1000多個智能體組成,AI社會模擬器MATRIX-Gen助力大模型自我進化
AIxiv專欄是機器之心發佈學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯繫報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文作者來自於上海交通大學人工智能學院的Multi-Agent Governance & Intelligence Crew (MAGIC團隊)和牛津大學。共同第一作者有唐鑠、龐祥鶴、劉澤希和唐博瀚。指導老師包括上海交大的王延峰教授、陳思衡副教授,以及牛津大學的董曉文副教授。
隨著大語言模型(LLMs)在處理複雜任務中的廣泛應用,高質量數據的獲取變得尤為關鍵。為了確保模型能夠準確理解並執行用戶指令,模型必須依賴大量真實且多樣化的數據進行後訓練。然而,獲取此類數據往往伴隨著高昂的成本和數據稀缺性。因此,如何有效生成能夠反映現實需求的高質量合成數據,成為了當前亟需解決的核心挑戰。
那麼,真實數據的需求是如何產生的?設想一位程序員在進行機器學習模型的開發與調優時,他會提出問題:「如何調整超參數以提高模型預測準確率?」 這種指令並非憑空而來,而是源於他所處的具體工作情境 —— 數據分析和模型優化。同樣,用戶在日常生活中的指令無論是編程任務、醫療診斷還是商業決策,往往與他們所面臨的具體場景密切相關。要生成能夠真實反映用戶需求的合成數據,必須從這些實際情境中出發,模擬出與用戶需求相匹配的場景。
基於這一理念,上海交通大學與牛津大學的研究團隊提出了一項創新方案 —— 基於多智能體模擬的數據合成。團隊提出了 MATRIX——AI 社會模擬器,構建了一個由 1000 多個 AI 智能體組成的模擬社會。在這個模擬社會中,每一個 AI 智能體代表了一個擁有獨立身份和人格的數字人,這些 AI 智能體可以模擬出複雜的交流和互動模式,涵蓋了從軟件開發到商業活動的廣泛場景。基於這些場景,團隊進一步開發了 MATRIX-Gen 數據合成器,能夠根據不同需求合成高度多樣化且高質量的訓練指令數據。

-
論文鏈接:https://arxiv.org/pdf/2410.14251
-
代碼主頁:https://github.com/ShuoTang123/MATRIX-Gen
