hello.”
然而Recraft依然存在一些問題,例如模型儘管能支持中文prompt,但對於中文渲染不是特別好:
 圖12 prompt: 下雨的夜晚,天空中的閃電構成了「天空」兩個字
圖12 prompt: 下雨的夜晚,天空中的閃電構成了「天空」兩個字另外Recraft也很難渲染未明確指定的文本:

圖13 prompt: a man stands in front of a huge newspaper。可以發現小字部分的筆畫是扭曲的。
 圖14 prompt: keyboard。鍵盤上的文本是錯亂的。
圖14 prompt: keyboard。鍵盤上的文本是錯亂的。 圖15 prompt: ruler。刻度是錯亂的。
圖15 prompt: ruler。刻度是錯亂的。總之,文本渲染在文本生成圖像領域扮演了至關重要的角色,它不僅關係到圖像的視覺呈現,還影響到文本信息的準確傳達和語義理解。儘管近年來技術有了顯著的進步,但文本渲染依然面臨諸多挑戰,需要進一步的研究和改進。
參考資料:
https://www.recraft.ai/blog/how-to-create-sota-image-generation-with-text-recrafts-ml-team-insights
Chen J, Huang Y, Lv T, et al. Textdiffuser: Diffusion models as text painters. NeurIPS 2023.
Chen J, Huang Y, Lv T, et al. Textdiffuser-2: Unleashing the power of language models for text rendering. ECCV 2024. Huang M, Li H, Liu Y, et al.
Bridging the Gap Between End-to-End and Two-Step Text Spotting. CVPR 2024.