為驗證 MATRIX-Gen 合成數據的高質量,研究團隊使用 Llama-3-8B-Instruct 驅動社會模擬,僅合成了 2 萬條數據用於訓練 Llama-3-8B-Base 模型。儘管數據量極少,訓練後的模型在 AlpacaEval 2 和 Arena-Hard 基準測試中竟然大幅超越了 Llama-3-8B-Instruct 自身。這一結果不僅證明了 MATRIX-Gen 合成數據的高效性,也標誌著模型在合成數據驅動下實現了自我進化。此外,在代碼生成、多輪對話和安全性任務上,MATRIX-Gen 生成的專用數據同樣表現優異,甚至超越了為這些特定任務設計的專用數據集。這項研究為通過合成數據提升大語言模型性能提供了全新的解決方案,展示了 AI 模擬社會在數據合成中的巨大潛力,為未來大語言模型的後訓練數據合成開闢了創新的路徑。
基於合成數據的後訓練系統
本研究提出的後訓練系統旨在利用基於多智能體模擬技術構建的 AI 模擬社會,合成高質量的訓練數據,以提升預訓練大語言模型的指令跟隨能力。該系統的核心理念源於人類在現實場景中提問的方式 —— 人們基於自身需求提出多樣且深入的問題。因此,本研究通過 AI 模擬社會合成人類社會中的場景,並利用這些場景引導 LLM 提出信息豐富、貼近現實的問題,從而產生高質量的訓練數據。
如下圖所示,該系統包含三個步驟:

1. 合成社會場景:利用多智能體模擬技術構建 AI 模擬社會,該社會中的每個場景由一組 AI 智能體及其對應的文本行動構成。為了確保社會場景的真實性和多樣性,本研究設計了大規模人類社會模擬器 MATRIX,創建了一個包含各種 AI 智能體的互動環境。此模擬器充分發揮了 LLM 的角色扮演能力,使得 AI 智能體能夠逼真地模擬人類行為,進行規劃、觀察和行動,進而生成豐富且高度真實的社會場景。
2. 合成訓練數據:根據合成的社會場景,生成符合任務需求的後訓練數據。本研究設計了場景驅動的指令生成器 MATRIX-Gen,模擬人類在日常生活中提出問題的過程,結合場景生成指令,確保更高的真實性;通過選擇特定場景,能夠合成符合任務需求的數據,具備可控性。這一步驟合成包括 SFT、DPO 以及各種專用數據集。
3. 模型微調:利用合成的 SFT 數據集,對預訓練模型進行監督微調,以獲得具備指令跟隨能力的模型。隨後,基於合成的偏好數據集,採用 DPO 進一步訓練模型。
AI 社會模擬器 MATRIX
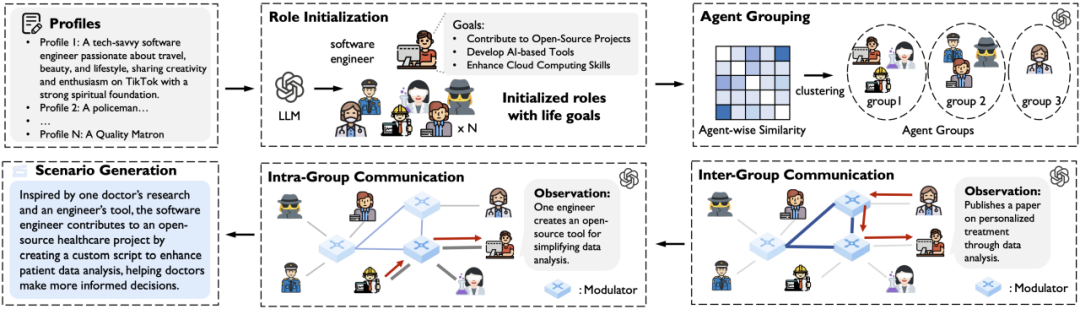
為了合成多樣且豐富的場景,以助力數據的合成,本研究提出了人類社會模擬器 MATRIX。該模擬器的輸入為若干 AI 智能體檔案,輸出為文本形式的場景。通過模擬人類的 AI 智能體和結構化的通信機制,MATRIX 實現了大規模的人類社會模擬,從而生成多樣且真實的場景。
-
模擬人類的智能體:每個 AI 智能體根據匿名化的真實人類檔案進行初始化,並由 LLM 生成其個性和人生目標。這些目標進一步分解為可執行的步驟,形成 AI 智能體的行動計劃。例如,一個醫學教授的生活目標可能包括傳播科學知識,而其計劃則包括進行研究、發表論文、進行講座和組織教育項目。這些步驟指導 AI 智能體未來的行動,確保它們朝著目標努力並展現出有目的的行為。當出現新觀察時,AI 智能體會根據其記憶和個性做出反應;在沒有新觀察的情況下,它們則遵循既定計劃追求目標。
-
結構化的通信機制:受人類社會中同質性現象的啟發,我們根據相似特徵對 AI 智能體進行分組,以減少不必要的連接,從而提高模擬的可擴展性。在每組中,本研究引入一個集中調節器來管理組內和組間的溝通。這一設計促進了相似 AI 智能體之間的更多互動,同時仍允許長距離交流,豐富信息流並增強真實性。此外,這種結構化通信機制能夠防止 AI 智能體接收到過多無關信息,確保模擬的有效性。
數據合成器 MATRIX-Gen
在合成了真實多樣化的社會場景後,本研究設計了場景驅動的指令生成器 MATRIX-Gen,以滿足特定任務需求併合成後訓練數據。通過選擇與用戶需求相關的場景,MATRIX-Gen 能夠生成符合人類意圖的指令,從而確保合成指令的真實性和可控性。
如下圖所示,在合成後訓練數據的過程中,MATRIX-Gen 模擬了人類提問的過程。針對不同數據場景的需求(如通用任務或代碼任務),MATRIX-Gen 結合每個 AI 智能體的個性和行動,將這些信息整合到指令生成提示中,模擬人類在日常生活中提出問題的方式。隨後,基於上述指令生成提示,MATRIX-Gen 直接調用對齊的 LLM 生成合成指令及其對應的回答。
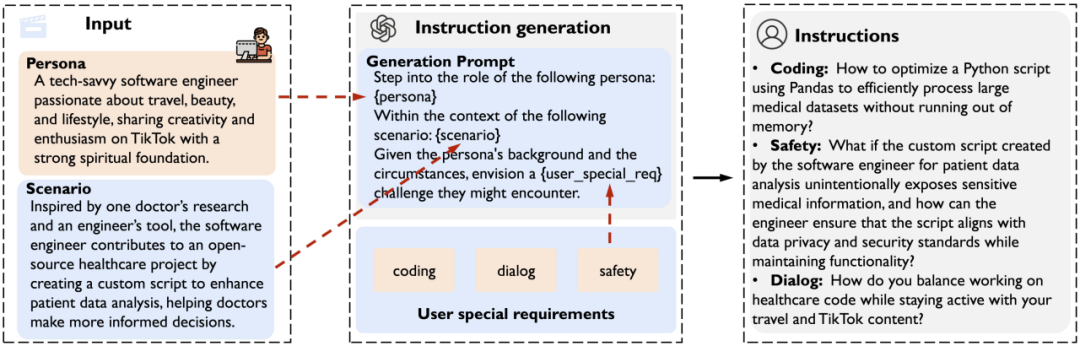
下圖展示了一位 IT 經理在汽車數據分析場景下,提出「如何調整超參數以提高模型預測準確率」的例子:

通過這一方法,本研究能夠合成三種類型的數據集,包括監督微調數據集 MATRIX-Gen-SFT、偏好調優數據集 MATRIX-Gen-DPO,以及特定領域的 SFT 數據。每種數據集的指令生成在複雜性和專業性上各具特點,確保滿足不同場景下的需求。
性能表現
在實驗中,本研究選擇 Llama-3-8B-Instruct 作為數據合成模型,選擇 Llama-3-8B 作為訓練的模型,通過模型的訓練效果評估 MATRIX-Gen 在通用任務、多輪對話、代碼生成上的數據合成能力。
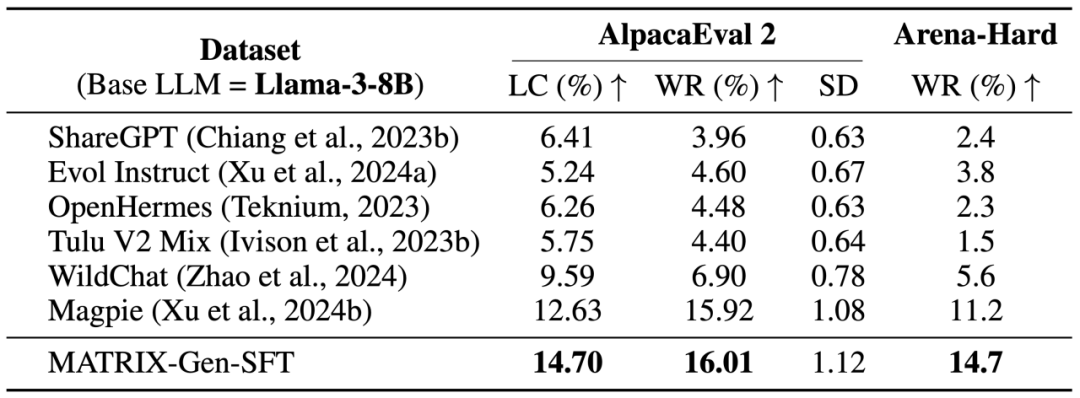
AlpacaEval 2 和 Arena-Hard 上的評估結果表明,通過多智能體模擬合成的 MATRIX-Gen-SFT 數據優於多個真實數據集以及合成數據集。
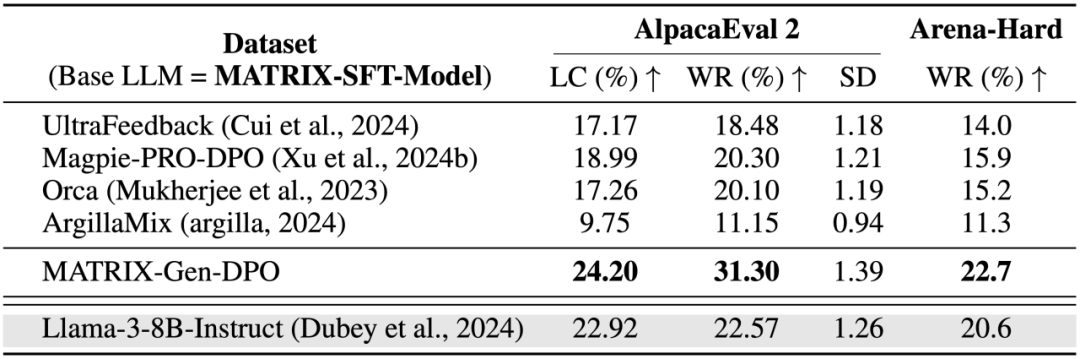
在 MATRIX-SFT 模型上 DPO 的訓練結果表明,通過 MATRIX-Gen-DPO 訓練的模型超越多種合成偏好數據訓練的模型,以及 Llama-3-8B-Instruct。值得注意的是,MATRIX-Gen-DPO 訓練後的模型總共僅使用了 2 萬條合成數據,便實現了對 Llama-3-8B-Instruct 自身的超越,充分展示了其高質量和自我進化的能力。
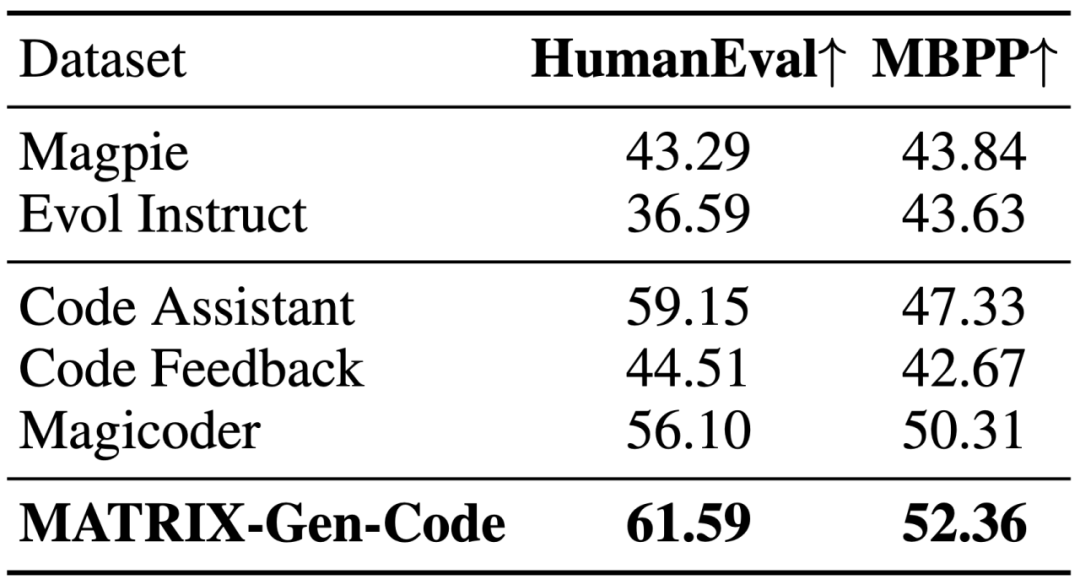
在代碼生成與安全輸出的任務中,MATRIX-Gen 合成的數據集均超越了對應領域的專用數據集,顯示出 MATRIX-Gen 在合成數據上的高可控性。
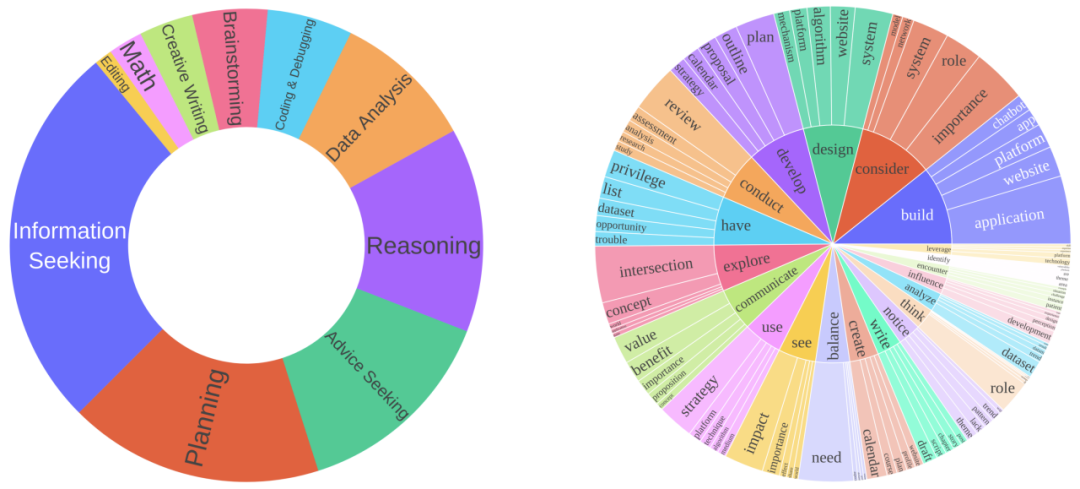
上圖展示了 MATRIX-Gen-SFT 合成指令的可視化,顯示出合成數據的多樣性。
總結與展望
本研究提出了一種基於 AI 智能體社會模擬的後訓練數據合成框架。依託 MATRIX 合成的 AI 模擬社會,MATRIX-Gen 能夠可控地合成高質量的多樣數據。在通用和專用任務中,僅使用 0.2% 的數據,即可獲得優於大模型研發領軍團隊 Meta AI 所用數據集的模型訓練效果,突顯了 MATRIX-Gen 在數據合成中的優勢。
本研究希望該數據合成框架能夠幫助定量研究何種類型的數據更適合用於監督微調和偏好優化,深入探討不同數據特性對模型性能的影響。此外,我們展望通過引入更強大的 AI 智能體,如具備工具調用能力的 AI 智能體,以及接入更豐富的環境,進一步合成更複雜的數據,從而提升大語言模型在複雜任務中的表現。



















